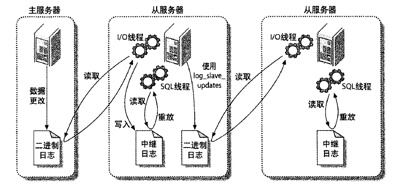
主/从复制。一台主库同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。该功能是通过 binlogs 实现的。复制有两种方式:基于语句的复制和基于行的复制。
Binlogs
二进制日志. 来记载让数据变更的日志。只有让数据有变化的语句日志才会被记录下来。
在MySQL 各库的目录下会有许多类似 mysql-bin.000001 这种文件.当然,这个是可以在 MySQL 配置文件 my.cnf 中配置的 (log-bin 和 log-bin-index).
另外,还有一个 binlog 索引文件。默认是 mysql-bin.index 用来追踪已有的 binlog 文件。以便服务器能在必要的时候创建正确的新的 binlog 文件。文件文件每一行都包括一个 binlog 文件的完整名称。
正常情况下,当数据库启动时会建一个新的 binlog 文件,也可以在命令中强行让数据库使用新的 binlog. 命令是: mysql> flush logs;
binlog 每个文件有大小限制,当达到后就会新建一个新的使用。
由于 binlog 是所有库公用的,所以会出现多个库要写入内容的情况。为避免冲突,服务器会给它建一个互斥锁。这个锁可能会阻塞某些线程。
binlog 中记录的日志顺序可能和实际语句的执行顺序不一样。这样带来的问题就是,由于 binlog 中记录的是SQL语句,而日志顺序和实际执行顺序不一样,就会导致 master 和 slave 上面数据不一致。因为顺序不一样,更新的行可能也不一样。
MySQL 除了有上面说的这种基于让数据变更的SQL语句的复制。还提供基于行的复制,它就是将变更的行保存起来。两种方式各有补充。如果一条语句改动大量的行,肯定是直接记录语句更实用。如果有多个表连接的复杂更新,直接记行更简单。
show binlog events;
可以看到日志中有哪些事件。默认它会看第一个日志文件中的事件。如果要查看指定文件的内容,如下:
mysql> show binlog events in 'mysql-bin.000005'\G
*************************** 956. row ***************************
Log_name: master-bin.000001
Pos: 147470
Event_type: Xid
Server_id: 1
End_log_pos: 147497
Info: COMMIT /* xid=4568 */
*************************** 957. row ***************************
Log_name: master-bin.000001
Pos: 147497
Event_type: Rotate
Server_id: 1
End_log_pos: 147541
Info: master-bin.000002;pos=4
所以,可以看当前正在使用的是哪个日志文件,然后看该文件中的内容
mysql> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000005 | 40862252 | payment | test,mysql |
+-------------------+----------+--------------+------------------+
查看当前主服务器的状态,该状态中 File 就是当前正在使用的文件。
关键点
binlog 到达 slave 后,将日志中的语句再执行一遍。这个时候 slave 有几个是一定要明确的:
-
当前数据库 如果语句中引用了表,函数,或存储过程,但没有指定是哪个数据库,则默认是使用当前数据库的。为解决该问题,记录日志时会多记一个字段,表示是哪个库。
-
rand 函数的种子 random 是基于伪随机数的函数,生成一系列可再生的数字。看上去是随机的,但实际上是均匀分布的。如果种子相同,rand 函数生成的值是一样的。 如果用到了该函数,binlog 会把种子记下。
-
当前时间.now() 如果master 和 slave 上执行有延迟,该函数的结果就不一样了。 now() 是返回语句开始执行时的时间。为了保证主从返回的时间一样,binlog 会记下每个事件的时间戳表明事件是何时开始执行的。
- auto_increment 的值 这个值是和上一条语句有关。 如果有用到这个的,binlog 会记下这个值。
- last_insert_id 的值 同样,这个值也取决于上条记录。 如果用到这个,binlog 会记下这个值。
- 线程 ID 如果SQL中使用了临时表或者调用了 CURRENT_ID 函数。该值可能不一样。
影响数据的SQL语句(DML): delete, insert, update 肯定会被记入 binlog 中。为了保证安全的记录日志,MySQL 在获取事务级锁时写 binlog.然后在日志写操作完成后释放锁。表未释放锁之前,在语句提交的同时将语句写入binlog。这样保证 binlog 始终与语句的更新一致。过程如下:
解析到DML –> 获得锁 –> 提交语句到引擎 & 写入 binlog –> 释放锁
影响数据库结构的SQL语句(DDL): create table, alter table 会改变数据库的结构。而我们的数据库结构是定义在库所在目录下的后缀名为 .frm 的文件中。
为了保护这些内部数据结构的更新,在修改表结构的语句执行前,要先获得锁。 而这些行为都会影响性能的。
基于语句复制
Binlogs 中记录了改变数据的SQL语句。从库将该语句重新执行一遍。而且实现起来比较简单。 缺点:一些元数据,如:rand(), now(), 等要经过特殊处理。
基于行复制
把数据更改记在 log中。明显的缺点就是日志会非常大。
