欢迎来到夜宇工作间
这里是我的个人IT学习回忆录-
Kafka基础原理
配置项
zookeeper.connect
kafka 使用 zookeeper 来保存生产者和topic元数据,消费者元数据、分区偏移量
通过
zookeeper.connect可以指定 kafka 使用的 zookeeper 的ip及端口,以及用来存储元数据的地址。格式是:ip:host/path如果不指定 path,会默认使用根路径。如果指定的 path不存在,在启动 broker 时会创建它。在实际使用时,最好指定 path。因为 zookeeper 集群可能给不同的服务使用,通过 path 能进行很好的区分。如果有不同的 kafka 集群都连这个 zookeeper,通过 path 区分就不会出现冲突。
log.dirs
kafka 将消息存在本地磁盘上。log.dirs 用来指定消息存放的路径。可以通过逗号分隔,指定多个路径。如果指定了多个路径,broker 会采用【最少使用原则】,将同一分区的内容保存在同一路径下。
broker 会往拥有最少数量分区的路径新增分区,而不是往磁盘空间最小的路径新增分区
默认情况下,kafka会在三种动作下自动创建 topic:
- 任意一个客户端向 topic 发送元数据
- 一个生产者往 topic 写数据时
- 一个消费者从 topic 取数据时
如果要关闭这个默认动作,需要手动显式的去创建 topic,需要把配置文件中
auto.create.topics.enable设置为 falsenum.partitions
num.partitions指定新创建的 topic 包含多少个分区。如果topic的自动创建功能(
auto.create.topics.enable)是打开的。它会创建num.partions数量的分区。该值默认是 1。我们可以增加分区的数量,但不能减少。比如,
num.partions设置为 3。在后序的使用中,我们可以把该值改成 4,但不能改成 2.在使用中,是通过分区数进行横向扩展的。当有新的 broker 加入集群时,可以增加分区数量来实际负载均衡。具体一个 topic 需要多少个分区,需要根据实际需要的吞量来进行估算:
- 一个分区和般会有一个消费者
- 假如消费者 1 秒可以处理 100 条数据。生产者 1 秒存入 1000 条数据
- 那么,就需要 10 个消费者。也就是说,要 10 个分区。
log.retention
log.retention 控制 kafka 将消费保存多久。有三个值可以指定,即:
log.retention.hour,log.retention.minutes,log.retention.ms默认是 168 小时。这三个参数的作用是一样的。但如果这三个参数都设置了值,kafka 会优先使用最小的那个时间。
除了通过时间来控制消息保存的时间,还可以通过
log.retention.bytes来实现保存一定数量的数据。该值应用到每个分区上。比如:有8个分区,该
log.retention.bytes的值设置为 1G。那么,最多能保存 8G 的数据。如果要扩展,就要通过增加分区的形式来实现。log.segment
一个消息到达 broker 时,它会被追加到分区当前的文件中。当文件大小到达
log.segment.bytes时(该值默认 1G),文件会被关闭,然后打开一个新的文件。 被关闭的文件就开始等待过期,过期的动作受到 log.retention 的影响。即:过期时间和过期大小。log.segment.bytes这个值设置的越小,关闭文件、打开文件操作会越频繁,这会损耗性能影响效率。如果一个 topic一天接收 100MB 的数据,
log.segment.bytes的值是 1G。那么,需要 10 天才会关闭这个文件。过期时间设置的是 7 天,【文件在关闭前是不会过期的,在关闭后才开始计时关闭】。所以,这里的消息要 17 天才会过期。【文件中最后一条消息过期后,文件才真正过期,这时候文件会被删除】。这里的值,可以用来评估需要多大的磁盘空间。
除了通过
log.segment.bytes的大小值来控制文件的关闭,还可以通过时间来周期性的关闭。即:log.segment.ms。这两个条件,哪个先满足,就执行文件关闭。所以不会出现互斥的情况。默认情况下是只使用 log.segment.bytes 来进行。
message.max.bytes
message.max.bytes 限制了单个消息的大小。如果超过这个值,kafka 会拒收,同时返回错误信息。默认值是 1MB,该大小是指压缩后的大小,实际的大小可能远大于该值。
该值越大,处理网络连接、磁盘写入等就会消耗越多的性能。所以,kafka 不太建议用来做很大单条数据的处理,推荐用来做小而快的消息处理。
与该值匹配的还有另外一个值:
fetch.message.max.bytes,它是消费端能获取的消息的最大值。如果该值设置小了,就会导致消费端消费不及时。生产调优
MaxGCPauseMillis每次垃圾回收暂停时间。默认是 200ms。InitiaingHeapOccupancyPercent回收前可使用堆的百分比。默认 45%。即:在堆内存使用达到 45% 前不会进行垃圾回收。Kafka 对堆内存使用率非常高,容易产生垃圾对象。所以可以把这两个值设置的稍小一点。尽早进行垃圾回收。如:200ms, 35%
broker 写入数据
kafka 使用 zookeeper 来维护集群各成员的信息。每个 broker 都有一个唯一的标识符,这个标识可以在配置文件中指定,也可以自动生成。启动 broker 时,它通过创建临时节点把自己的ID注册到 Zookeeper 上。Kafka 各组件监听Zookeeper 的
/brokers/ids(在配置文件中配置的路径)。当有 broker 加入集群或退出集群时,各组件就会获得通知。如果有 broker 的ID重复,启动时会报错,因为在 Zookeeper 上创建同名节点是不会成功的。消息写入时,我们先创建 ProducerRecord 对象。它包含了目标topic、分区(可不配置)、键(可不配置)、要发送的内容。数据被发送给【分区器】。如果配置了分区,分区器则不会任何处理。有了分区,生产者就知道往哪个 topic 和分区写入。接着,数据被添加到一个消息批次里,这个批次里的消息会被发到同一个 topic 和分区里。会有专门的线程把这些消息发送到对应的 broker 里。
服务器收到这些消息时会返回一个响应。如果成功写入 Kafka,会返回一个 RecordMetaData 对象,它包含 topic 和分区信息,以及数据在分区里的偏移量。如果写入失败,则会返回一个错误。生产者在收到错误后会重试 N 次,重试后还是失败,则会返回错误信息。
生产者
要往 Kafka 写入消息,需要创建 Kafka 对象,并设置一些属性。三个必填的参数分别是:
bootstrap.servers。指定 broker 的清单,格式为:host:port,多个 broker 之间用逗号分隔。生产者会从一个 broker 里获取到其它所有 broker 的信息。但为了防止提供的 broker 挂掉了。所以最好是提供两个 broker 信息。key.serializer。键的序列化类。因为 broker 希望接收到的消息都是字节数组。所以要进行序列化。默认提供了常见类型的序列化类。如:String, Integer 。value.serializer。值的序列化器。如果 key 和 value 同类型,可以使用相同的序列化类。如果不同,则要分别配置不同的。
发送消息时,可以用三种方式发送:
- 同步发送。发送后进行等待结果返回。
- 异步发送。发送时指定一个回调函数。无须等待。
- 发送并忘记。发送后不做其它处理。这样可能会丢失数据。
分区
Kafka 的基本存储单元是分区,分区无法在多个 broker 间再细分,也无法在同一个 broker 的多个磁盘上细分。所以,分区的大小受到单个挂载点可用空间的限制。
Kafka 的消息是一个个键值对。在 ProducerRecord 对象里,键的值可以为空。但最好是配置上。它可以决定这个数据被存在哪个分区。拥有相同键的消息会被发送到同一个分区。
如果键的值为 null,且使用了默认的分区器。Kafka 会将记录随机发送到各个可用的分区上。
如果键值不为 null,且使用默认分区器。Kafka会对键进行散列(使用自己的散列算法)。散列算法会把所有的分区都用上,不管这个分区是否有问题。那么,如果散列到的分区不可用。会出问题。因为:相同键值的信息会发送到同一个分区
除了使用默认的分区器外,还可以自定义实现分区器。需要自己实现
Partitioner接口。参数配置
acks
指定了需要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。 如果 acks = 0,表示不做判断,这种处理的吞吐量最大。 如果 acks = 1,表示只要 master 接收到了就认为成功了。 如果 acks = all,表示所有参与复制的节点全部收到消息才会认为成功,这时候才会返回客户端成功的标识。
buffer.memory
生产者内存缓冲区的大小,用来缓冲要发送到服务器的消息。如果应用程序send()消息的速度超过发送到服务器的速度,导致配置的缓冲区空间不足。这时候 send() 会被阻塞。
compression.type
默认情况下,消息发送时不会被压缩。该参数可以配置压缩算法,如:snappy、gzip、lz4。 使用压缩算法后,可以降低网络传输开销和存储开销,但会损耗性能。 snappy占用较少的CPU,提供较好的性能和可观的压缩比。gzip 战胜较多的CPU,提供更高的压缩比。
retries
生产者发消息时,如果收到错误信息,会重试。这个参数就配置了重试的次数。每次重试之间会等待 100ms。也可以通过
retry.backoff.ms来改变该值。重试次数达到,如果还没成功,就会返回错误。batch.size
如果多个消息要被发送到同一个分区,生产者会把它们放在同一批次里一起提交。这个参数指定了一个批次可以使用的内存大小。嫁到字节计算,不是消息个数。如果设置的太大,消息会有延迟。如果太小,又会增加一些额外的开销。
linger.ms
除了通过批次内存大小来控制批量提交的行为。还可以通过时间来控制。当 linger.ms 时间达到时,也会触发提交的动作。
client.id
唯一识别码。各个broker不要重复
max.in.flight.requests.per.connection
指定生产者在收到服务器响应之前可以发送多少个消息。如果设置成很大的值,就可以实现异步的效果,提升吞量,占用更多的内存。如果设置为 1,可以保证消息是按发送的顺序写入的。
max.request.size
发送请求的大小。如果是批量提交,这整个批次的数据大小加起来不能超过该值
consumer 消费数据
消费者和消费者群组
消费者用来从 topic 订阅、读取并消费数据。但实际中一个消费者往往跟不上生产者的速度,所以需要用一组消费者消费同一个 topic 的消息。这就是消费者群组。
Kafka的消费者属于一个消费者群组。一个群组里的消费者访问相同 topic 的消息。每个消费者接收该 topic 一部分分区的消息。
如果消费者的数量等于分区的数量。每个消费者会被分配一个分区。
如果消费者的数量大于分区的数量。有的消费者会闲置。
如果我们创建多个群组消费同一 topic。每个群组都会接收到全量的消息。那么,我们就可以在业务上将一串复杂的逻辑处理拆分成多个小的处理。交给多个群组来并行处理。当然,前提是这些逻辑处理是没有顺序依赖的。
当群组里添加或减少消费者时,群组会进行再均衡,重新分配分区。在重新分配期间,所有消费者是不可用的。这会影响效率。
消费者通过向被指派为群组协调器的 broker 发送心跳来维持状态。如果超出时间未发送心跳,协调器会认为该消费者已经挂掉,这时候会进行再均衡。
创建消费者
通过创建 KafkaConsumer 对象来创建消费者。它和生产者非常类似,也有几个必填参数:
bootstrap.servers。指定 broker 的清单,格式为:host:port,多个 broker 之间用逗号分隔。生产者会从一个 broker 里获取到其它所有 broker 的信息。但为了防止提供的 broker 挂掉了。所以最好是提供两个 broker 信息。key.serializer。键的序列化类。因为 broker 希望接收到的消息都是字节数组。所以要进行序列化。默认提供了常见类型的序列化类。如:String, Integer 。value.serializer。值的序列化器。如果 key 和 value 同类型,可以使用相同的序列化类。如果不同,则要分别配置不同的。group.id。用来表明消费者是属于哪个消费群组。
订阅topic
创建完消费者后,可以订阅某个或多个 topic 了。也可以在订阅时传入一个正则表达式。如果有人创建了新的 topic,且符合该正则,那会立即触发一次再均衡。
轮询
消息轮询是消费者处理的核心。消费者订阅主题后,轮询就会处理所有的细节。如:群组协调、再均衡、发送心跳、获取数据。如:
try{ // 不停轮询 while(true){ // 不停的从 kafka 取数据,否则kafka会认为该消费者挂掉,然后从群组去除它 ConsumerRecords<String, String> records = consumer.poll(100); // 遍历取到的值,值里面包括了 topic、分区、偏移量、键值对 for(ConsumerRecords<String, String> record : records){ // TODO: 获取各值并进行逻辑处理 String loopTopic = record.topic(); String loopPartition = record.partition(); String loopOffset = record.offset(); String loopKey = record.key(); String loopValue = record.value(); } } }finally{ // 关闭消费者.此时会触发再均衡 consumer.close(); }提交和偏移量
在轮询中,每次调用
poll()方法,它返回的总是被写入 kafka 但还没被消费者读取过的消息。那么,我们就需要知道哪些消息是被消费过的。消费者消费一条消息后,都需要向 kafka 更新一下分区的偏移量信息,表示数据已经被消费到这里了。下次就返回后面未消费过的数据给消费者。这个过程叫提交kafka 会往一个叫
consumer_offset的主题发送消息。消息里包括了每个分区的偏移量。如果消费者一直在 poll(),它会直接从分区一直取数据。不会读取该主题的内容。但如果发生了再均衡(有消费者挂掉或有新的消费者加入)。消费者可能会被分配到新的分区,它就需要从该主题中获取偏移量,否则它不知道从哪个位置开始读取消息。如果消费者未及时提交偏移量或者提交失败,这时候就会有问题了。自动提交
最简单的方案就是让消费端自动提交。这需要把配置文件中的
enable.auto.commit设置为 true。这时,每过 5秒,消费者会自动把 poll()方法接收到的最大偏移量提交上去。这个 5s是受配置文件中auto.commit.interval.ms控制的,默认值是 5秒。在轮询时,每次都会先检查是否需要提交了。如果达到提交要求,会先把上次轮询的最大偏移量先提交,然后再 poll()。自动提交的问题是,它只能定期提交。在两次提交之间,如果发生故障,导致一部分消息消费了但还没来得及提交。再均衡后,就会重复消费一部分数据。这种场景不能完全避免,只能通过减少提交间隔来缓解,另外需要业务上做重复性校验
提交当前偏移量
为了避免定期提交带来的问题,也可以手动进行提交。在每次 poll() 及逻辑处理完毕后,手动提交一次:
try{ consumer.commitSync(); }catch(CommitFailedException e){ log.error("offset commit error: ", e); }使用手动提交时,要将配置文件中的
enable.auto.commit设置为 false。手动提交会在失败时自动重复尝试,直到成功。如果发生异常,我们可以进行异常捕获,记录日志异步提交
手动提交有个劣势就是:在提交时,程序会阻塞。这会减少程序的吞吐量。这时候可以使用异步提交:
consumer.commitAsync();异步提交的问题在于,无法保证顺序。特别是在并发时,一个请求发送了 2000 的偏移量,服务端由于网络原因未收到,但另外一个请求发送了 3000 。这时候 2000 的请求成功了,就会覆盖 3000。如果再均衡,就会重复消费了。
组合提交
为了确保能够成功提交。可以采用如下方式:
try{ // TODO: 逻辑处理 consumer.commitAsync(); }catch(Exception e){ log.error("Offset Commit Error!", e); }finally{ try{ consumer.commitSync(); }finally{ consumer.close(); } }提交特定偏移量
通常,提交偏移量的频率和处理消息批次的频率是一样的。但如果一次 poll() 获取了大量的数据,为了避免因再均衡引起重复处理的问题,需要在批次中间处理的时候就提交偏移量。还有一种情况:一个消费者要处理不同分区的数据,提交的时候要分别提交:
