Memcached
Memcached 是一款被广泛利用的缓存服务。它不提供持久化,只是将数据存于内存中。用来减少数据层的访问,提升效率。
启动参数
memcached 的安装不再叙述。安装完后,它的启动可以有一些自定义的参数:
| 参数 | 说明 |
| -p | 使用的TCP端口。默认为 11211 |
| -m | 为整个服务分配的内存大小。默认是 64M |
| -vv | 用 very vrebose 模式启动,调试信息和错误输出到控制台 |
| -d | 作为 daemon 在后台运行 |
| -M | 禁用 LRU |
| -f | 设置 slab 的步长。默认是1.25 |
存储原理
memcached 采用 Slab Allocator 机制分配、管理内存: 按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把相同尺寸的 chunk 分成组。

默认情况下,一个 Slab 分配 1M 的空间。然后这 1M 会被切割成不同大小的 chunk。所以说,memcached 里一个 key 最多能存储的内容就是 1M。注意,memcached存储时会有压缩机制,而且压缩比例非常高,但对于小内容,压缩反而影响性能,需要设置memcached按内容大小自动压缩,比如小于 2k 的不压缩.如:$mem->setCompressThreshold(2000,0.2); // 当数据大于2k时,以0.2的压缩比进行zlib
chunk 的划分是有规律的。我们通过启动参数的 -f 可以控制切割的步长。默认值是 1.25,也就是说最大的 chunk 是 1M,第二大的是 1M/1.25,依此类推。
由于预告将内在分割成了不同大小的组。当有数据存储时,它会选择和存储大小最接近的 chunk 组,并在其中的空闲 chunk 里存放。