MySQL 5.1 后会自动使用上面的两种方式,智能切换。默认使用基于命令复制,当检测到事件不能简单的用命令复制解决时,就采用基于行复制。也可以人为的在 my.cnf 中通过 binlog_format 变量来控制。
配置方法
配置的过程如下,找了两台局域网机器, 192.168.3.119(master) 和 192.168.3.24(slave)
master:
vi /etc/my.cnf
添加:
log-bin = master.bin
log-bin-index = master-bin.index
server-id = 1
#希望同步的数据库.有多个就写多行
binlog-do-db=payment
binlog-do-db=datacenter
#不希望同步的数据库.有多个就写多行
binlog-ignore-db=test
binlog-ignore-db=mysql
重启后再创建一个用来同步的单独用户
mysql> create user repl_user;
Query OK, 0 rows affected (0.00 sec)
mysql> grant replication slave on *.* to repl_user identified by 'root';
Query OK, 0 rows affected (0.00 sec)
slaver:
vi /etc/my.cnf
添加:
server-id = 2
relay-log-index = slave-relay-bin.index
relay-log = slave-relay-bin
#不希望同步的数据库
replicate-ignore-db=mysql
#希望同步的数据库
replicate-do-db=payment
附:可以通过该参数进行分片,即:将不同的功能放到不同的 slave 组中.
重启并在 slave 上配置:
mysql> change master to master_host = '192.168.3.119',master_port = 3306,master_user = 'repl_user',master_password='root';
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
在主库上建库,表,插入数据。看从库变化。
如果没有,在从库上用:show slave status;查看从库状态,里面可能有报错信息。
要注意的是,MySQL 安装后,可能自身的 my.cnf 就有 binlog 相关的配置,如 server-id 在进行上面的配置时要注意看一下,自己的配置会不会被默认配置给覆盖,也就是我们的配置写在上面,但后面有系统自己的配置。
在 slave status 的状态中,有两项:Slave_IO_Running 和 Slave_SQL_Running, 必须都为 Yes 才说明正常运行了。
如果是slave_io_running no了,那么就我个人看有三种情况,一个是网络有问题,连接不上,第二个是有可能my.cnf有问题。
一旦io为no了先看err日志,看看有什么错,很可能是网络,也有可能是包太大收不了,这个时候从机上改max_allowed_packet这个参数。
Slave_SQL_Running 为 No 时:
解决办法一
- 程序可能在slave上进行了写操作
- 也可能是slave机器重起后,事务回滚造成的.
一般是事务回滚造成的。解决办法:
mysql> slave stop;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> slave start;
解决办法二
首先停掉Slave服务:slave stop
到主服务器上查看主机状态,记录File和Position对应的值
mysql> show master status;
+----------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+----------------------+----------+--------------+------------------+
| master-bin.000005 | 194244 | payment | test,mysql |
+----------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
然后到slave服务器上执行手动同步:
change master to master_host = '192.168.3.119',master_port = 3306,master_user = 'repl_user',master_password='root',master_log_file='master-bin.000005',master_log_pos=194244;
工作原理
主-分发-从库
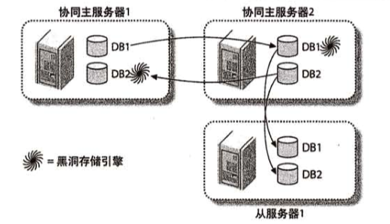
一台主库,然后一台从库,该从库使用 blackwhole 引擎,只用来记录 binlogs, 不保存数据。这时候它叫分发库,然后其它从库把分发库当主库实现同步。
多主库复制
MySQL 不支持一个从库有多个主库。而且,如果有两个主库,都对外提供写功能,两个的数据同步会有问题。这时候想到的办法是:两个都为主库,但每个库对外提供写的功能不一样。这样就不冲突了。
两个主库都有自己的独有数据,然后通过 blackwhole 引擎去同步对方的独有数据。
并行复制
在数据量较大并发量较大的场景下,主从可能会有延时。因为从库使用 单线程 重放relaylog。为了优化这种情况,MySQl 进行了优化。提供了基于多线程的并行复制。
mysql5.6 提供了 按照库并行复制, 而 mysql5.7 提供 按照GTID并行复制。
按库并行复制
主库的操作都记录在 binlogs 里。从库读取里面的内容然后在自身实例上重放。如果要多线程,肯定要把各个 log 分配到不同的线程去执行。那么,按照什么参数进行分配呢?