private Map<TopicPartition, OffsetAndMetadata> nowOffsets = new HashMap<>(); int count = 0; while(true){ ConsumerRecords<String, String> records = consumer.poll(100); // 不同分区的偏移量分别保存 for(ConsumerRecord<String, String> record : records){ nowOffsets.put(new TopicPartition(record,topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata") ); // 每处理 1000 条消息,提交一次 if(count % 1000 == 0){ consumer.commitAsync(nowOffsets, null); } count++; } }再均衡监听
消费者在退出和进行分区再均衡前,会做一些清理工作。所以,各个消费者一定要及时提交最后一个处理记录的偏移量。
所以,需要各个消费者监听分区动作。及时提交最后处理记录的偏移量。这里,需要我们实现
ConsumerRebalanceListener接口,在轮询中订阅该主题。并填充相应的逻辑。private Map<TopicPartition, OffsetAndMetadata> nowOffsets = new HashMap<>(); private class HandleRebalance implements ConsumerRebalanceListener{ public void onPartitionsAssigned(Collection<TopicPartition> partitions){} public void onPartitionsRevoked(Collection<TopicPartition> partitions){ consumer.commitSync(nowOffsets); } } try{ consumer.subscribe(topics, new HandleRebalance()); while(true){ ConsumerRecords<String, String> records = consumer.poll(100); // 不同分区的偏移量分别保存 for(ConsumerRecord<String, String> record : records){ nowOffsets.put(new TopicPartition(record,topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1, "no metadata") ); // 每处理 1000 条消息,提交一次 if(count % 1000 == 0){ consumer.commitAsync(nowOffsets, null); } count++; } } }catch(Exception e){ log.error("Offset Commit Error!", e); }finally{ try{ consumer.commitSync(nowOffsets); }finally{ consumer.close(); } }从特定偏移量读取
consumer.seek(partition, xxx); ```
退出消费
如果想要让某消费者退出轮询。可以在外部再执行一个程序,调用
consumer.wakeup()。参数配置
fetch.min.bytes
消费者从服务器获取记录的最小字节数。broker 收到消费者的数据请求时,如果可用数据量小于配置的值,它会等到有足够的可用数据再返回。这会降低工作负载。
fetch.max.wait.ms
配置 broker 的等待时间。如果broker等一定的时间后,还是没有足够的数据。则会直接将当前可用的数据返回给客户端。
max.partition.fetch.bytes
服务器从每个分区里返回给消费者的最大字节数。默认值是1MB。也就是说: poll() 方法返回的数据总量不会超过该配置的值。
session.timeout.ms
指定消费者在被认为死亡前可以与服务器断开连接的最长时间。默认是 3S。如果在该时间内未向群组协调器发送心跳,就会被认为死亡,这时候会进行再均衡。
heartbeat.interval.ms表示多久向协调器发送一次心跳。所以,该值要小于 timeout 的值。auto.offset.reset
指定消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该做何处理。默认值是 latest表示从最新的记录开始读取。earliest表示从起始位置读取。
enable.auto.commit
是否自动提交偏移量,通常把它设置为 false,然后在程序中自己控制提交。
partition.assignment.strategy
将分区分配给消费者时采用的策略。有两个选项:
- Range。将连续的分区分配给消费者。如果有两个消费者,C1,C2同时订阅两个主题T1,T2。每个主题都有 3 个分区。这时候分区分配可能是:C1 分配 T1 和 T2的1,2分区。C2分配到T1,T2的3分区。因为它会将连接的分区分给同一个消费者。如果分区个数是奇数,就会造成这种不一致。
- RoundRobin。把所有的分区逐个分配给消费者。同上场景,分配情况可能是:C1分到T1的1分区,C2分到2分区,C1再分到3分区。这样逐个分配。
数据复制、选举
复制功能是 Kafka 可用性的核心。它可以在个别节点失效时仍能保证集群的可用性和持久性。
Kafka 使用 topic 来组织数据。每个 topic 被分为若干个分区,每个分区有 N 个副本(可配置)。这些副本被保存在各个 broker 上,每个 broker 可以保存成百上千个不同 topic 和分区的副本。
副本有两种:master 和 slaver。为了保证数据的一致性,所有生产者和消费者的请求都会经过 master 副本。除 master 副本之外的,都是 slaver ,它们不响应来自客户端的请求,它们唯一的任务就是接收来自 master 的复制消息,保持和 master 的一致。如果 master 崩溃,会从 slaver 中选取一个作为新的 master。
master 另一个重要的任务就是弄清楚哪些 slaver 是和自己一致的。slaver 为了和 master 保持一致,在有新消息到达 master 时会尝试去复制消息。这种请求和客户端消费数据是一样的,master 将响应返回给 slaver。master 通过请求的偏移量是不是最新的值来判断 slaver 是否和自己一致。
把消息写入多个副本可以使得 Kafka 在崩溃时仍能保证消息的持久性。Kafka 的主题被分为多个分区,分区是基本的数据块。分区存储在单个磁盘上,kafka可以保证分区里的消息是有序的。每个分区有多个副本,一个是 master,其它是 slaver。
对于 slaver 来说,怎么判定它和 master 是同步的。有几个标准:
- 和 Zookeeper 之间有活跃的对话:在过去的 6s(可配置)内向 zk 发送过心跳
- 在过去 10s(可配置)从 master 获取过消息
- 在过去 10s从master获取过最新的消息,且几乎零延迟
-
分布式疑点
为什么要将系统进行拆分?
要是不拆分,一个大系统几十万行代码,20 个人维护一份代码,很头疼。代码经常改着改着就冲突了,各种代码冲突和合并要处理,非常耗费时间;经常我改动了我的代码,你调用了我的,导致你的代码也得重新测试;然后每次发布都是几十万行代码的系统一起发布,大家得一起提心吊胆准备上线,上线都要做很多的检查,很多异常问题的处理;而且如果我现在打算把某些组件升级到新的版本,可能导致你的代码报错,我不敢随意乱改技术。
假设一个系统是 20 万行代码,其中 A 在里面改了 1000 行代码,但是此时发布的时候是这个 20 万行代码的大系统一块儿发布。就意味着 20 万上代码在线上就可能出现各种变化,20 个人,每个人都要紧张地等在电脑面前,上线之后,检查日志,看自己负责的那一块儿有没有什么问题。
A 就检查了自己负责的 1 万行代码对应的功能,确保 ok 就闪人了;结果不巧的是,A 上线的时候不小心修改了线上机器的某个配置,导致另外 B 和 C 负责的 2 万行代码对应的一些功能,出错了。
几十个人负责维护一个几十万行代码的单块应用,每次上线,准备几个礼拜,上线 -> 部署 -> 检查自己负责的功能。
拆分了以后,几十万行代码的系统,拆分成 20 个服务,平均每个服务就 1~2 万行代码,每个服务部署到单独的机器上。20 个工程,20 个 git 代码仓库,20 个开发人员,每个人维护自己的那个服务就可以了,是自己独立的代码,跟别人没关系。再也没有代码冲突了。每次就测试我自己的代码就可以了。每次就发布我自己的一个小服务就可以了。技术上想怎么升级就怎么升级,保持接口不变就可以了。
所以简单来说,如果是那种代码量多达几十万行的中大型项目,团队里有几十个人,那么如果不拆分系统,开发效率极其低下。但是拆分系统之后,每个人就负责自己的一小部分就好了。分布式系统拆分之后,可以大幅度提升复杂系统大型团队的开发效率。
但是同时,也要提醒的一点是,系统拆分成分布式系统之后,大量的分布式系统面临的问题也是接踵而来。
如何进行系统拆分?
系统拆分为分布式系统,拆成多个服务,拆成微服务的架构,是需要拆很多轮的。并不是说上来一个架构师一次就给拆好了,而以后都不用拆。
第一轮;团队继续扩大,拆好的某个服务,刚开始是 1 个人维护 1 万行代码,后来业务系统越来越复杂,这个服务是 10 万行代码,5 个人;
第二轮,1 个服务 -> 5 个服务,每个服务 2 万行代码,每人负责一个服务。
如果是多人维护一个服务,最理想的情况下,几十个人,1 个人负责 1 个或 2~3 个服务;
大部分的系统,是要进行多轮拆分的,第一次拆分,可能就是将以前的多个模块该拆分开来了,比如说将电商系统拆分成订单系统、商品系统、采购系统、仓储系统、用户系统,等等。
但是后面可能每个系统又变得越来越复杂了,比如说采购系统里面又分成了供应商管理系统、采购单管理系统,订单系统又拆分成了购物车系统、价格系统、订单管理系统。
核心意思就是根据情况,先拆分一轮,后面如果系统更复杂了,可以继续分拆。
分布式服务接口的幂等性如何设计
假如有个服务提供一些接口供外部调用,这个服务部署在了 5 台机器上,接着有个付款接口,用户在前端上操作的时候,不知为何,一个订单不小心发起了两次支付请求,然后这俩请求分散在了这个服务部署的不同的机器上,结果是一个订单扣款扣两次。
或者是订单系统调用支付系统进行支付,结果不小心因为网络超时,订单系统走了重试机制,支付系统收到一个支付请求两次,而且因为负载均衡算法落在了不同的机器上,就又出现了重复扣款。
这个不是技术问题,这个没有通用的一个方法,这个应该结合业务来保证幂等性。
所谓幂等性,就是说一个接口,多次发起同一个请求,接口得保证结果是准确的,比如不能多扣款、不能多插入一条数据、不能将统计值多加了 1。这就是幂等性。
其实保证幂等性主要是三点:
- 对于每个请求必须有一个唯一的标识,举例:订单支付请求,肯定得包含订单 id,一个订单 id 最多支付一次。
- 每次处理完请求后,必须有一个记录标识这个请求处理过了。常见的方案是在 mysql 中记录个状态,比如支付之前记录一条这个订单的支付流水。
- 每次接收请求需要进行判断,判断之前是否处理过。比如说,如果有一个订单已经支付了,就已经有了一条支付流水,那么如果重复发送这个请求,此时先插入支付流水,orderId 已经存在了,唯一键约束生效,报错插入不进去,就不用再扣款了。
实际运作过程中,要结合自己的业务,比如说利用 Redis,用 orderId 作为唯一键。只有成功插入这个支付流水,才可以执行实际的支付扣款。
分布式服务接口请求的顺序性如何保证
分布式系统接口的调用顺序,一般来说是不用保证顺序的。但是有时候可能确实是需要严格的顺序保证。给大家举个例子,服务 A 调用服务 B,先插入再删除。结果俩请求过去了,落在不同机器上,可能插入请求因为某些原因执行慢了一些,导致删除请求先执行了,此时因为没数据所以什么效果也没有;结果这个时候插入请求过来了,数据插入进去了,最终结果肯定不对。
这都是分布式系统一些很常见的问题。从业务逻辑上设计的这个系统最好是不需要这种顺序性的保证,因为一旦引入顺序性保障,比如使用分布式锁,会导致系统复杂度上升,而且会带来效率低下,热点数据压力过大等问题。
CAP 架构理论
什么是 CAP 定理(CAP theorem)
在理论计算机科学中,CAP 定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Partition tolerance)(分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在 C 和 A 之间做出选择。)
分区容错性(Partition tolerance)
理解 CAP 理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了 C 性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了 A 性质。除非两个节点可以互相通信,才能既保证 C 又保证 A,这又会导致丧失 P 性质。
- P 指的是分区容错性,分区现象产生后需要容错,容错是指在 A 与 C 之间选择。如果分布式系统没有分区现象(没有出现不一致不可用情况) 本身就没有分区 ,既然没有分区则就更没有分区容错性 P。
- 无论设计的系统是 AP 还是 CP 系统如果没有出现不一致不可用。 则该系统就处于 CA 状态
- P 的体现前提是得有分区情况存在
几个常用的 CAP 框架对比
框架 所属 Eureka AP Zookeeper CP Consul CP Eureka
Eureka 保证了可用性,实现最终一致性。
Eureka 所有节点都是平等的所有数据都是相同的,且 Eureka 可以相互交叉注册。
Eureka client 使用内置轮询负载均衡器去注册,有一个检测间隔时间,如果在一定时间内没有收到心跳,才会移除该节点注册信息;如果客户端发现当前 Eureka 不可用,会切换到其他的节点,如果所有的 Eureka 都跪了,Eureka client 会使用最后一次数据作为本地缓存;所以以上的每种设计都是他不具备一致性的特性。注意:因为 Eureka AP 的特性和请求间隔同步机制,在服务更新时候一般会手动通过 Eureka 的 api 把当前服务状态设置为
offline,并等待 2 个同步间隔后重新启动,这样就能保证服务更新节点对整体系统的影响Zookeeper
强一致性
Zookeeper 在选举 leader 时会停止服务,只有成功选举 leader 成功后才能提供服务,选举时间较长;内部使用 paxos 选举投票机制,只有获取半数以上的投票才能成为 leader,否则重新投票,所以部署的时候最好集群节点不小于 3 的奇数个(但是谁能保证跪掉后节点也是基数个呢);Zookeeper 健康检查一般是使用 tcp 长链接,在内部网络抖动时或者对应节点阻塞时候都会变成不可用,这里还是比较危险的;
Consul
和 Zookeeper 一样数据 CP
Consul 注册时候只有过半的节点都写入成功才认为注册成功;leader 挂掉时,重新选举期间整个 Consul 不可用,保证了强一致性但牺牲了可用性
有很多 blog 说 Consul 属于 ap,官方已经确认他为 CP 机制 原文地址:https://www.consul.io/docs/intro/vs/serf分布式锁
Redis 分布式锁
官方叫做
RedLock算法,是 Redis 官方支持的分布式锁算法。这个分布式锁有 3 个重要的考量点:
- 互斥(只能有一个客户端获取锁)
- 不能死锁
- 容错(只要大部分 Redis 节点创建了这把锁就可以)
Redis 最普通的分布式锁
第一个最普通的实现方式,就是在 Redis 里使用
SET key value [EX seconds] [PX milliseconds] NX创建一个 key,这样就算加锁。其中:NX:表示只有key不存在的时候才会设置成功,如果此时 redis 中存在这个key,那么设置失败,返回nil。EX seconds:设置key的过期时间,精确到秒级。意思是seconds秒后锁自动释放,别人创建的时候如果发现已经有了就不能加锁了。PX milliseconds:同样是设置key的过期时间,精确到毫秒级。
比如执行以下命令:
SET resource_name my_random_value PX 30000 NX释放锁就是删除 key ,但是一般可以用
lua脚本删除,判断 value 一样才删除:-- 删除锁的时候,找到 key 对应的 value,跟自己传过去的 value 做比较,如果是一样的才删除。 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end为啥要用
random_value随机值呢?因为如果某个客户端获取到了锁,但是阻塞了很长时间才执行完,比如说超过了 30s,此时可能已经自动释放锁了,此时可能别的客户端已经获取到了这个锁,要是你这个时候直接删除 key 的话会有问题,所以得用随机值加上面的lua脚本来释放锁。但是这样是肯定不行的。因为如果是普通的 Redis 单实例,那就是单点故障。或者是 Redis 普通主从,那 Redis 主从异步复制,如果主节点挂了(key 就没有了),key 还没同步到从节点,此时从节点切换为主节点,别人就可以 set key,从而拿到锁。
RedLock 算法
