欢迎来到夜宇工作间
这里是我的个人IT学习回忆录-
Feed架构设计
Feed
微博,微信朋友圈,Pinterest是典型的feed流业务,系统中的每一条消息就是一个feed。
这类业务的特点是:
- 有好友关系,例如关注,粉丝
- 我们的主页由别人发布的feed组成
这类业务的典型动作是:
- 关注,取关
- 发布feed
- 拉取自己的主页feed流
这类业务的核心元数据是:
- 关系数据
- feed数据
feed流业务最大的特点是“我们的主页由别人发布的feed组成”,获得朋友圈消息feed流集合,从技术上说,主要有“拉取”与“推送”两种方式。
拉流
某feed系统里有ABCD四个用户,其中:
- A关注了BC,D关注了B
- B发布过四条feed:msg1, msg3, msg5, msg10
- C发布过两条feed:msg2, msg8
其关系存储又包含关注关系与粉丝关系,“A关注了BC,D关注了B”的潜台词是“B有两个粉丝AD,C有一个粉丝A”。
每一个用户,都有一个feed队列,记录自己曾经发布的所有feed数据。在拉模式中,发布一条feed的流程非常简单,例如C新发布了一条msg12:只需往C的feed队列里加入一条feed即可。
取消关注的流程也非常简单,例如A取消关注C:只需要在A的关注列表里删除C,并在C的粉丝列表里删除A即可。
在拉模式中,用户A获取“由别人发布的feed组成的主页”的过程及其复杂,此时需要:
- 获取A的关注列表
- 获取所关注列表中,所有用户发布的feed
- 对消息进行rank排序(假设按照发布时间排序),分页取出对应的一页feeds
feed流的拉模式的优点是:
- 存储结构简单,数据存储量较小,关系数据与feed数据都只存一份
- 关注,取关,发布feed的业务流程非常简单
- 存储结构,业务流程都比较容易理解,适合项目早期用户量、数据量、并发量不大时的快速实现
缺点也显而易见:
- 拉取朋友圈feed流列表的业务流程非常复杂
- 有多次数据访问,并且要进行大量的内存计算,网络传输,性能较低
推流
推模式,关系数据的存储与拉模式完全一样。feed数据,每个用户也存储自己发布的feed。feed数据存储,与拉流不同的是,每个用户还需要存储自己收到的feed流。如:
- B曾经发布过 1,3,5,10
- C曾经发布过 2,8
- A关注了BC,所以A的接收队列是 1,2,3,5,8,10
- D关注了B,所以D的接受队列是 1,3,5,10
在推模式中,获取“由别人发布的feed组成的主页”会变得异常简单,假设一页消息为3条feed,A如果要看自己朋友圈的第二页消息,直接返回1,2,3即可。第一页朋友圈是最新的消息,即5,8,10。
在推模式中,发布一条feed的流程会更复杂一点。
例如B新发布了一条msg12:
- 在B的发布feed存储里加入消息12
- 查询B全部粉丝AD
- 在粉丝AD的接收feed存储里也加入消息12
之所以该方案称为推模式,就是因为,用户发布feed的时候, 直接将feed推到了粉丝的接收列表里,故称为“推模式”。不止写发布feed存储,而且要写多个粉丝的接收feed存储
在推模式中,添加关注的流程也会变得复杂:
例如D新增关注C:
- 在D的关注存储里添加C
- 在C的粉丝存储里添加D
- 在D的接收feed存储里加入C发布的feed
在推模式(写扩散)中,取消关注的流程:
例如A取消关注C:
- 在A的关注存储里删除C
- 在C的粉丝存储里删除A
- 在A的接收feed存储里删除C发布的feed
feed流的推模式(写扩散)的优点是:
- 消除了拉模式的IO集中点,每个用户都读自己的数据,高并发下锁竞争少。
- 拉取朋友圈feed流列表的业务流程异常简单,速度很快
- 拉取朋友圈feed流列表,不需要进行大量的内存计算,网络传输,性能很高
其缺点是:
- 极大极大消耗存储资源,feed数据会存储很多份,例如杨幂5KW粉丝,她每次一发博文,消息会冗余5KW份
- 新增关注,取消关注,发布feed的业务流会更复杂
feed流业务的推拉模式小结:
- 拉模式,读扩散,feed存一份,存储小,用户集中访问数据,性能差
- 推模式,写扩散,feed存多份,用冗余存储换锁冲突,性能高
综合
通常为了实时性,都会采用推流的方式。但推流的方式缺点很明显就是会冗余存储。而且,如果用户的粉丝特别多,就会出现延迟。这里首先想到的肯定是异步处理。明星发帖后肯定是第一时间显示,然后使用异步任务去设置粉丝的 feed 流内容。
为了进一步提升效率,需要对粉丝进行筛选。我们做一下改进把用户分成有效和无效的用户。比如说有一百个粉丝,我发一条微博的时候不需要推给一百个粉丝,因为可能有50个粉丝不会马上来看。这样同步推送给他们,相当于做无用功。
比如当天登陆过的人标识为有效用户,我们只需要发送给这些粉丝,这样压力马上就减轻了,投递的延迟也减小了。
另外,还可以根据互动程度、关系密切程度进行一些排序,对某些用户先推。另外,还可以根据其它算法对用户进行分类,比如按注册时用户选的爱好、兴趣等,或者他之前对哪些内容进行过评论(通常系统内会对用户打上很多个标签,以此为参照)。
https://blog.csdn.net/einsteinlike/article/details/45579351
技术实现-反向 Ajax
Ajax、反向 Ajax 异步的 JavaScript 和 XML (Ajax),一种可通过 JavaScript 来访问的浏览器功能特性,其允许脚本向幕后的网站发送一个 HTTP 请求而又无需重新加载页面。 Ajax 的出现已经超过了十年,尽管其名字中包含了 XML,但您几乎可以在 Ajax 请求中传送任何的东西。最常使用的数据是 JSON,它与 JavaScript 语法非常接近且消耗更少的带宽。
反向 Ajax (Reverse Ajax) 本质上则是这样的一种概念:能够从服务器端向客户端发送数据。在一个标准的 HTTP Ajax 请求中,数据是发送给服务器端的,反向 Ajax 可以某些特定的方式来模拟发出一个 Ajax 请求,这样,服务器就可以尽可能快地向客户端发送事件(低延迟通信)。
反向 Ajax 的目的是让服务器将信息推送到客户端。Ajax 请求默认情况下是无状态的,且只能从客户端向服务器端发出请求。可以通过使用技术模拟服务器端和客户端之间的响应式通信来绕过这一限制。方法有如下几种:
HTTP 轮询
轮询 (Polling) 涉及了从客户端向服务器端发出请求以获取一些数据,这显然就是一个纯粹的 Ajax HTTP 请求。为了尽快地获得服务器端事件,轮询的间隔(两次请求相隔的时间)必须尽可能地小。