随机分配肯定不行。比如有这样三条记录:
update user set money=100 where uid=1;
update user set money=150 where uid=1;
update user set money=200 where uid=1;
如果随机分配,用户的余额值可能就乱了。最后的值与主库不一致。于是就有这样的思路:按库进行分配。不同的库分配到不同的线程。这就要求我们把数据切分到不同的库里,如果还是常规的单库多表,就无法利用这种策略。
当然,对于事务,mysql 会自动把事务里各个操作分为一组,进行编号。保证在从库上也是串行执行。
另外,使用多库多表后,业务分离,结构清晰。扩展方便。
按GTID的并行复制
新版的mysql,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=1
20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=2
20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=3
20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=4
和原来的日志相比,多了 last_committed 和 sequence_number。
last_committed 表示事务提交时,上次事务提交的编号,如果具备相同的 last_committed,说明它们在一个组内,可以并发回放执行。
所以 ,升级mysql吧, 并且使用“多库”架构吧!
多库多事务
我们经常使用事务来保证数据库层面数据的ACID特性。如: 对余额表,订单表,流水表的SQL操作全部成功,则全部提交,如果任何一个出现问题,则全部回滚,以保证数据的一致性。如果进行了拆库,余额、订单、流水可能分布在不同的数据库上,甚至不同的数据库实例上,此时就不能用事务来保证数据的一致性了。
主从一致性
在主从结构中,主库的 binlog 在从库上重放。但 binlog在传输上是需要时间的。特别是在一主从多的时候,容易产生延迟。如果在延迟期间产生新请求,就会出现读取到的不是新数据。
为解决这种情况,会有几种方案:
半同步复制
原理是:等主从同步完成之后,主库上的写请求再返回。实际上,数据库本身就支持这种机制。在配置主从复制的时候可以选择用哪种模式:异步、同步、半同步。
半同步带来的缺点是:主库的写请求时延会增长,吞吐量会降低。
强制读主库
可以将读和写都落到主库上。显然不符合要求。需要我们对读性能进行额外的优化。
数据库中间件
所有的读写都走数据库中间件。通常情况下,写请求路由到主库,读请求路由到从库。相当于在数据库上加了一层代理或者连接池,我们自己控制转发的逻辑。
在中间件中,记录所有路由到写库的 key,在主从同步时间窗口内(假设是500ms),如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个key上的读请求路由到主库。主从同步时间过完后,对应key的读请求继续路由到从库。
但这种方式需要自己处理中间件逻辑。要复杂一些。
缓存记录写key法
由于中间件逻辑相对复杂。于是想到用缓存:
- 将某个库上的某个key要发生写操作,记录在cache里,并设置 “主从同步时间” 的cache超时时间,例如500ms。
- 修改数据库
请求发生时的过程:
- 先到cache里查看,对应库的对应key有没有相关数据
- 如果cache hit,有相关数据,说明这个key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
- 如果cache miss,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离
扩展
向上扩展 — 也称垂直扩展,意味着购买更多性能好的硬件。见效快,但终究会有顶,而且成本也是要计算的一方面。
向外扩展
也称水平扩展。最简单的是通过复制,将数据放在多台服务器上,读写分离。复制点的就要利用到集群。
常见的如用户数据、用户发帖的切分。通常它们都会有一个自增的主键。可以根据这个主键去进行分配。觉的有:范围法 和 哈希法。
范围切分
以主键范围为基准进行切分。如:
- user-db1:存储0到1千万的uid数据