这个场景是假设有一个 Redis cluster,有 5 个 Redis master 实例。然后执行如下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒;
- 跟上面类似,轮流尝试在每个 master 节点上创建锁,超时时间较短,一般就几十毫秒(客户端为了获取锁而使用的超时时间比自动释放锁的总时间要小。例如,如果自动释放时间是 10 秒,那么超时时间可能在
5~50毫秒范围内); - 尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点
n / 2 + 1; - 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了;
- 要是锁建立失败了,那么就依次之前建立过的锁删除;
- 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。
Redis 官方给出了以上两种基于 Redis 实现分布式锁的方法,详细说明可以查看:https://redis.io/topics/distlock 。
zk 分布式锁
zk 分布式锁,其实可以做的比较简单,就是某个节点尝试创建临时 znode,此时创建成功了就获取了这个锁;这个时候别的客户端来创建锁会失败,只能注册个监听器监听这个锁。释放锁就是删除这个 znode,一旦释放掉就会通知客户端,然后有一个等待着的客户端就可以再次重新加锁。
/** * ZooKeeperSession */ public class ZooKeeperSession { private static CountDownLatch connectedSemaphore = new CountDownLatch(1); private ZooKeeper zookeeper; private CountDownLatch latch; public ZooKeeperSession() { try { this.zookeeper = new ZooKeeper("192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181", 50000, new ZooKeeperWatcher()); try { connectedSemaphore.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("ZooKeeper session established......"); } catch (Exception e) { e.printStackTrace(); } } /** * 获取分布式锁 * * @param productId */ public Boolean acquireDistributedLock(Long productId) { String path = "/product-lock-" + productId; try { zookeeper.create(path, "".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); return true; } catch (Exception e) { while (true) { try { // 相当于是给node注册一个监听器,去看看这个监听器是否存在 Stat stat = zk.exists(path, true); if (stat != null) { this.latch = new CountDownLatch(1); this.latch.await(waitTime, TimeUnit.MILLISECONDS); this.latch = null; } zookeeper.create(path, "".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); return true; } catch (Exception ee) { continue; } } } return true; } /** * 释放掉一个分布式锁 * * @param productId */ public void releaseDistributedLock(Long productId) { String path = "/product-lock-" + productId; try { zookeeper.delete(path, -1); System.out.println("release the lock for product[id=" + productId + "]......"); } catch (Exception e) { e.printStackTrace(); } } /** * 建立 zk session 的 watcher */ private class ZooKeeperWatcher implements Watcher { public void process(WatchedEvent event) { System.out.println("Receive watched event: " + event.getState()); if (KeeperState.SyncConnected == event.getState()) { connectedSemaphore.countDown(); } if (this.latch != null) { this.latch.countDown(); } } } /** * 封装单例的静态内部类 */ private static class Singleton { private static ZooKeeperSession instance; static { instance = new ZooKeeperSession(); } public static ZooKeeperSession getInstance() { return instance; } } /** * 获取单例 * * @return */ public static ZooKeeperSession getInstance() { return Singleton.getInstance(); } /** * 初始化单例的便捷方法 */ public static void init() { getInstance(); } }也可以采用另一种方式,创建临时顺序节点:
如果有一把锁,被多个人给竞争,此时多个人会排队,第一个拿到锁的人会执行,然后释放锁;后面的每个人都会去监听排在自己前面的那个人创建的 node 上,一旦某个人释放了锁,排在自己后面的人就会被 ZooKeeper 给通知,一旦被通知了之后,就 ok 了,自己就获取到了锁,就可以执行代码了。
public class ZooKeeperDistributedLock implements Watcher { private ZooKeeper zk; private String locksRoot = "/locks"; private String productId; private String waitNode; private String lockNode; private CountDownLatch latch; private CountDownLatch connectedLatch = new CountDownLatch(1); private int sessionTimeout = 30000; public ZooKeeperDistributedLock(String productId) { this.productId = productId; try { String address = "192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181"; zk = new ZooKeeper(address, sessionTimeout, this); connectedLatch.await(); } catch (IOException e) { throw new LockException(e); } catch (KeeperException e) { throw new LockException(e); } catch (InterruptedException e) { throw new LockException(e); } } public void process(WatchedEvent event) { if (event.getState() == KeeperState.SyncConnected) { connectedLatch.countDown(); return; } if (this.latch != null) { this.latch.countDown(); } } public void acquireDistributedLock() { try { if (this.tryLock()) { return; } else { waitForLock(waitNode, sessionTimeout); } } catch (KeeperException e) { throw new LockException(e); } catch (InterruptedException e) { throw new LockException(e); } } public boolean tryLock() { try { // 传入进去的locksRoot + “/” + productId // 假设productId代表了一个商品id,比如说1 // locksRoot = locks // /locks/10000000000,/locks/10000000001,/locks/10000000002 lockNode = zk.create(locksRoot + "/" + productId, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); // 看看刚创建的节点是不是最小的节点 // locks:10000000000,10000000001,10000000002 List<String> locks = zk.getChildren(locksRoot, false); Collections.sort(locks); if(lockNode.equals(locksRoot+"/"+ locks.get(0))){ //如果是最小的节点,则表示取得锁 return true; } //如果不是最小的节点,找到比自己小1的节点 int previousLockIndex = -1; for(int i = 0; i < locks.size(); i++) { if(lockNode.equals(locksRoot + “/” + locks.get(i))) { previousLockIndex = i - 1; break; } } this.waitNode = locks.get(previousLockIndex); } catch (KeeperException e) { throw new LockException(e); } catch (InterruptedException e) { throw new LockException(e); } return false; } private boolean waitForLock(String waitNode, long waitTime) throws InterruptedException, KeeperException { Stat stat = zk.exists(locksRoot + "/" + waitNode, true); if (stat != null) { this.latch = new CountDownLatch(1); this.latch.await(waitTime, TimeUnit.MILLISECONDS); this.latch = null; } return true; } public void unlock() { try { // 删除/locks/10000000000节点 // 删除/locks/10000000001节点 System.out.println("unlock " + lockNode); zk.delete(lockNode, -1); lockNode = null; zk.close(); } catch (InterruptedException e) { e.printStackTrace(); } catch (KeeperException e) { e.printStackTrace(); } } public class LockException extends RuntimeException { private static final long serialVersionUID = 1L; public LockException(String e) { super(e); } public LockException(Exception e) { super(e); } } }但是,使用 zk 临时节点会存在另一个问题:由于 zk 依靠 session 定期的心跳来维持客户端,如果客户端进入长时间的 GC,可能会导致 zk 认为客户端宕机而释放锁,让其他的客户端获取锁,但是客户端在 GC 恢复后,会认为自己还持有锁,从而可能出现多个客户端同时获取到锁的情形。
针对这种情况,可以通过 JVM 调优,尽量避免长时间 GC 的情况发生。
redis 分布式锁和 zk 分布式锁的对比
- redis 分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
- zk 分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较小。
另外一点就是,如果是 Redis 获取锁的那个客户端 出现 bug 挂了,那么只能等待超时时间之后才能释放锁;而 zk 的话,因为创建的是临时 znode,只要客户端挂了,znode 就没了,此时就自动释放锁。
所以先不分析太多的东西,就说这两点,个人实践认为 zk 的分布式锁比 Redis 的分布式锁牢靠、而且模型简单易用。
分布式事务
分布式事务的实现主要有以下 6 种方案:
- XA 方案
- TCC 方案
- SAGA 方案
- 本地消息表
- 可靠消息最终一致性方案
- 最大努力通知方案
两阶段提交方案/XA 方案
所谓的 XA 方案,即:两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来实现复杂的事务,效率很低,绝对不适合高并发的场景。
这个方案,很少用,一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。现在微服务,一个大的系统分成几十个甚至几百个服务。一般来说,我们的规定和规范,是要求每个服务只能操作自己对应的一个数据库。
如果你要操作别的服务对应的库,不允许直连别的服务的库,违反微服务架构的规范。
如果要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许交叉访问别人的数据库。
TCC 方案
TCC 的全称是:
Try、Confirm、Cancel。- Try 阶段:这个阶段对各个服务的资源做检测以及对资源进行锁定或者预留。
- Confirm 阶段:这个阶段在各个服务中执行实际的操作。
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
这种方案几乎很少人使用,但是也有使用的场景。因为这个事务回滚实际上是严重依赖于你自己写代码来回滚和补偿了,会造成补偿代码巨大。
比如说,一般跟钱相关的,支付、交易相关的场景,会用 TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性,保证在资金上不会出现问题。
而且最好是各个业务执行的时间都比较短。
但是自己手写回滚逻辑,或者是补偿逻辑,实在不优雅,业务代码是很难维护的。
Saga 方案
金融核心等业务可能会选择 TCC 方案,以追求强一致性和更高的并发量,而对于更多的金融核心以上的业务系统 往往会选择补偿事务,补偿事务处理在 30 多年前就提出了 Saga 理论,随着微服务的发展,近些年才逐步受到大家的关注。目前业界比较公认的是采用 Saga 作为长事务的解决方案。
基本原理
业务流程中每个参与者都提交本地事务,若某一个参与者失败,则补偿前面已经成功的参与者。
使用场景
对于一致性要求高、短流程、并发高 的场景,如:金融核心系统,会优先考虑 TCC 方案。而在另外一些场景下,我们并不需要这么强的一致性,只需要保证最终一致性即可。
比如 很多金融核心以上的业务(渠道层、产品层、系统集成层),这些系统的特点是最终一致即可、流程多、流程长、还可能要调用其它公司的服务。这种情况如果选择 TCC 方案开发,一来成本高,二来无法要求其它公司的服务也遵循 TCC 模式。同时流程长,事务边界太长,加锁时间长,也会影响并发性能。
所以 Saga 模式的适用场景是:
- 业务流程长、业务流程多;
- 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口。