但有这样的一个缺点存在:如果间隔减小的话,客户端浏览器就会发出更多的请求,这些请求中的许多都不会返回任何有用的数据,而这将会白白地浪费掉带宽和处理资源。
用 JavaScript 实现的轮询的优点和缺点:
- 优点:很容易实现,不需要任何服务器端的特定功能,且在所有的浏览器上都能工作。
- 缺点:这种方法很少被用到,因为它是完全不具伸缩性的。试想一下,在 100 个客户端每个都发出 2 秒钟的轮询请求的情况下,所损失的带宽和资源数量,在这种情况下 30% 的请求没有返回数据。
Comet
Comet 请求被发送到服务器端并保持一个很长的存活期,直到超时或是有服务器端事件发生。 在该请求完成后,另一个长生存期的 Ajax 请求就被送去等待另一个服务器端事件。 使用 Comet 的话,Web 服务器就可以在无需显式请求的情况下向客户端发送数据。
Comet 的一大优点是: 每个客户端始终都有一个向服务器端打开的通信链路。
服务器端可以通过在事件到来时立即提交(完成)响应来把事件推给客户端,或者它甚至可以累积再连续发送。因为请求长时间保持打开的状态,故服务器端需要特别的功能来处理所有的这些长生存期请求。
XMLHttpRequest 长轮询
打开一个到服务器端的 Ajax 请求然后等待响应。服务器端需要一些特定的功能来允许请求被挂起,只要一有事件发生,服务器端就会在挂起的请求中送回响应并关闭该请求。然后客户端就会使用这一响应并打开一个新的到服务器端的长生存期的 Ajax 请求
- 优点:客户端很容易实现良好的错误处理系统和超时管理。这一可靠的技术还允许在与服务器端的连接之间有一个往返,即使连接是非持久的(当您的应用有许多的客户端时,这是一件好事)。它可用在所有的浏览器上;只需要确保所用的 XMLHttpRequest 对象发送到了简单的 Ajax 请求就可以了。
- 缺点:相比于其他技术来说,不存在什么重要的缺点,像所有我们已经讨论过的技术一样,该方法依然依赖于无状态的 HTTP 连接,其要求服务器端有特殊的功能来临时挂起连接。
建议
反向 Ajax 实现和使用 Comet 的最好方法是通过 XMLHttpRequest 对象,它提供了一个真正的连接句柄和错误处理。因此建议选择经由 HTTP 长轮询使用 XMLHttpRequest 对象(在服务器端挂起的一个简单的 Ajax 请求)的 Comet 模式,所有支持 Ajax 的浏览器也都支持该种做法。
示例: index.php:
var timestamp = 0; var url = 'backend.php'; var error = false; function connect(){ $.ajax({ data : {'timestamp' : timestamp}, url : url, type : 'get', timeout : 0, success : function(response){ var data = eval_r('('+response+')'); error = false; timestamp = data.timestamp; $("#content").append(' ' + data.msg + ' '); }, error : function(){ error = true; setTimeout(function(){ connect();}, 5000); }, complete : function(){ if (error) setTimeout(function(){connect();}, 5000); else connect(); } }) } function send(msg){ $.ajax({ data : {'msg' : msg}, type : 'get', url : url }) } $(document).ready(function(){ connect(); })backend.php:
date_default_timezone_set('Etc/GMT-8'); set_time_limit(0); error_reporting(0); $filename = 'data.txt'; $msg = isset($_GET['msg']) ? $_GET['msg'] : ''; if ($msg != '') { file_put_contents($filename,$msg); die(); } $lastmodif = isset($_GET['timestamp']) ? $_GET['timestamp'] : 0; $currentmodif = filemtime($filename); while ($currentmodif <= $lastmodif){ usleep(10000); clearstatcache(); $currentmodif = filemtime($filename); } $response = array(); $response['msg'] = file_get_contents($filename); $response['timestamp'] = $currentmodif; echo json_encode($response); flush();
-
ElasticSearch简单使用
ElasticSearch
elasticsearch 是使用 Java 编写的,并且采用了 Lucene 来实现索引与搜索的功能。在使用它做全文搜索时,只需要使用简单流畅的 RESTful API 即可,并不需要了解 Lucene 背后复杂的的运行原理。
它不仅可以实现全文搜索功能,还可以完成以下工作:
- 分布式实时文档存储,并将每一个字段都编入索引,使其可以被搜索。
- 分布式实时分析与搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
和 Solr 的区别有:
- Solr建立索引时候,搜索效率下降,实时搜索效率不高
- Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能
- Solr支持更多格式的数据,比如JSON、XML、CSV,而ES仅支持json文件格式
- Solr官方提供的功能更多,而ES本身更注重于核心功能,高级功能多有第三方插件提供
- Solr在传统的搜索应用中表现好于ES,但在处理实时搜索应用时效率明显低于ES
- 随着数据量的增加,Solr的搜索效率会变得更低,而ES却没有明显的变化
安装
JAVA 环境安装