- user-db2:存储1到2千万的uid数据
范围切分的优点是:
- 切分策略简单,根据uid,按照范围,user- center很快能够定位到数据在哪个库上
- 扩容简单,如果容量不够,只要增加user-db3即可
范围法的不足是:
- uid必须要满足递增的特性
- 数据量不均,新增的user-db3,在初期的数据会比较少
- 请求量不均,一般来说,新注册的用户活跃度会比较高,故user-db2往往会比user-db1负载要高,导致服务器利用率不平衡
哈希切分
由于范围切分有诸多问题。于是就提出了哈希这种分布要平均一些的办法。将 uid 取哈希,然后再根据得到的值和数据库实例个数取模,得到的值存储到对应的实例上。
哈希法的优点是:
- 切分策略简单,根据uid,按照hash,user-center很快能够定位到数据在哪个库上
- 数据量均衡,只要uid是均匀的,数据在各个库上的分布一定是均衡的
- 请求量均衡,只要uid是均匀的,负载在各个库上的分布一定是均衡的
哈希法的不足是:
- 扩容麻烦,如果容量不够,要增加一个库,重新hash可能会导致数据迁移,如何平滑的进行数据迁移,是一个需要解决的问题
使用uid来进行哈希切分之后,对于uid属性上的查询可以直接路由到库,假设访问uid=124的数据,取模后能够直接定位db-user1:124%3 = 1。
对于非uid属性的查询,例如login_name的查询,就没办法了。解决思路是创建一个 login_name 和 uid 的索引表。先通过 login_name 查询到 uid,然后再通过 uid 去查。或者再进一步,把这个对应关系方向到 redis, memcached 等中。
哈希切分的扩容问题解决起来比较复杂。大致是分三步:冗余、扩容、收缩。
冗余是指:将现有的实例进行冗余部署。比如当前有 2 个实例db0, db1 提供服务,那么就再添加两个 db2, db3。分别为当前实例的从机。数据和主机上完全一致。db2–>db0, db3–>db1。
扩容是指:将请求从原来的 2 个实例变成现在的 4 个实例。比如之前到 db1 的,现在通过哈希算法转到了 1, 3;之前到 db0 的现在转到了 0, 2。这样就实现了扩容。而且新的数据也会被存到正确的实例上。
收缩是指:由于新增加的实例是通过冗余的方式部署的,所以db0, db1 上实际上有些数据不会被访问到,它是在 db2, db3 上的。同理,db2, db3 上也有一些数据是不需要的。这时就需要脚本去处理,清理掉。
按功能拆分
将那些将来会增长得非常庞大的数据分开来存,如用户的文章,评论,分开来存。这里看来和功能拆分相似,但它比按功能更细。但它要求的是一开始规划的时候就分好,要不然后期再来分片,就复杂了。
向内扩展
对不再需要的数据进行归档和清理。将活跃数据和非活跃数据分开处理。
数据分片
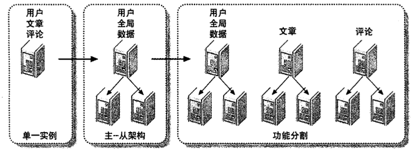
将数据按功能切分到不同的库后。同一张表也可以再进行切分。比如用户表,可以将基础数据放在一个表,将扩展信息放到另外的表。通常原则是:
- 将长度较短,访问频率较高的属性尽量放在一个表里,这个表暂且称为主表
- 将字段较长,访问频率较低的属性尽量放在一个表里,这个表暂且称为扩展表
- 经常一起访问的属性,也可以放在一个表里
数据量并发量比较大时,大表之间的查询通常不建议用 join, 而是通过多次查询。因为 join 更慢,而且 join 就意味着基础数据和扩展数据必须部署在一起,不利于扩展和拆分。
这样拆分还有一个好处是,可以充分利用数据库缓存。
因为数据库缓存是以行为单位存储的。在有限内存的情况下,一行内容越少,缓存的内容越多。这样越容易命中,以降低数据库查询。
假设数据库缓存为1G,未拆分的user表1行数据大小为1k,那么只能缓存100w行数据。
如果垂直拆分成user_base和user_ext,其中:
- user_base访问频率高(例如uid, name, passwd, 以及一些flag等),一行大小为0.1k
- user_ext访问频率低(例如签名, 个人介绍等),一行大小为0.9k
那边内存buffer就就能缓存近乎1000w 行user_base的记录,访问磁盘的概率会大大降低,数据库访问的时延会大大降低,吞吐量会大大增加。
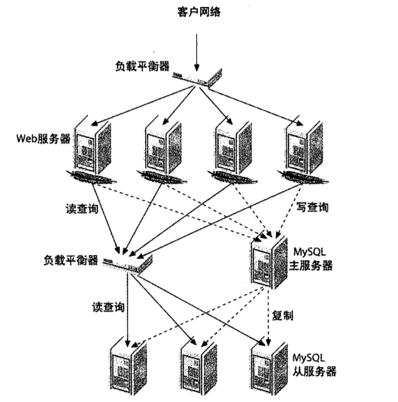
负载均衡