优势
- 一阶段提交本地事务,无锁,高性能;
- 参与者可异步执行,高吞吐;
- 补偿服务易于实现,因为一个更新操作的反向操作是比较容易理解的。
缺点
- 不保证事务的隔离性。
本地消息表
本地消息表其实是国外的 ebay 搞出来的一套思想。
大概意思是:
- A 系统在自己本地一个事务里操作同时,插入一条数据到消息表;
- A 系统将这个消息发送到 MQ 中去;
- B 系统接收到消息之后,在一个事务里,往自己本地消息表里插入一条数据,同时执行其他的业务操作,如果这个消息已经被处理过了,那么此时这个事务会回滚,这样保证不会重复处理消息;
- B 系统执行成功之后,就会更新自己本地消息表的状态以及 A 系统消息表的状态;
- 如果 B 系统处理失败了,就不会更新消息表状态,A 系统会定时扫描自己的消息表,如果有未处理的消息,会再次发送到 MQ 中去,让 B 再次处理;
- 这个方案保证了最终一致性,哪怕 B 事务失败了,但是 A 会不断重发消息,直到 B 那边成功为止。
这个方案最大的问题就在于严重依赖于数据库的消息表来管理事务啥的,如果是高并发场景就很难处理,所以一般很少用。
最终一致性方案
这个的意思,就是干脆不要用本地的消息表了,直接基于 MQ 来实现事务。比如阿里的 RocketMQ 就支持消息事务。
大概的意思是:
- A 系统先发送一个 prepared 消息到 mq,如果这个 prepared 消息发送失败那么就直接取消操作别执行了;
- 如果这个消息发送成功了,那么接着执行本地事务,如果成功就告诉 mq 发送确认消息,如果失败就告诉 mq 回滚消息;
- 如果发送了确认消息,那么 B 系统会接收到确认消息,然后执行本地的事务;
- mq 会自动定时轮询所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了导致没发送确认的消息,是继续重试还是回滚?一般来说这里可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
- 这个方案里,要是系统 B 的事务失败了就要重试,自动不断重试直到成功,如果实在不行,要么就针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
目前国内互联网公司大都采用这种方案。某些特别严格的场景,可以用 TCC 来保证强一致性;其他的一些场景基于消息队列来实现分布式事务。
-
消息队列
为什么使用消息队列
解耦
A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?要在代码中维护大量的调用关系。
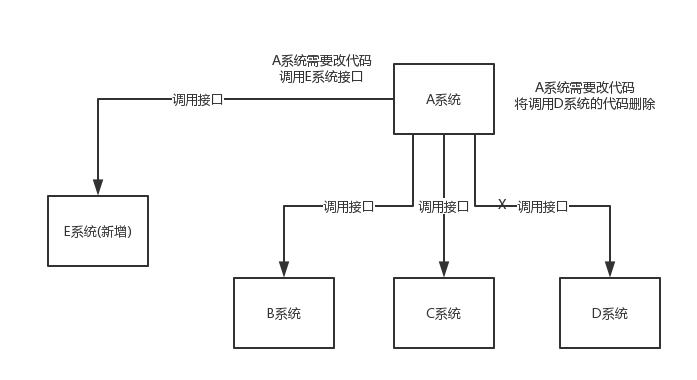
在这个场景中,A 系统跟其它各种系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了该怎么办?要不要重发,要不要把消息存起来。
如果使用 MQ,A 系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统根本不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。
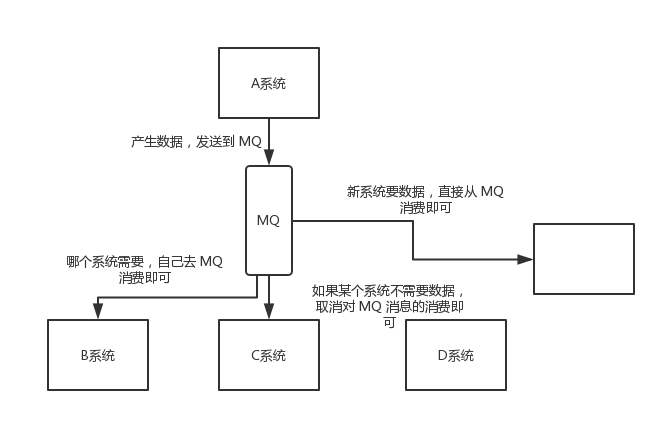
总结:通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
异步
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s。用户通过浏览器发起请求,等待 1s,这几乎是不可接受的。
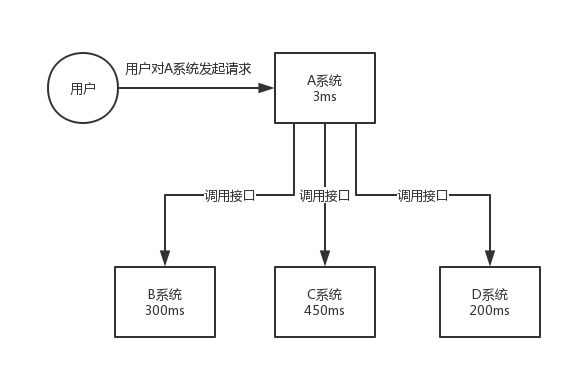
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的。
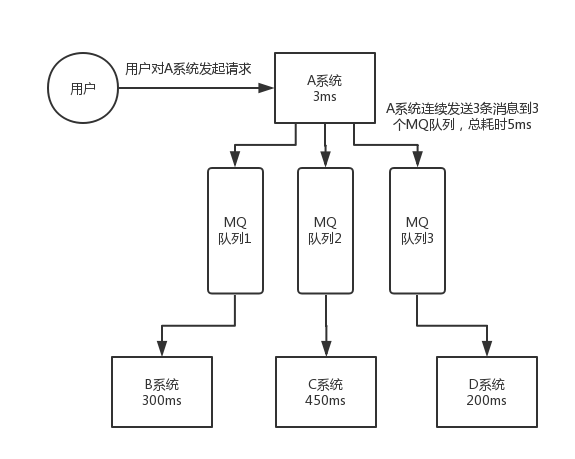
如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了。
削峰
每天 0:00 到 12:00,A 系统请求很少,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
一般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,系统可能直接崩溃。
但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。
如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
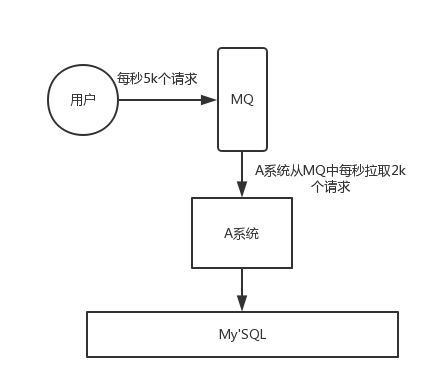
短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给解决掉。
消息队列有什么优缺点
消息队列优点就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点有以下几个:
- 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来 A 系统调用 BCD 三个系统的接口就好了,ABCD 四个系统正常运行,这时加个 MQ 进来,需要额外维护 MQ 的状态。
- 系统复杂度提高
加个 MQ 进来,要保证消息没有重复消费、处理消息丢失的情况、保证消息传递的顺序性等。
- 一致性问题
A 系统处理完了直接返回成功了,用户以为这个请求成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,就会数据不一致。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
特性 ActiveMQ RabbitMQ RocketMQ Kafka 单机吞吐量 万级,比 RocketMQ、Kafka 低一个数量级 同 ActiveMQ 10 万级,支撑高吞吐 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 topic 数量对吞吐量的影响 topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 时效性 ms 级 微秒级,这是 RabbitMQ 的一大特点,延迟最低 ms 级 延迟在 ms 级以内 可用性 高,基于主从架构实现高可用 同 ActiveMQ 非常高,分布式架构 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 消息可靠性 有较低的概率丢失数据 基本不丢 经过参数优化配置,可以做到 0 丢失 同 RocketMQ 功能支持 MQ 领域的功能极其完备 基于 erlang 开发,并发能力很强,性能极好,延时很低 MQ 功能较为完善,还是分布式的,扩展性好 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 综上,各种对比之后,有如下建议:
越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 Apache,但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则建议使用 RabbitMQ ,它有活跃的开源社区。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高。
如何保证消息队列的高可用
RabbitMQ 的高可用性
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的。
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式
单机模式,就是 Demo 级别的,用来学习。
普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。消费的时候,如果连接到了另外一个实例,那个实例会从 queue 所在实例上拉取数据过来。
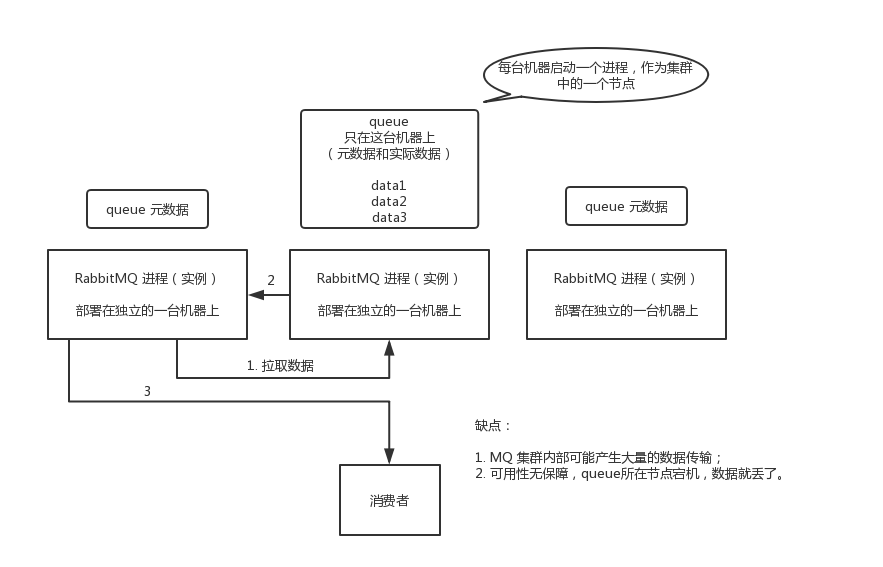
这种方式不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这就没有什么高可用性,这方案主要是提高吞吐量的,就是让集群中多个节点来服务某个 queue 的读写操作。
镜像集群模式(高可用性)
这种模式,才是 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据。每次写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
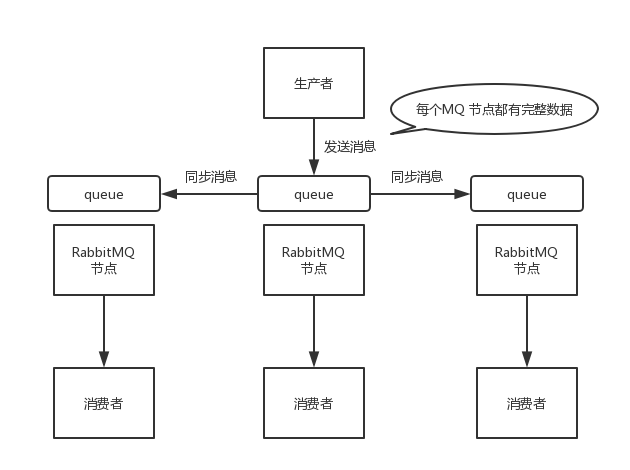
RabbitMQ 有很好的管理控制台,在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上了。
任何一个机器宕机了,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销很大,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这个不是分布式的,没有扩展性可言了,如果某个 queue 负载很重,加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展 queue。如果这个 queue 的数据量很大,大到这个机器上的容量无法容纳了,这个方法就不通了。
Kafka 的高可用性
Kafka 由多个 broker 组成,每个 broker 是一个节点;创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。
这就是分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
实际上 RabbitMQ 之类的,并不是分布式消息队列,它就是传统的消息队列,只不过提供了一些集群、HA(High Availability, 高可用性) 的机制而已,因为无论如何,RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。
Kafka 0.8 以前,是没有 HA 机制的,就是任何一个 broker 宕机了,那个 broker 上的 partition 就没用了,没法写也没法读,没有什么高可用性可言。
比如,假设创建了一个 topic,指定其 partition 数量是 3 个,分别在三台机器上。但是,如果第二台机器宕机了,会导致这个 topic 的 1/3 的数据丢失,因此这个是做不到高可用的。
Kafka 0.8 以后,提供了 HA 机制,即: replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,生产和消费都跟这个 leader 交互,然后其他 replica 就是 follower。
写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
这样,就有高可用性了,因为如果某个 broker 宕机了,那个 broker 上面的 partition 在其他机器上都有副本的。如果这个宕机的 broker 上面有某个 partition 的 leader,此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。
写数据的时候,生产者就写 leader,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
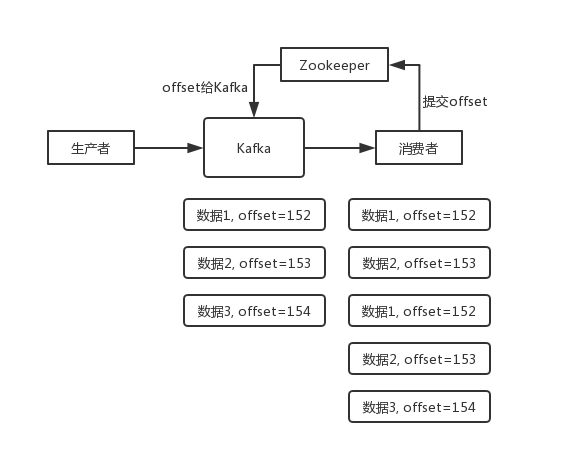
如何保证消息不被重复消费
比如 RabbitMQ、RocketMQ、Kafka,都有可能会出现消息重复消费的问题,因为这问题通常不是 MQ 自己保证的,是由开发来保证的。
Kafka 有个 offset 的概念,每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启等,就让我继续从上次消费到的 offset 来继续消费”。
但是凡事总有意外,比如有时候重启系统,直接 kill 进程,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset。重启之后,少数消息会再次消费一次。
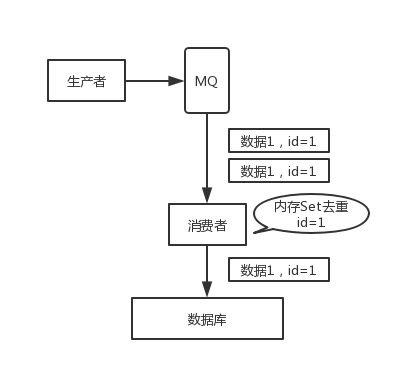
其实重复消费不可怕,可怕的是没考虑到重复消费之后,怎么保证幂等性。
假设你有个系统,消费一条消息就往数据库里插入一条数据,要是一个消息重复两次,就插入了两条,这就是错误业务数据?但是要是消费到第二次的时候,提前判断一下是否已经消费过了,若是就直接退出,这样就保证了业务的正确性。
这里给几个保证幂等性的思路:
- 数据要写数据库,你先根据主键查一下,如果数据已有,直接 update
- 如果要写 Redis,那没问题,反正每次都是 set,天然就是幂等性。
- 如果稍微复杂一点,需要让生产者发送每条数据的时候,里面加一个全局唯一的 id,类似订单 id 之类,这里消费到了之后,先根据这个 id 去查一下,之前消费过吗(是否有相关业务数据)?如果没有消费过,就进行业务处理。如果消费过了,那你就别重复处理了。
如何保证消息的顺序性
举个例子,有一个 mysql
binlog同步的系统,压力非常大,日同步数据要达到上亿。在 mysql 里增删改一条数据,对应出来了增删改 3 条
binlog日志,这三条binlog发送到 MQ 里面,再消费出来依次执行,起码得保证是按照顺序来的。先看看顺序会错乱的俩场景:
-
RabbitMQ:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者 2 先执行完操作,把 data2 存入数据库,然后是 data1/data3。
-
Kafka:建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,在消费者里可能会有多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
解决方案
RabbitMQ
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
Kafka
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
延时以及过期失效问题
大量消息在 mq 里积压了几个小时了还没解决
一个消费者一秒是 1000 条,3 个消费者是 3000 条,一分钟就是 18 万条。所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概 1 小时的时间才能恢复过来。
一般这个时候,只能临时紧急扩容,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
mq 中的消息过期失效了
假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。
这个情况下,就不是要增加 consumer 消费积压的消息,因为实际上不会积压,而是丢了大量的消息。可以采取批量重导。大量积压的时候,直接丢弃数据,等过了高峰期以后,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。
mq 快写满
如果消息积压在 mq 里,很长时间都没有处理掉,此时导致 mq 都快写满了。这个还有别的办法吗?没有,只能临时写程序,接入数据来消费,可以直接丢弃大量数据。然后走第二个方案,到了晚上再补数据。
对于 RocketMQ,官方针对消息积压问题,提供了解决方案。
1. 提高消费并行度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。 如下有几种修改消费并行度的方法:
同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。 提高单个 Consumer 的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax 实现。
2. 批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量,通过设置 consumer 的 consumeMessageBatchMaxSize 返个参数,默认是 1,即一次只消费一条消息,例如设置为 N,那么每次消费的消息数小于等于 N。
3. 跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。例如,当某个队列的消息数堆积到 100000 条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度。示例代码如下:
public ConsumeConcurrentlyStatus consumeMessage( List<MessageExt> msgs, ConsumeConcurrentlyContext context) { long offset = msgs.get(0).getQueueOffset(); String maxOffset = msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET); long diff = Long.parseLong(maxOffset) - offset; if (diff > 100000) { // TODO 消息堆积情况的特殊处理 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; } // TODO 正常消费过程 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; }4. 优化每条消息消费过程
举例如下,某条消息的消费过程如下:
- 根据消息从 DB 查询【数据 1】
- 根据消息从 DB 查询【数据 2】
- 复杂的业务计算
- 向 DB 插入【数据 3】
- 向 DB 插入【数据 4】
这条消息的消费过程中有 4 次与 DB 的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把 DB 部署在 SSD 硬盘,相比于 SCSI 磁盘,前者的 RT 会小很多。
- 系统可用性降低
-
ES基础原理
es 原理
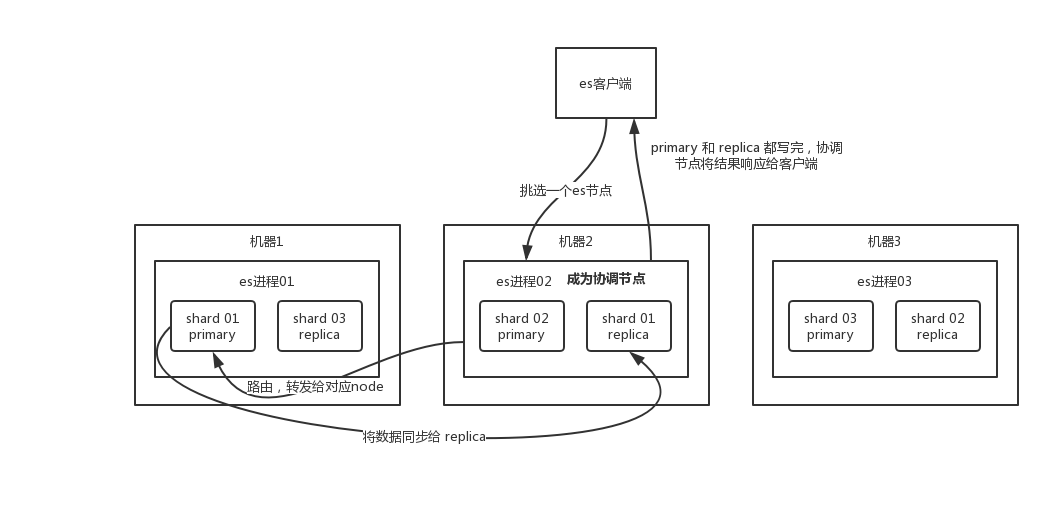
es 写数据过程
- 客户端选择一个 node 发送请求过去,这个 node 就是
coordinating node(协调节点)。 coordinating node对 document 进行路由,将请求转发给对应的 node(有 primary shard)。- 实际的 node 上的
primary shard处理请求,然后将数据同步到replica node。 coordinating node如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
es 读数据过程
可以通过
doc id来查询,会根据doc id进行 hash,判断出来当时把doc id分配到了哪个 shard 上面去,从那个 shard 去查询。- 客户端发送请求到任意一个 node,成为
coordinate node。 coordinate node对doc id进行哈希路由,将请求转发到对应的 node,此时会使用round-robin随机轮询算法,在primary shard以及其所有 replica 中随机选择一个,让读请求负载均衡。- 接收请求的 node 返回 document 给
coordinate node。 coordinate node返回 document 给客户端。
es 搜索数据过程
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊 java好难学啊 j2ee特别牛你根据
java关键词来搜索,将包含java的document给搜索出来。es 就会给你返回:java 真好玩儿啊,java 好难学啊。- 客户端发送请求到一个
coordinate node。 - 协调节点将搜索请求转发到所有的 shard 对应的
primary shard或replica shard,都可以。 - query phase:每个 shard 将自己的搜索结果(其实就是一些
doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - fetch phase:接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
写数据底层原理
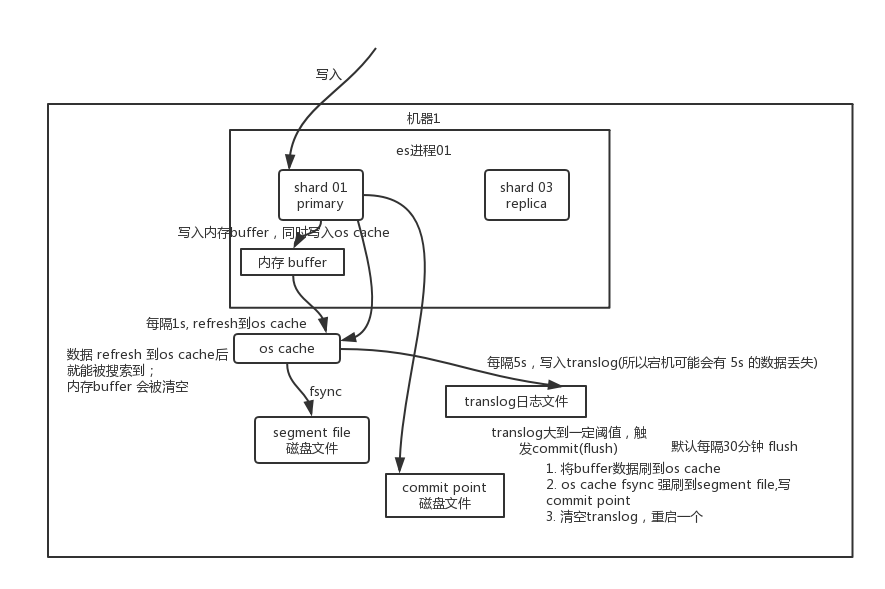
先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据
refresh到一个新的segment file中,但是此时数据不是直接进入segment file磁盘文件,而是先进入os cache。这个过程就是refresh。每隔 1 秒钟,es 将 buffer 中的数据写入一个新的
segment file,每秒钟会产生一个新的磁盘文件segment file,这个segment file中就存储最近 1 秒内 buffer 中写入的数据。但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
操作系统里面,磁盘文件其实都有一个东西,叫做
os cache,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去。只要buffer中的数据被 refresh 操作刷入os cache中,这个数据就可以被搜索到了。为什么叫 es 是准实时的?
NRT,全称near real-time。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的restful api或者java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入os cache中,让数据立马就可以被搜索到。只要数据被输入os cache中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将
buffer数据写入一个又一个新的segment file中去,每次refresh完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发commit操作。commit 操作发生第一步,就是将 buffer 中现有数据
refresh到os cache中去,清空 buffer。然后,将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空 现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。这个 commit 操作叫做
flush。默认 30 分钟自动执行一次flush,但如果 translog 过大,也会触发flush。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去。translog 日志文件的作用是什么?你执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件
translog中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接
fsync到磁盘,但是性能会差很多。其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的数据丢失。
总结一下,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
数据写入 segment file 之后,同时就建立好了倒排索引。
删除/更新数据底层原理
如果是删除操作,commit 的时候会生成一个
.del文件,里面将某个 doc 标识为deleted状态,那么搜索的时候根据.del文件就知道这个 doc 是否被删除了。如果是更新操作,就是将原来的 doc 标识为
deleted状态,然后新写入一条数据。buffer 每 refresh 一次,就会产生一个
segment file,所以默认情况下是 1 秒钟一个segment file,这样下来segment file会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个segment file合并成一个,同时这里会将标识为deleted的 doc 给物理删除掉,然后将新的segment file写入磁盘,这里会写一个commit point,标识所有新的segment file,然后打开segment file供搜索使用,同时删除旧的segment file。底层 lucene
简单来说,lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码。我们用 Java 开发的时候,引入 lucene jar,然后基于 lucene 的 api 去开发就可以了。
通过 lucene,我们可以将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。
倒排索引
在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。
那么,倒排索引就是关键词到文档 ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。
举个例子。
有以下文档:
DocId Doc 1 谷歌地图之父跳槽 Facebook 2 谷歌地图之父加盟 Facebook 3 谷歌地图创始人拉斯离开谷歌加盟 Facebook 4 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 5 谷歌地图之父拉斯加盟社交网站 Facebook 对文档进行分词之后,得到以下倒排索引。
WordId Word DocIds 1 谷歌 1, 2, 3, 4, 5 2 地图 1, 2, 3, 4, 5 3 之父 1, 2, 4, 5 4 跳槽 1, 4 5 Facebook 1, 2, 3, 4, 5 6 加盟 2, 3, 5 7 创始人 3 8 拉斯 3, 5 9 离开 3 10 与 4 .. .. .. 另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询
Facebook,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。要注意倒排索引的两个重要细节:
- 倒排索引中的所有词项对应一个或多个文档;
- 倒排索引中的词项根据字典顺序升序排列
上面只是一个简单的例子,并没有严格按照字典顺序升序排列。
es 性能优化
杀手锏——filesystem cache
你往 es 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到
filesystem cache里面去。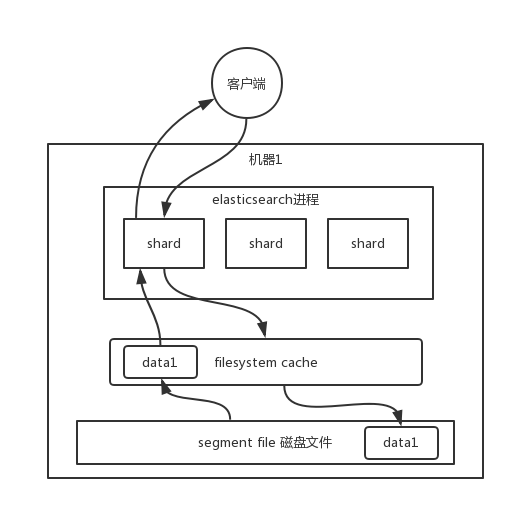
es 的搜索引擎严重依赖于底层的
filesystem cache,你如果给filesystem cache更多的内存,尽量让内存可以容纳所有的idx segment file索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。性能差距究竟可以有多大?我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1 秒、5 秒、10 秒。但如果是走
filesystem cache,是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。这里有个真实的案例。某个公司 es 节点有 3 台机器,每台机器看起来内存很多,64G,总内存就是
64 * 3 = 192G。每台机器给 es jvm heap 是32G,那么剩下来留给filesystem cache的就是每台机器才32G,总共集群里给filesystem cache的就是32 * 3 = 96G内存。而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了1T的磁盘容量,es 数据量是1T,那么每台机器的数据量是300G。这样性能好吗?filesystem cache的内存才 100G,十分之一的数据可以放内存,其他的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。归根结底,你要让 es 性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半。
根据我们自己的生产环境实践经验,最佳的情况下,是仅仅在 es 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给
filesystem cache的是 100G,那么你就将索引数据控制在100G以内,这样的话,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在 1 秒以内。比如说你现在有一行数据。
id,name,age ....30 个字段。但是你现在搜索,只需要根据id,name,age三个字段来搜索。如果你傻乎乎往 es 里写入一行数据所有的字段,就会导致说90%的数据是不用来搜索的,结果硬是占据了 es 机器上的filesystem cache的空间,单条数据的数据量越大,就会导致filesystem cahce能缓存的数据就越少。其实,仅仅写入 es 中要用来检索的少数几个字段就可以了,比如说就写入 esid,name,age三个字段,然后你可以把其他的字段数据存在 mysql/hbase 里,我们一般是建议用es + hbase这么一个架构。hbase 的特点是适用于海量数据的在线存储,就是对 hbase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了。从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个
doc id,然后根据doc id到 hbase 里去查询每个doc id对应的完整的数据,给查出来,再返回给前端。写入 es 的数据最好小于等于,或者是略微大于 es 的 filesystem cache 的内存容量。然后你从 es 检索可能就花费 20ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms。
数据预热
假如说,es 集群中每个机器写入的数据量还是超过了
filesystem cache一倍,比如说你写入一台机器 60G 数据,结果filesystem cache就 30G,还是有 30G 数据留在了磁盘上。其实可以做数据预热。
举个例子,拿微博来说,你可以把一些大 V,平时看的人很多的数据,你自己提前后台搞个系统,每隔一会儿,自己的后台系统去搜索一下热数据,刷到
filesystem cache里去,后面用户实际上来看这个热数据的时候,他们就是直接从内存里搜索了,很快。或者是电商,你可以将平时查看最多的一些商品,比如说 iphone 8,热数据提前后台搞个程序,每隔 1 分钟自己主动访问一次,刷到
filesystem cache里去。对于那些你觉得比较热的、经常会有人访问的数据,最好做一个专门的缓存预热子系统,就是对热数据每隔一段时间,就提前访问一下,让数据进入
filesystem cache里面去。这样下次别人访问的时候,性能一定会好很多。冷热分离
es 可以做类似于 mysql 的水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在
filesystem os cache里,别让冷数据给冲刷掉。假设你有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 shard。3 台机器放热数据 index,另外 3 台机器放冷数据 index。然后这样的话,你大量的时间是在访问热数据 index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都保留在
filesystem cache里面了,就可以确保热数据的访问性能是很高的。但是对于冷数据而言,是在别的 index 里的,跟热数据 index 不在相同的机器上,大家互相之间都没什么联系了。如果有人访问冷数据,可能大量数据是在磁盘上的,此时性能差点,就 10% 的人去访问冷数据,90% 的人在访问热数据,也无所谓了。document 模型设计
对于 MySQL,我们经常有一些复杂的关联查询。在 es 里面的复杂的关联查询尽量别用,一旦用了性能一般都不太好。
最好是先在 Java 系统里就完成关联,将关联好的数据直接写入 es 中。搜索的时候,就不需要利用 es 的搜索语法来完成 join 之类的关联搜索了。
document 模型设计是非常重要的,很多操作,不要在搜索的时候才想去执行各种复杂的乱七八糟的操作。es 能支持的操作就那么多,不要考虑用 es 做一些它不好操作的事情。如果真的有那种操作,尽量在 document 模型设计的时候,写入的时候就完成。另外对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差。
分页性能优化
es 的分页是较坑的,为啥呢?举个例子吧,假如你每页是 10 条数据,你现在要查询第 100 页,实际上是会把每个 shard 上存储的前 1000 条数据都查到一个协调节点上,如果你有个 5 个 shard,那么就有 5000 条数据,接着协调节点对这 5000 条数据进行一些合并、处理,再获取到最终第 100 页的 10 条数据。
分布式的,你要查第 100 页的 10 条数据,不可能说从 5 个 shard,每个 shard 就查 2 条数据,最后到协调节点合并成 10 条数据吧?你必须得从每个 shard 都查 1000 条数据过来,然后根据你的需求进行排序、筛选等等操作,最后再次分页,拿到里面第 100 页的数据。你翻页的时候,翻的越深,每个 shard 返回的数据就越多,而且协调节点处理的时间越长,非常坑。所以用 es 做分页的时候,你会发现越翻到后面,就越是慢。
有什么解决方案吗?