要先安装 JAVA 环境。下载地址: http://www.oracle.com/technetwork/cn/java/javase/downloads/index-jsp-138363-zhs.html
这里我选择的是 java8,下载地址是: http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
下载的是 jdk-8u172-linux-x64.tar.gz
tar -zxf jdk-8u172-linux-x64.tar.gz mv jdk1.8.0_172/ /usr/local/jdk1.8修改 /etc/profile,在最后添加以下配置
export JAVA_HOME=/usr/local/jdk1.8 export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:. export PATH=$JAVA_HOME/bin:$PATH使文件生效:
source /etc/profile,完成后查看JAVA版本:java -version输出如下:java version "1.8.0_172" Java(TM) SE Runtime Environment (build 1.8.0_172-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)说明安装成功。
elasticsearch 安装
下载地址是: https://www.elastic.co/downloads/past-releases
这里选择的是 6.2.4 版本: https://www.elastic.co/downloads/past-releases/elasticsearch-6-2-4s
groupadd elsearch useradd elsearch -g elsearch -p ES wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz tar -zxf ES-6.2.4.tar.gz mv ES-6.2.4 /usr/local/ES chown -R elsearch:elsearch /usr/local/elasticsearch su elsearch /usr/local/elasticsearch/bin/elasticsearch运行成功后,会开启 9200, 9300 端口的监听。可以在本机执行
curl http://localhost:9200/查看内容:{ "name" : "9c8KDQF", "cluster_name" : "ES", "cluster_uuid" : "fII7r5BAQzWMnGrbw8pyMQ", "version" : { "number" : "6.2.4", "build_hash" : "ccec39f", "build_date" : "2018-04-12T20:37:28.497551Z", "build_snapshot" : false, "lucene_version" : "7.2.1", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }默认的时候,9200 端口是绑定在 127.0.0.1 的,无法在远程机器上访问。可以修改 /usr/local/elasticsearch/conf/elasticsearch.yml:
network.host: 0.0.0.0 http.port: 9200启动时提示错误:
bound or publishing to a non-loopback address, enforcing bootstrap checks node validation exception [2] bootstrap checks failed [1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]更改 /etc/security/limits.conf, 在最后加上:
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096使用
ulimit -n可以查看该值。执行
sysctl -w vm.max_map_count=655360解决 max virtual memory areas vm.max_map_count 的问题。如果出现错误:
java.lang.RuntimeException: can not run elasticsearch as root可以新建一个用户,然后以它来执行。我们的步骤中已经新建了,所以没问题。解决所有问题后,可以在远程访问了:http://[服务器IP]:9200
目前只是安装了单机版的,实际上我们可以根据需要安装集群。
管理端 Kibana 安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz tar -zxf kibana-6.2.4-linux-x86_64.tar.gz mv kibana-6.2.4-linux-x86_64 /usr/local/kibana启动:
/usr/local/kibana/bin/kibana成功后会监听 5601 端口。同样,它会默认监听 127.0.0.1,无法在外网访问。需要修改它的配置文件 /usr/local/kibana/config/kibana.yml:
server.port: 5601 server.host: "0.0.0.0"启动后,可以在外网通过 http://[服务器IP]:5601/ 来查看图形管理界面。
简单试用
对数据进行管理,可以通过SDK,RESTful API 甚至 curl 也可以。所以很灵活。如果使用 JAVA 的SDK,需要确保SDK的版本和服务端版本一致,以保证兼容。如果想要进行多语言的通用,可以使用 RESTful 的 API,它使用的是 json 格式。
curl -XGET 'http://localhost:9200/_count?pretty' 返回内容: { "count" : 0, "_shards" : { "total" : 0, "successful" : 0, "skipped" : 0, "failed" : 0 } }在 ES 中,存储数据的行为就叫做 索引(indexing) ,但是在我们索引数据前,我们需要决定将数据存储在哪里。在 ES 中,文档属于一种 类型(type),各种各样的类型存在于一个 索引 中。