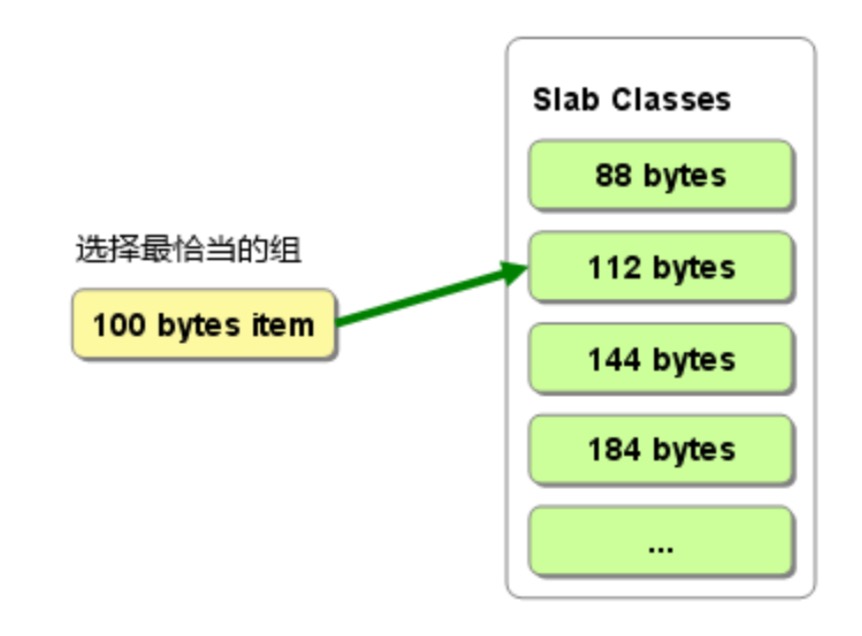
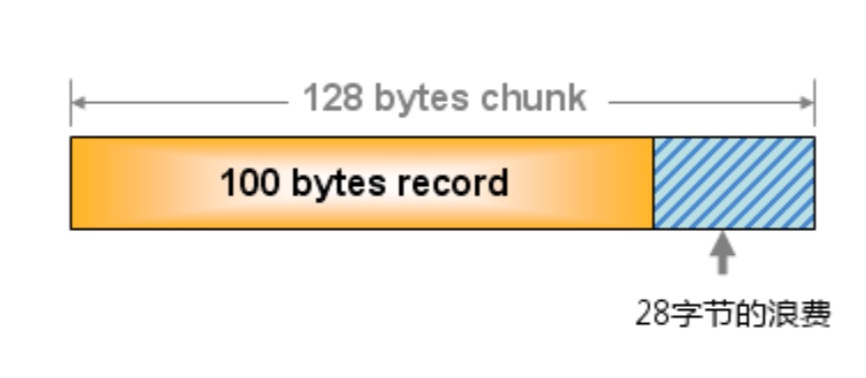
但这样就会造成一定的浪费。比如有需要存储 100byte 的内容,这时候它会选择和它最接近的 chunk ,比如选择了 128byte 大小的,那么就有 28byte 浪费了。
删除机制
memcached 不会释放已经分配的内存。记录超时后,它的空间被重复利用。而它的内部不会监视记录是否过期,而是在记录被 get 时查看是否已经过期,这种方式叫惰性过期。这样可以节省CPU资源。
当空间不足时,memcached 会通过 LRU(least recenty use)机制来分配空间,意思是:最近最少使用的被优先分配出去。
分布式–一致性哈希
memcached 虽然支持分布式的访问,但它本身并不支持,需要我们自己实现相关的分发。常用的算法是取余法。如总共有 10 台服务器,请求过来后,将 key 通过哈希算法进行运算得到整数,并将值和 10 取余,将请求分发给第余数台服务器。
这样带来的问题是,当需要添加或移出一台服务器时,受影响的 key 非常多。每台服务器上都有 key 受影响。
一致性哈希的做法是为了减少受影响的 key。它的方案是:设想有一个圆,上面有 232 个点,我们把这些点均匀的分配给所有的服务器,分配方式就是计算各服务器编号的哈希值,然后进行对应。当有请求过来时,先计算 key 的哈希值并对应到圆上的点,将这个请求分配给离该点最近的服务器。
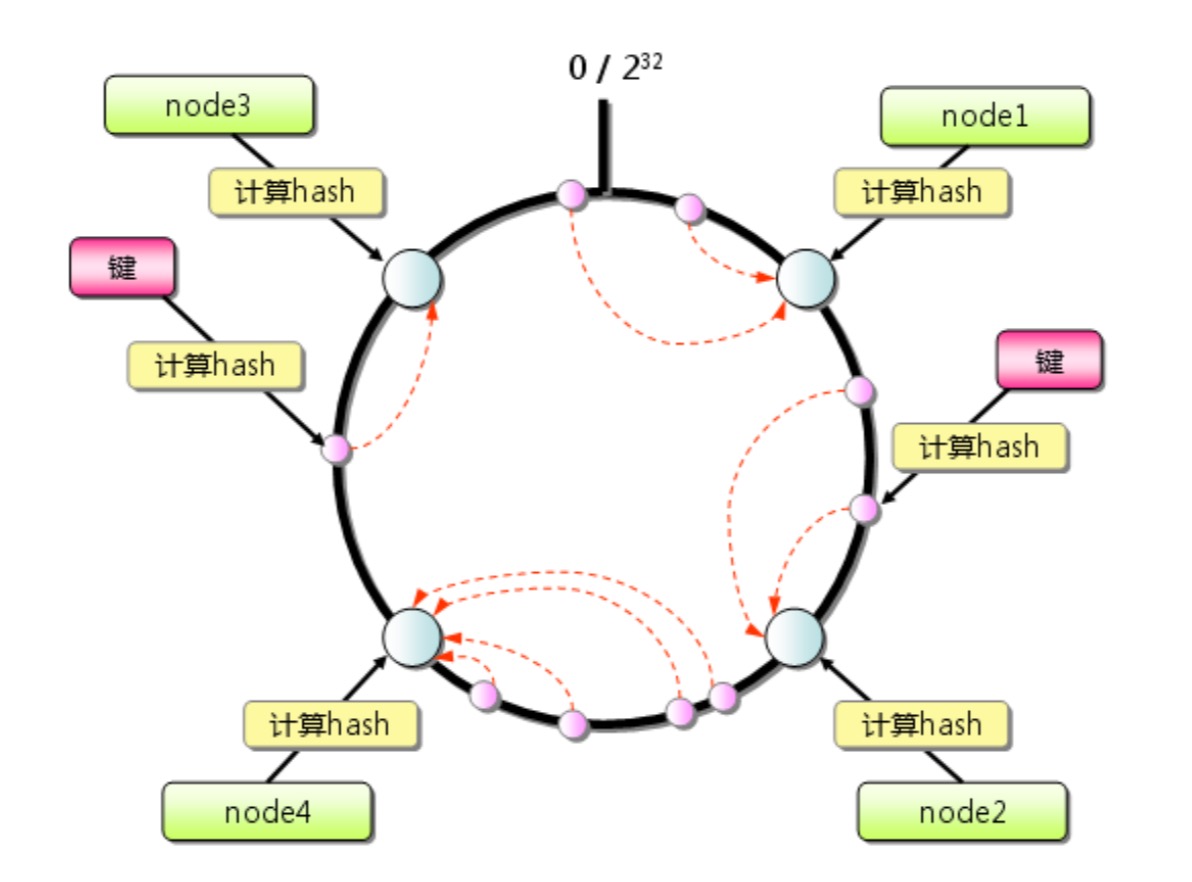
这样,如果要添加或删除节点,受影响的只有在该圆上和该节点最近的那个节点上的 key。