不允许深度分页(默认深度分页性能很差)
跟产品经理说,你系统不允许翻那么深的页,默认翻的越深,性能就越差。
类似于 app 里的推荐商品不断下拉出来一页一页的
类似于微博中,下拉刷微博,刷出来一页一页的,你可以用
scroll api,关于如何使用,自行上网搜索。scroll 会一次性给你生成所有数据的一个快照,然后每次滑动向后翻页就是通过游标
scroll_id移动,获取下一页下一页这样子,性能会比上面说的那种分页性能要高很多很多,基本上都是毫秒级的。但是,唯一的一点就是,这个适合于那种类似微博下拉翻页的,不能随意跳到任何一页的场景。也就是说,你不能先进入第 10 页,然后去第 120 页,然后又回到第 58 页,不能随意乱跳页。所以现在很多产品,都是不允许你随意翻页的,app,也有一些网站,做的就是你只能往下拉,一页一页的翻。
初始化时必须指定
scroll参数,告诉 es 要保存此次搜索的上下文多长时间。你需要确保用户不会持续不断翻页翻几个小时,否则可能因为超时而失败。除了用
scroll api,你也可以用search_after来做,search_after的思想是使用前一页的结果来帮助检索下一页的数据,显然,这种方式也不允许你随意翻页,你只能一页页往后翻。初始化时,需要使用一个唯一值的字段作为 sort 字段。
- 客户端选择一个 node 发送请求过去,这个 node 就是
-
Redis实践与原理
Redis 和 Memcached 有何区别?
Redis 支持复杂的数据结构
Redis 相比 Memcached 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, Redis 会是不错的选择。
Redis 数据结构
Redis 主要有以下几种数据类型:
- Strings
- Hashes
- Lists
- Sets
- Sorted Sets
Redis 除了这 5 种数据类型之外,还有 Bitmaps、HyperLogLogs、Streams 等。
Strings
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
set college szuHashes
这个是类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 hash 里的某个字段。
hset person name bingo hset person age 20 hset person id 1 hget person name(person = { "name": "bingo", "age": 20, "id": 1 })Lists
Lists 是有序列表,这个可以玩儿出很多花样。
比如可以通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 list 实现分页查询,这个是很棒的一个功能,基于 Redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
# 0开始位置,-1结束位置,结束位置为-1时,表示列表的最后一个位置,即查看所有。 lrange mylist 0 -1比如可以搞个简单的消息队列,从 list 头怼进去,从 list 尾巴那里弄出来。
lpush mylist 1 lpush mylist 2 lpush mylist 3 4 5 # 1 rpop mylistSets
Sets 是无序集合,自动去重。
直接基于 set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 jvm 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于 Redis 进行全局的 set 去重。
可以基于 set 玩儿交集、并集、差集的操作,比如交集吧,可以把两个人的粉丝列表整一个交集,看看俩人的共同好友是谁?对吧。
把两个大 V 的粉丝都放在两个 set 中,对两个 set 做交集。
#-------操作一个set------- # 添加元素 sadd mySet 1 # 查看全部元素 smembers mySet # 判断是否包含某个值 sismember mySet 3 # 删除某个/些元素 srem mySet 1 srem mySet 2 4 # 查看元素个数 scard mySet # 随机删除一个元素 spop mySet #-------操作多个set------- # 将一个set的元素移动到另外一个set smove yourSet mySet 2 # 求两set的交集 sinter yourSet mySet # 求两set的并集 sunion yourSet mySet # 求在yourSet中而不在mySet中的元素 sdiff yourSet mySetSorted Sets
Sorted Sets 是排序的 set,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
zadd board 85 zhangsan zadd board 72 lisi zadd board 96 wangwu zadd board 63 zhaoliu # 获取排名前三的用户(默认是升序,所以需要 rev 改为降序) zrevrange board 0 3 # 获取某用户的排名 zrank board zhaoliuRedis 原生支持集群模式
在 Redis3.x 版本中,便能支持 cluster 模式,而 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
性能对比
由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis。虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。
Redis 的线程模型
Redis 内部使用文件事件处理器
file event handler,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。文件事件处理器的结构包含 4 个部分:
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将产生事件的 socket 放入队列中排队,事件分派器每次从队列中取出一个 socket,根据 socket 的事件类型交给对应的事件处理器进行处理。
来看客户端与 Redis 的一次通信过程:
首先,Redis 服务端进程初始化的时候,会将 server socket 的
AE_READABLE事件与连接应答处理器关联。客户端 socket01 向 Redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个
AE_READABLE事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的AE_READABLE事件与命令请求处理器关联。假设此时客户端发送了一个
set key value请求,此时 Redis 中的 socket01 会产生AE_READABLE事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的AE_READABLE事件,由于前面 socket01 的AE_READABLE事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的key value并在自己内存中完成key value的设置。操作完成后,它会将 socket01 的AE_WRITABLE事件与命令回复处理器关联。如果此时客户端准备好接收返回结果了,那么 Redis 中的 socket01 会产生一个
AE_WRITABLE事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如ok,之后解除 socket01 的AE_WRITABLE事件与命令回复处理器的关联。这样便完成了一次通信。
为何 Redis 单线程模型也能效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
Redis 6.0 开始引入多线程
注意! Redis 6.0 之后的版本抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性地使用多线程模型。
前面还在强调 Redis 单线程模型的高效性,现在为什么又要引入多线程?这其实说明 Redis 在有些方面,单线程已经不具有优势了。因为读写网络的 Read/Write 系统调用在 Redis 执行期间占用了大部分 CPU 时间,如果把网络读写做成多线程的方式对性能会有很大提升。
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。 之所以这么设计是不想 Redis 因为多线程而变得复杂,需要去控制 key、lua、事务、LPUSH/LPOP 等等的并发问题。
总结
Redis 选择使用单线程模型处理客户端的请求主要还是因为 CPU 不是 Redis 服务器的瓶颈,所以使用多线程模型带来的性能提升并不能抵消它带来的开发成本和维护成本,系统的性能瓶颈也主要在网络 I/O 操作上;而 Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率。
Redis 过期策略
Redis 过期策略是:定期删除 + 惰性删除。
所谓定期删除,指的是 Redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
假设 Redis 里放了 10w 个 key,都设置了过期时间,你每隔几百毫秒,就检查 10w 个 key,那 Redis 基本上就死了,cpu 负载会很高的,消耗在你的检查过期 key 上了。注意,这里可不是每隔 100ms 就遍历所有的设置过期时间的 key,那样就是一场性能上的灾难。实际上 Redis 是每隔 100ms 随机抽取一些 key 来检查和删除的。
但是问题是,定期删除可能会导致很多过期 key 到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个 key 的时候,Redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
获取 key 的时候,如果此时 key 已经过期,就删除,不会返回任何东西。
但是实际上这还是有问题的,如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期 key 堆积在内存里,导致 Redis 内存块耗尽了,咋整?
答案是:走内存淘汰机制。
内存淘汰机制
Redis 内存淘汰机制有以下几个:
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
Redis 持久化策略如何选择
Redis 持久化的两种方式
- RDB:RDB 持久化机制,是对 Redis 中的数据执行周期性的持久化。
- AOF:AOF 机制对每条写入命令作为日志,以
append-only的模式写入一个日志文件中,在 Redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。
通过 RDB 或 AOF,都可以将 Redis 内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云等云服务。
如果 Redis 挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动 Redis,Redis 就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
如果同时使用 RDB 和 AOF 两种持久化机制,那么在 Redis 重启的时候,会使用 AOF 来重新构建数据,因为 AOF 中的数据更加完整。
RDB 优缺点
- RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 Redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说 Amazon 的 S3 云服务上去,在国内可以是阿里云的 ODPS 分布式存储上,以预定好的备份策略来定期备份 Redis 中的数据。
- RDB 对 Redis 对外提供的读写服务,影响非常小,可以让 Redis 保持高性能,因为 Redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 Redis 进程,更加快速。
- 如果想要在 Redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 Redis 进程宕机,那么会丢失最近 5 分钟(甚至更长时间)的数据。
- RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF 优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次
fsync操作,最多丢失 1 秒钟的数据。 - AOF 日志文件以
append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。 - AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在
rewritelog 的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的 merge 后的日志文件 ready 的时候,再交换新老日志文件即可。 - AOF 日志文件的命令通过可读较强的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用
flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。 - 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒
fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的。(如果实时写入,那么 QPS 会大降,Redis 性能会大大降低) - 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志
merge回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB 和 AOF 到底该如何选择
- 不要仅仅使用 RDB,因为那样会导致你丢失很多数据;
- 也不要仅仅使用 AOF,因为那样有两个问题:第一,你通过 AOF 做冷备,没有 RDB 做冷备来的恢复速度更快;第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug;
- Redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择;用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
Redis 哨兵集群实现高可用
sentinel,中文名是哨兵。哨兵是 Redis 集群架构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 Redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 Redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
- 故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题。
- 即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了。