一个 ES 集群可以包含多个 索引(数据库),也就是说其中包含了很多 类型(表)。这些类型中包含了很多的 文档(行),然后每个文档中又包含了很多的 字段(列)。
示例
为 megacorp 公司的员工档案创建索引。这样每个文档都代表着一个员工。为了创建员工名单,我们需要进行如下操作:
- 为每一个员工的 文档 创建索引,每个 文档 都包含了一个员工的所有信息。(相当于表中的一行数据)
- 每个文档都会被标记为 employee 类型。(相当于 表 employee)
- 这种类型将存活在 megacorp 这个 索引 中。(相当于 megacorp 库)
- 这个索引将会存储在 ES 的集群中。
在实际操作中,我们可以通过:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/1?pretty -d ' { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] } '这个简单的命令来实现。返回内容:
{ "_index" : "megacorp", "_type" : "employee", "_id" : "1", "_version" : 4, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 }这时候查看文档数:
[root@sunvipyu ~]# curl -XGET 'http://localhost:9200/_count?pretty' { "count" : 1, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 } }可以尝试多插入几条数据;
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/2?pretty -d ' { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] } ' curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/3?pretty -d ' { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] } '如果想查询某个用户的信息,可以:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/1?pretty返回结果:
{ "_index" : "megacorp", "_type" : "employee", "_id" : "1", "_version" : 7, "found" : true, "_source" : { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests" : [ "sports", "music" ] } }这里只是将前面的 PUT 方式改为了 GET,同理,如果将请求方式改为 DELETE 就表示删除文档。HEAD 表示查询文档是否存在。
如果要进行一些条件查询,就需要用 _search 命令。它会默认返回前 10 个文档。如:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/_search?pretty返回内容是:
{ "took" : 20, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 3, "max_score" : 1.0, "hits" : [ { "_index" : "megacorp", "_type" : "employee", "_id" : "2", "_score" : 1.0, "_source" : { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests" : [ "music" ] } }, { "_index" : "megacorp", "_type" : "employee", "_id" : "1", "_score" : 1.0, "_source" : { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests" : [ "sports", "music" ] } }, { "_index" : "megacorp", "_type" : "employee", "_id" : "3", "_score" : 1.0, "_source" : { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about" : "I like to build cabinets", "interests" : [ "forestry" ] } } ] } }可以看到,结果里有总的结果数 total 及各个文档的详细信息。我们还可以指定具体的过滤条件,如:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/_search?q=last_name:Smith如果还有许多查询条件一些配合,还可以用更灵活的方式,如:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/_search -d ' { "query" : { "match" : { "last_name" : "Smith" } } } '搜索结果还可以进行高亮关键词以及诸如同义词,统计汇总等一系列功能。
数据操作详细操作
对每个文档(每条信息),信息都处理成 json 格式的对象。键是一个字段或者属性的名字,值可以是一个字符串、数字、布尔值、对象、数组或者是其他的特殊类型,比如代表日期的字符串或者代表地理位置的对象。如:
{ "name": "John Smith", "age": 42, "confirmed": true, "join_date": "2014-06-01", "home": { "lat": 51.5, "lon": 0.1 }, "accounts": [ { "type": "facebook", "id": "johnsmith" }, { "type": "twitter", "id": "johnsmith" } ] }一个文档除了包括我们给它设置的信息外,还包括一些元信息(ES自我管理的一些信息)。有三个是必须存在的:
_index,_type,_id。_index表示索名称,相当于是数据库名。_type表示索引类型,相当于数据表的名称。_id是文档的唯一编号。我们可以自己提交 个唯一_id,也可以让 ES帮我们生成。通过 /_index/_type/_id,可以确认文档的唯一性。定位到某个文档上。
索引文档
我们通过API将文档添加至索引。文档被存储并可搜索。我们可以通过 PUT 操作提供相应的数据及用来确定文档唯一性的元数据,也可以让 ES 帮我们维护一个唯一的ID(通常是用 POST)。如:
1.自己维护唯一ID
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/5?pretty -d ' { "first_name" : "Test", "last_name" : "Some", "age" : 32, "about" : "Test API", "interests": [ "programe" ] } '返回内容:
{ "_index" : "megacorp", "_type" : "employee", "_id" : "5", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 }2.让 ES 自动生成唯一ID
curl -XPOST -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/?pretty -d ' { "first_name" : "AutoIncress", "last_name" : "AutoName", "age" : 32, "about" : "Test Id", "interests": [ "programe" ] } '返回内容:
{ "_index" : "megacorp", "_type" : "employee", "_id" : "k50XOWMBd_jrJmg2FhIb", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }从返回内容可以看到
_id的值。自生成ID是由22个字母组成的,安全 universally unique identifiers 或者被称为UUIDs。
访问文档
要从 ES 中获取文档,我们需要使用同样的
_index,_type以及_id但是不同的HTTP请求变成GET:curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/k50XOWMBd_jrJmg2FhIb?pretty返回内容:
{ "_index" : "megacorp", "_type" : "employee", "_id" : "k50XOWMBd_jrJmg2FhIb", "_version" : 1, "found" : true, "_source" : { "first_name" : "AutoIncress", "last_name" : "AutoName", "age" : 32, "about" : "Test Id", "interests" : [ "programe" ] } }pretty 参数是为了让返回的 json 格式显示的更容易阅读。
如果只想搜索文档中的某一些字段,不是获得所有信息,可以:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/k50XOWMBd_jrJmg2FhIb?_source=first_name,age如果只想获得我们提交的数据,不想返回元数据,可以:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/k50XOWMBd_jrJmg2FhIb/_source返回内容:
{ "first_name" : "AutoIncress", "last_name" : "AutoName", "age" : 32, "about" : "Test Id", "interests": [ "programe" ] }检测文档是否存在
如果确实想检查一下文档是否存在,你可以试用HEAD来替代GET方法,这样就是会返回HTTP头文件。如:
curl -i -XHEAD -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/k50XOWMBd_jrJmg2FhIb返回内容:
HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 266如果文档不存在,会返回 404:
HTTP/1.1 404 Not Found content-type: application/json; charset=UTF-8 content-length: 85更新文档
文档添加到索引后,如果我们数据修改了,可以重新提交:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6?pretty -d ' { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 32, "about" : "Test API Modify", "interests": [ "programe" ] } '这时候可以先用 GET 看一下索引的内容:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6?pretty { "_index" : "megacorp", "_type" : "employee", "_id" : "6", "_version" : 1, "found" : true, "_source" : { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 32, "about" : "Test API Modify", "interests" : [ "programe" ] } }然后再执行一次 PUT:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6?pretty -d ' { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 33, "about" : "Test API Modify Has Done", "interests": [ "programe" ] } '现在再 GET 一下发现内容变了:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6?pretty { "_index" : "megacorp", "_type" : "employee", "_id" : "6", "_version" : 2, "found" : true, "_source" : { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 33, "about" : "Test API Modify Has Done", "interests" : [ "programe" ] } }而且,元数据