哨兵的核心知识
- 哨兵至少需要 3 个实例,来保证自己的健壮性。
- 哨兵 + Redis 主从的部署架构,是不保证数据零丢失的,只能保证 Redis 集群的高可用性。
- 对于哨兵 + Redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
哨兵集群必须部署 2 个以上节点,如果哨兵集群仅仅部署了 2 个哨兵实例,quorum = 1。
+----+ +----+ | M1 |---------| R1 | | S1 | | S2 | +----+ +----+配置
quorum=1,如果 master 宕机, s1 和 s2 中只要有 1 个哨兵认为 master 宕机了,就可以进行切换,同时 s1 和 s2 会选举出一个哨兵来执行故障转移。但是同时这个时候,需要 majority,也就是大多数哨兵都是运行的。2 个哨兵,majority=2 3 个哨兵,majority=2 4 个哨兵,majority=2 5 个哨兵,majority=3 ...如果此时仅仅是 M1 进程宕机了,哨兵 s1 正常运行,那么故障转移是 OK 的。但是如果是整个 M1 和 S1 运行的机器宕机了,那么哨兵只有 1 个,此时就没有 majority 来允许执行故障转移,虽然另外一台机器上还有一个 R1,但是故障转移不会执行。
经典的 3 节点哨兵集群是这样的:
+----+ | M1 | | S1 | +----+ | +----+ | +----+ | R2 |----+----| R3 | | S2 | | S3 | +----+ +----+配置
quorum=2,如果 M1 所在机器宕机了,那么三个哨兵还剩下 2 个,S2 和 S3 可以一致认为 master 宕机了,然后选举出一个来执行故障转移,同时 3 个哨兵的 majority 是 2,所以还剩下的 2 个哨兵运行着,就可以允许执行故障转移。哨兵主备切换数据丢失的两种情况
主备切换的过程,可能会导致数据丢失:
- 异步复制导致的数据丢失
因为 master->slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这部分数据就丢失了。
- 脑裂导致的数据丢失
脑裂,也就是说,某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个 master ,也就是所谓的脑裂。
此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的 master,还继续向旧 master 写数据。因此旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master 上去,自己的数据会清空,重新从新的 master 复制数据。而新的 master 并没有后来 client 写入的数据,因此,这部分数据也就丢失了。
数据丢失问题的解决方案
进行如下配置:
min-slaves-to-write 1 min-slaves-max-lag 10表示,要求至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒。
如果说一旦所有的 slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,master 就不会再接收任何请求了。
- 减少异步复制数据的丢失
有了
min-slaves-max-lag这个配置,就可以确保说,一旦 slave 复制数据和 ack 延时太长,就认为可能 master 宕机后损失的数据太多了,那么就拒绝写请求,这样可以把 master 宕机时由于部分数据未同步到 slave 导致的数据丢失降低的可控范围内。- 减少脑裂的数据丢失
如果一个 master 出现了脑裂,跟其他 slave 丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的 slave 发送数据,而且 slave 超过 10 秒没有给自己 ack 消息,那么就直接拒绝客户端的写请求。因此在脑裂场景下,最多就丢失 10 秒的数据。
sdown 和 odown 转换机制
- sdown 是主观宕机,就一个哨兵如果自己觉得一个 master 宕机了,那么就是主观宕机
- odown 是客观宕机,如果 quorum 数量的哨兵都觉得一个 master 宕机了,那么就是客观宕机
sdown 达成的条件很简单,如果一个哨兵 ping 一个 master,超过了
is-master-down-after-milliseconds指定的毫秒数之后,就主观认为 master 宕机了;如果一个哨兵在指定时间内,收到了 quorum 数量的其它哨兵也认为那个 master 是 sdown 的,那么就认为是 odown 了。哨兵集群的自动发现机制
哨兵互相之间的发现,是通过 Redis 的
pub/sub系统实现的,每个哨兵都会往__sentinel__:hello这个 channel 里发送一个消息,这时候所有其他哨兵都可以消费到这个消息,并感知到其他的哨兵的存在。每隔两秒钟,每个哨兵都会往自己监控的某个 master+slaves 对应的
__sentinel__:hellochannel 里发送一个消息,内容是自己的 host、ip 和 runid 还有对这个 master 的监控配置。每个哨兵也会去监听自己监控的每个 master+slaves 对应的
__sentinel__:hellochannel,然后去感知到同样在监听这个 master+slaves 的其他哨兵的存在。每个哨兵还会跟其他哨兵交换对
master的监控配置,互相进行监控配置的同步。slave 配置的自动纠正
哨兵会负责自动纠正 slave 的一些配置,比如 slave 如果要成为潜在的 master 候选人,哨兵会确保 slave 复制现有 master 的数据;如果 slave 连接到了一个错误的 master 上,比如故障转移之后,那么哨兵会确保它们连接到正确的 master 上。
slave->master 选举算法
如果一个 master 被认为 odown 了,而且 majority 数量的哨兵都允许主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个 slave 来,会考虑 slave 的一些信息:
- 跟 master 断开连接的时长
- slave 优先级
- 复制 offset
- run id
如果一个 slave 跟 master 断开连接的时间已经超过了
down-after-milliseconds的 10 倍,外加 master 宕机的时长,那么 slave 就被认为不适合选举为 master。(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state接下来会对 slave 进行排序:
- 按照 slave 优先级进行排序,slave priority 越低,优先级就越高。
- 如果 slave priority 相同,那么看 replica offset,哪个 slave 复制了越多的数据,offset 越靠后,优先级就越高。
- 如果上面两个条件都相同,那么选择一个 run id 比较小的那个 slave。
quorum 和 majority
每次一个哨兵要做主备切换,首先需要 quorum 数量的哨兵认为 odown,然后选举出一个哨兵来做切换,这个哨兵还需要得到 majority 哨兵的授权,才能正式执行切换。
如果 quorum < majority,比如 5 个哨兵,majority 就是 3,quorum 设置为 2,那么就 3 个哨兵授权就可以执行切换。
但是如果 quorum >= majority,那么必须 quorum 数量的哨兵都授权,比如 5 个哨兵,quorum 是 5,那么必须 5 个哨兵都同意授权,才能执行切换。
configuration epoch
哨兵会对一套 Redis master+slaves 进行监控,有相应的监控的配置。
执行切换的那个哨兵,会从要切换到的新 master(salve->master)那里得到一个 configuration epoch,这就是一个 version 号,每次切换的 version 号都必须是唯一的。
如果第一个选举出的哨兵切换失败了,那么其他哨兵,会等待 failover-timeout 时间,然后接替继续执行切换,此时会重新获取一个新的 configuration epoch,作为新的 version 号。
configuration 传播
哨兵完成切换之后,会在自己本地更新生成最新的 master 配置,然后同步给其他的哨兵,就是通过之前说的
pub/sub消息机制。这里之前的 version 号就很重要了,因为各种消息都是通过一个 channel 去发布和监听的,所以一个哨兵完成一次新的切换之后,新的 master 配置是跟着新的 version 号的。其他的哨兵都是根据版本号的大小来更新自己的 master 配置的。
高并高处理
缓存雪崩
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
这就是缓存雪崩。
缓存雪崩的事前事中事后的解决方案如下:
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
用户发送一个请求,系统 A 收到请求后,先查本地 ehcache 缓存,如果没查到再查 Redis。如果 ehcache 和 Redis 都没有,再查数据库,将数据库中的结果,写入 ehcache 和 Redis 中。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空值。
好处:
- 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。
- 只要数据库不死,就是说,对用户来说,2/5 的请求都是可以被处理的。
- 只要有 2/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来了。
缓存穿透
对于系统 A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。
解决方式很简单,每次系统 A 从数据库中只要没查到,就写一个空值到缓存里去,比如
set -999 UNKNOWN。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。缓存击穿
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
不同场景下的解决方式可如下:
- 若缓存的数据是基本不会发生更新的,则可尝试将该热点数据设置为永不过期。
- 若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下,则可以采用基于 Redis、zookeeper 等分布式中间件的分布式互斥锁,或者本地互斥锁以保证仅少量的请求能请求数据库并重新构建缓存,其余线程则在锁释放后能访问到新缓存。
- 若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到对应的缓存。
何保证缓存与数据库的双写一致性
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个例子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。
最初级的缓存不一致问题及解决方案
问题:先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路:先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了…
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新执行“读取数据+更新缓存”的操作,根据唯一标识路由之后,也发送到同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,没有读到缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
- 读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。
该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压 100 个商品的库存修改操作,每个库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间,如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。
如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。
我们来实际粗略测算一下。
如果一秒有 500 的写操作,如果分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 hang 一会儿,200ms 以内肯定能返回了。
经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
- 读请求并发量过高
这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。
但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
- 多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。
比如说,对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
- 热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以其实要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
-
如何选择红酒杯
红酒杯怎么选?
喝葡萄酒一般用高脚杯,但实际上高脚杯的种类特别多,不同的酒要用不同的杯子,喝法也各不相同。虽然用错了杯子酒照样可以喝,但是效果会略差。很多酒品质和口味只差了一点点,价格可能差出去两三倍,随便用一个不合适的杯子,这点细微的差异就感觉不出来了。酿酒的人会觉得你糟践了他精心酿制的美酒。而且用错杯子也显得没文化,就好比上身穿了西装,下面配条运动裤,让人感觉怪怪的。
酒杯有大小之分和形状之别,之所以不同的酒用不同的杯子,是因为酒的特性各不相同,而不是矫情。喝红酒的酒杯,一般用两种,容积都比较大。常用的一种是“肚子”比较大,上面稍微收口的那种酒杯,因为它的形状像郁金香花苞,也称为大郁金香型。

喝红酒时,需要等它的味道散发出来,一边闻,一边喝。因此,酒杯的容积要大,这样便于它挥发。有时候为了帮助它挥发,手要不断地转动杯子。杯口略为收小,是为了防止转动杯子时酒洒出来。此外,还有一种喝红酒的杯子容积也很大,但是杯口处是直的,这是为了方便酒的味道慢慢挥发。
红酒在饮用之前,需要醒一段时间,主要是让它升到合适的温度(一般10-20度),酒的醇香开始挥发,同时让它和空气接触,有一点点氧化,这时酒的层次感才能慢慢品出来。喝红酒时,一般先会给主人倒上一小口尝尝,得到主人的认可后,才会给每一个人倒上。
红酒一般每次倒上4-6盎司,大约120-180毫升,占到杯子容积的一小半到一半。喝的时候要一口一口地慢慢喝,绝不能一口“干了”。喝之前,先要摇一摇,看看红酒在杯子上留下的印迹(挂杯),好的酒在杯子上留下的痕迹像是油状的,比较厚实,差的酒留下的是水状的。
接下来,要享受它的味道,可以将酒杯45度角端起,放到鼻子前轻轻闻一闻,在体会完酒香之后,轻轻嘬一口,体会一下味道,然后不大不小地喝上一口,在口中体会它里面复杂的味道,之后再喝下去。
喝红酒时,一般配红肉,这也比较好记。所谓红肉就是猪牛羊肉,因为红肉中脂肪较多,尤其是烤的肉,油脂更是渗了出来。红酒是酸性的,而且酸度还不低(一般PH值都在3-4之间),里面含有醋酸(乙酸),醋酸和油脂发生化学反应后,生成乙酸乙酯,是我们美食天然的香味来源。
喝白葡萄酒的用杯一般用容积较小,满杯也就装4-6盎司。杯子的形状有两种,一种是抛物线形的,另一种是比较细小一点的郁金香形的。白葡萄酒用小杯的原因是需要低温品尝,一般温度在0-10度,不能超过10度,有时在夏天甚至可以喝零度以下的白葡萄酒。

因此,如果杯子太大,每次倒得太多,还没有喝完,温度就上去了,味道就不好了。每次倒白葡萄酒不能超过2盎司,喝完了再加。白葡萄酒喝的是清洌甘美的感觉,这种醇美和红酒的丰富大不相同,因此喝的时候不要乱晃杯子,轻轻端起来喝一口,再把杯子放到一旁就可以了。
白葡萄酒在喝的时候先要冷却,一般在小冰桶里先放上20分钟,或者在冰箱保鲜区放上半小时。如果一瓶酒一次没有倒完,要放回到小冰桶里。喝白葡萄酒时,一般配以海鲜或者禽类的白肉,因此记住白酒配白肉就可以了。为什么吃海鲜和白肉时要配白葡萄酒,而不是红葡萄酒呢?因为红酒味道太重,掩盖了白肉的鲜味,而白葡萄酒清醇的味道,正好给白肉点缀一下。

香槟酒作为一种特殊的白葡萄酒,喝起来要用特殊的杯子。一般有两种喝香槟酒的杯子,一种是非常细长、开口很小的杯子,另一种是非常扁平的大开口杯子。为什么会用这两种非常极端的杯子呢?因为香槟酒里有气泡,用细长杯子的原因是让气泡不要一下子喷出来,一边喝一边体会,在坐下来吃正餐时,要用这种杯子。

扁平敞口的杯子目的正相反,反而要让气泡冒出来,增加轻松喜庆的气氛。因此在站立酒会上,或者正式宴会开场前的接待时间(Reception),大家有时先喝点香槟暖暖场,使用扁平的酒杯。你在有些电影中可能看到过,在招待会上,用这种扁平香槟杯层层摞起来,从上往下倒酒,也是为了烘托气氛。在站立酒会上也可以使用细长酒杯装香槟,但是在正餐上很少使用扁平香槟杯。

一般法国正餐有四道酒,次序是由浅到深,由淡到浓。先上的是香槟,一般度数只有12-13度,大家喝着聊聊天,吃点开胃菜。第二道是白葡萄酒,配凉菜,凉菜一般是海鲜、蔬菜、禽类等等。等到正餐主菜上来时,一般配以红酒。
法国波尔多红酒的度数一般是13.5度,罗纳河谷的一般在15度左右,美国的赤霞珠或者波尔多混酒会在14-15度左右,它们配牛排、羊排等烤制的肉类非常合适。最后吃完饭吃甜点时,配以甜点酒,比如葡萄牙的波特酒,加拿大冰酒,法国、西班牙或者美国的甜点酒等等。
个别大餐因为菜的道数非常多,会配以五种,极个别时候甚至有六种以上的酒(这种情况很少出现,因为太多种不同的酒喝下来,一般人会醉的)。如果配以两种红酒的话,则先上淡的,再上浓的。
-
如何品红酒
如何品红酒
葡萄酒种类很多,除了我们常说的红葡萄酒(红酒)和白葡萄酒之外,香槟、波特酒(Port)、冰酒等甜点酒,甚至白兰地(包括干邑)也是一种特殊的葡萄酒。
即便是红酒,也分好多好多种,但是同一类酒一般用同样形状的瓶子,所以看到瓶子的形状,就知道里面装了什么酒。
最常见的酒瓶是波尔多的。波尔多是法国最好的葡萄酒产区,大家经常听到的拉菲、木桐等天价酒都出自那里。波尔多在红酒里代表一类酒(以浓红葡萄为主的混酒)。波尔多酒瓶的形状是直颈直身的,在法国只有波尔多产区的酒有权力使用这种瓶子

在法国名气仅次于波尔多的产地是勃艮第,它的瓶子是瓶颈上端呈现流线型的直身瓶子,如下图:

和波尔多酒不同的是,勃艮第酒由单一葡萄酿成。红的是用黑皮诺,白的是用霞多丽。世界其他地区的黑皮诺红酒,或者霞多丽白葡萄酒,也采用这种瓶子,因此,看到瓶子,就应该知道里面是什么酒。
法国另一大葡萄酒产区是罗纳河谷,瓶子虽然也是流线脖子,直身的,但是比勃艮第的矮粗很多,因此是不会搞混的:

罗纳河谷北部出产西拉子葡萄( Syrah),它在澳大利亚被称为Shiraz。Syrah(西拉子)既可以酿制单一品种的罗纳河谷红酒,也用于和浓红葡萄一起制作混酒。由于罗纳河谷土地贫瘠却日照充足,出产的葡萄,糖度不高,浓度却很高,因此可以酿制很浓的红葡萄酒。最浓的可以达到17度(不能再高了,再高酵母就死了)。
世界上其他地区出产的西拉葡萄酒也采用罗纳河谷的瓶子。罗纳河谷南部出产沙托纳迪帕普(Châteauneuf-du-Pape)红酒,是一种混合型红酒。沙托纳迪帕普的酒瓶上面都有突出的徽章,非常好识别。

除非是甜品酒,葡萄酒的糖度不能很高,很多人喝葡萄酒往里面加可乐和雪碧,实在是暴殄天物。另外,很多葡萄产地,比如中国新疆,由于气候原因出产的葡萄糖分太多,便无法酿出好的葡萄酒。世界上好葡萄酒都来自于地中海式气候的地区,因为那里的气候适合生长酿酒的葡萄。
香槟——它其实是发泡的白葡萄酒。世界上只有法国香槟产区出产的这种发泡白葡萄酒才被允许称为香槟酒。美国和世界其它地方出产的,哪怕质量再好,也不能用这个名字,只能叫Sparkling Wine,意思是冒泡葡萄酒,也用香槟酒瓶。
香槟酒瓶子矮胖,瓶颈和瓶身的过渡区比较圆滑。它最大的特点是瓶塞处。由于瓶中有气压,因此瓶塞使用铁丝拧死,开瓶时,拧开铁丝,小心拔出瓶塞,接下来“嘭”的一声连酒带汽就喷了出来,这个场景大家可能并不陌生。

除了澳大利亚的葡萄酒,几乎所有的葡萄酒都要用橡木塞,塞子外面包上金属皮,这是为了防止虫咬。金属皮上会留有两个小孔,是为了换气。
保存葡萄酒时要横着摆放,有的酒架是斜着的,有一个倾角,这是要让酒瓶口向下摆放。很多电影里将酒瓶竖立摆放,或者斜着的时候瓶口朝上都是不对的。
酒瓶的底部会凹进去一块,这是为了在酒瓶直立时能沉淀酒渣,酒保存时间长了,会出现渣子,在开瓶之前,酒瓶要放一会儿,沉淀一下渣子再倒酒。葡萄酒从橡木桶装瓶后,需要陈化,才能全部完成所需要进行的化学反应,这样酒的味道才平衡而醇厚。
酒瓶凹进去越深,说明酒需要的陈化时间越长。一般来讲,越是浓的、越是好的酒才需要长时间陈化,因此它们的瓶子的凹坑就越深。对于新手来讲,如果不知道酒的好坏,最简单的办法是用手摸摸底下的凹坑,虽然不能说凹坑深的酒质量就好,但是太浅的或者说没有凹坑的八成好不了。不过也有例外的时候,同样质量的红酒,纳帕的浓度要比法国的高一些,因此凹坑也更深一点,但是这不能就说纳帕的更好。
-
前后端交互规范
2021-03-12#前后端交互规范
前后端接口请求的参数及返回值的定义,要尽量做到通用、有意义。
##命名 项目中参数命名尽量统一。如:
id表示单独的一条数据;ids表示数据列表;searchIpt表示查询的关键字;pageSize表示一页显示多少条pageNo表示当前页码startTime表示查询时间范围的,开始时间endTime表示查询时间范围的,结束时间
##参数 ###查询 项目中已经提供能用的
SearchListDto,它的属性如下:/** * 搜索框输出的值.关键字 */ @ApiModelProperty(value = "关键字", dataType = "String") private String searchIpt; /** * 当前页码 */ @ApiModelProperty(value = "当前页码", dataType = "Integer") private Integer pageNo; /** * 一页显示多少条 */ @ApiModelProperty(value = "一页显示多少条", dataType = "Integer") private Integer pageSize;该类已经提供了最基础的关键字、分页查询信息。如果不能满足业务列表查询,可以自定义查询条件类继承该类,以扩充条件。
###详情、删除 项目中提供了
BaseDto,用来传递一个 id,属性如下:/** * 信息ID */ @ApiModelProperty(name = "id", value = "信息ID", dataType = "int") private Integer id;在查看某信息的详情,或者删除某一个单条信息时,可以直接用该类传递参数。
###批量处理 项目中提供传递多个 id 的参数类,
SimpleIdListDto,它的属性如下:/** * 信息ID列表 */ @ApiModelProperty(name = "ids", value = "信息ID列表", dataType = "int") private List<Integer> ids;在需要传递 id 列表时可以直接使用该参数类。比如:批量删除、批量导出、批量转发、批量接收、批量拒收等。
##返回值 ###返回内容 各字段要返回有意义的内容,不要返回
NULL- 字段类型是
List,返回new ArrayList() - 类型是
array,返回[] - 类型是
Integer,返回 0 - 类型是
String,返回空字符串""
其它类型同理。
###列表 涉及到列表信息返回的情况,统一封装成
PageUtils,该类属性如下:/** * 总记录数 */ private int totalCount; /** * 每页记录数 */ private int pageSize; /** * 总页数 */ private int totalPage; /** * 当前页数 */ private int currPage; /** * 列表数据 */ private List<?> list;###下拉列表 项目中提供可复用的下拉列表返回值包装类
CombineSelectDto,它的属性如下:/** * 下拉选项列表 */ private List<SimpleSelectDto> children;单个选项
SimpleSelectDto,属性如下:/** * 下拉选项的广本 */ private String label; /** * 下拉选项的值 */ private Integer value;如果下拉选项的值不是整数型,可以使用另一个包装类:
CommonSelectDto。###图表显示 显示线状、柱状、饼状图的时候,需要返回一系列数据。可以使用包装类:
ChartLineDto,它的属性如下:/** * 图例唯一识别码,一个图中显示多条线、多个柱的时候会用此值做识别 */ private String key; /** * 图例标题 */ private String name; /** * 图例中的节点列表 */ private List<ChartNodeDto> value;ChartNodeDto表示的是一个数据节点。属性如下:/** * 节点的唯一识别码 */ private String key; /** * 节点名称,如时间统计图中的某个月 2021-01 */ private String name; /** * 节点的值 */ private Double value;
-
开发流程
开发流程
监管态势团队采用迭代式开发。每个版本预计 2-3 周的时间。团队角色分为:产品人员、前端研发、后端研发、测试人员、运维人员。
工程流程大致如下图:
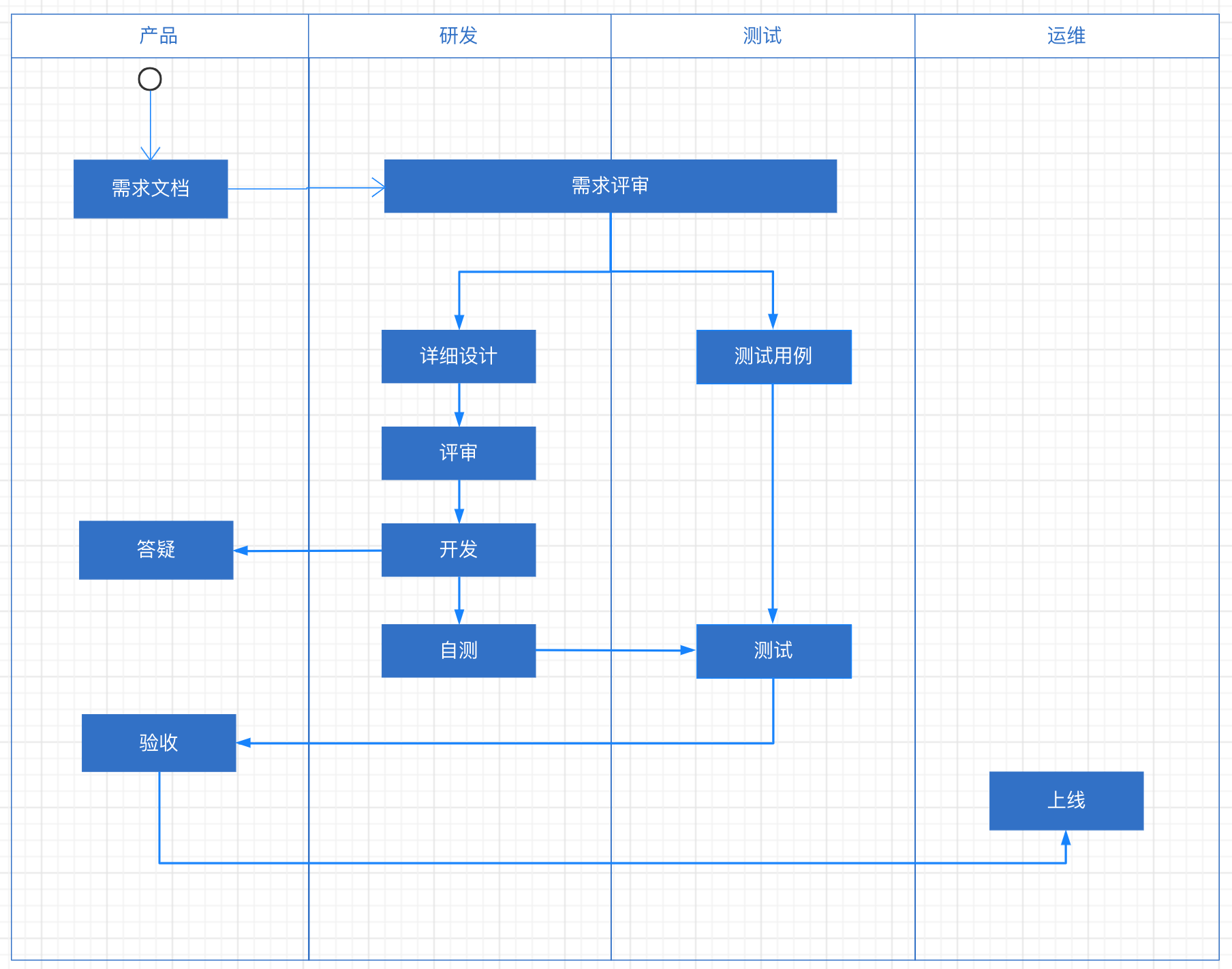
- 需求评审–》2. 详细设计–》3. 详设评审–》4. 开发 / 测试用例提交–》5. 提冒烟测试(提测验收)–》6. 功能测试–》7. bug修复–》8. 回归测试–》9. 产品验收
范围管理
一个版本固定在 2 周左右。所以,只能在版本范围上进行灵活调整。
在一个迭代期开始前,产品人员往需求池中添加近期或者中期要完成的功能需求。并按优先级进行排序。
一个迭代期开始时,产品人员和研发负责人、测试负责人一起预估各需求需要的时间。挑选一定数量的需求到当前版本中。
在后序开发过程中,如果发现功能需求描述之外的功能。按需求优先级、影响程度进行区分。如果影响功能正常使用,则紧急处理,将优化功能添加到需求池中进行排期。如果影响发布时间,要将一些优先级相对低的需求从当前版本的范围列表中移除。
如果功能提前完成,可从需求池中再添加一些功能到当前版本。
产品人员
产品人员在客户现场接收客户的需求或反馈,以及未来产品的发展方向。并整理成需求文档以及产品原型。对于复杂的业务逻辑,要提供流程图,以及场景拆解说明。交付物有:
- 功能原型。需求完整体现产品的功能,页面跳转逻辑,功能按钮。
- 需求文档。描述各个功能解决的问题,方便研发人员理解功能设计思路及功能本身。
- 场景描述说明。复杂的功能可能有多种情况,要进行分别说明。
- 业务流程图。描述数据流转流程,包括数据的来源,流转路径、逻辑,数据最终状态等。
- 异常处理机制。描述异常操作或异常数据在系统中的应对方案。
在需求评审完成后,产品人员可以开始进行下个版本需求的整理。将内容添加到整个系统的需求池中。并在研发、测试全部完后中进行功能验收。
前端研发
前端人员根据产品人员提供的产品原型以及 UE、UE 的设计,制作出静态页面,并在后端人员开发完后端数据接口后进行数据对接。
在需求评审时要理解页面、按钮等之间的关系。主要工作是:
- 需求评审
- 静态页面制作
- 数据接口对接
- bug 修复
后端研发
需求评审时会先按功能进行责任小组的划分。各责任小组针对性的对负责的功能进行详细评审理解。
各小组后端研发人员根据产品提供的需求文档、流程图、场景描述等先进行详细设计(相关数据库设计、代码组织、架构设计),然后内部进行设计评审。评审通过后进行编码工作。
数据接口开发完成后要对各个接口进行单元测试。并和前端人员进行数据接口对接。
主要工作是:
- 需求评审
- 详细设计及评审
- 功能开发及自测
- 数据接口对接
- bug 修复
测试人员
需求评审完成后,测试人员会根据内容进行测试用例的编写。并在研发人员提测后进行功能全面测试。主要工作是:
- 需求评审
- 测试用例制作
- 功能测试
运维人员
研发、测试、产品验收完成后,运维人员从指定的位置获取软件安装包,按安装文档进行现场的系统部署升级。
-
git管理规范
git规范
git人员角色
- Owner
- Master
- Developer
- Reporter
- Guest
git分支
| 分支类型 | 命名规范 | 示例 | 说明 | | — | — | — | — | — | | master | master | master | 主线分支、线上稳定版本 | | develop | develop | develop | 开发稳定版本 | | release | release/xxx | | 发布到测试环境的版本 | | hotfix | hotfix/xxx | | 特定版本,用来紧急修复线上bug | | feature | feature/xxx | | 功能开发分支,可存在多个,用来开发不同功能 |
分支管理流程
- 开发开始时,从 develop 分支拉取新的 feature 分支 和 release 分支
- 如果此次迭代的版本中有些功能要上线,有些不要上线。要将这些功能区分开,拉取不同的 feature 分支。要发布的和不发布的在不同分支上开发。
- 功能开发完成后,将要测试的功能代码合并到 release 分支上。不用发布的分支不合并。
- 从 release 分支上拉取代码,部署到测试服务器上。测试人员进行测试。
- 测试完毕后,将 release 分支合并到 develop 和 master分支。
- 从 master 分支拉取最新的代码部署到客户现场,并打 tag。
- 客户现场部署后,如果发现 bug 要紧修复。需要从 develop 分支拉取 hotfix 分支。在该分支上进行修复。修复完后合并到 release 分支进行测试。然后再进入步骤 4。
hotfix 分支使用完后可立即删除。
需要同时开发不同迭代版本的功能时,要建多个 feature 和 release 分支。
git提交规范
提交时的信息采用流行的 Angular 规范。每次提交,信息都包括三部分:Header、Body、Footer。
Header 是必须的,Body 和 Footer 可省略。
<type>: subject // 空一行 <body> // 空一行 <footer>如:
fix: 修复xx时的bug 将xx表的xx字段设定默认值Header
- type
- feat: 新增功能
- fix: 修复bug
- docs: 修改文档、注释等
- refactor: 代码重构,未新增功能、未修复bug
- build: 新增依赖、工具等
- style: 不改变代码逻辑,仅修改代码格式
- perf: 改善性能
- test: 修改测试用例
- ci: 自动化相关修改
- revert: 回滚到上个版本
- scop: 可选填,表示影响的范围
- subject: 简要说明,不超过 50 个字
Body
此次提交的详细描述,可分多行
Footer
- 不兼容的相关信息
- 关闭哪些 Issue