_version从之前的 1 累加为 2。这里的_version是为了解决 ES 中类似锁机制而维护的一个元数据。当使用索引API来更新一个文档时,我们先找到了原始文档,然后修改它,最后一次性地将整个新文档进行再次索引处理。涉及到的是多次操作。
在内部,ES 已经将旧文档标记为删除并且添加了新的文档。旧的文档并不会立即消失,但是你也无法访问他。ES 会在你继续添加更多数据的时候在后台清理已经删除的文件。
创建文档
我们可以通过 /PUT 操作进行文档的索引,同时存储新文档。而且,当我们使用自定义的
_id时,如果我们多次 PUT 操作传递同一个_id时,它会覆盖之前的数据。如果我们让 ES 自己维护ID,我们可以使用 POST 提交。但是,如果我想又想要用 PUT 方式,使用自己的ID,又不想数据被覆盖,当数据已经存在时,拒绝请求。可以在 PUT时添加 op_tpe 参数,如:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6?op_type=create -d ' { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 33, "about" : "Test API Modify Has Done", "interests": [ "programe" ] } ' {"error":{"root_cause":[{"type":"version_conflict_engine_exception","reason":"[employee][6]: version conflict, document already exists (current version [2])","index_uuid":"y-xZR7W9QeeFwpBVTsGBCg","shard":"2","index":"megacorp"}],"type":"version_conflict_engine_exception","reason":"[employee][6]: version conflict, document already exists (current version [2])","index_uuid":"y-xZR7W9QeeFwpBVTsGBCg","shard":"2","index":"megacorp"},"status":409}返回了数据已存在的错误,状态码是 409。或者:
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/6/_create -d ' { "first_name" : "Test Modify", "last_name" : "Some Test", "age" : 33, "about" : "Test API Modify Has Done", "interests": [ "programe" ] } '如果创建成功,会返回常见的元数据及 201 状态:
curl -i -XPUT -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/7/_create?pretty -d ' { "first_name" : "Test PUT", "last_name" : "Some Test", "age" : 31, "about" : "Test API PUT Has Done", "interests": [ "programe" ] } ' HTTP/1.1 201 Created Location: /megacorp/employee/7 content-type: application/json; charset=UTF-8 content-length: 227 { "_index" : "megacorp", "_type" : "employee", "_id" : "7", "_version" : 3, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 9, "_primary_term" : 1 }删除文档
删除和获取文档基本上一样,只不过需要把 GET 换成 DELETE 如:
curl -i -XDELETE -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/7?pretty如果文档不存在,会返回 404 状态码及一些提示信息,如:
curl -i -XDELETE -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/77?pretty HTTP/1.1 404 Not Found content-type: application/json; charset=UTF-8 content-length: 229 { "_index" : "megacorp", "_type" : "employee", "_id" : "7", "_version" : 2, "result" : "not_found", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 15, "_primary_term" : 1 }尽管文档并不存在(”found”值为false),但是
_version的数值仍然增加了,变为 2。这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了。如果成功则返回 200 状态码及一些信息:
HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 226 { "_index" : "megacorp", "_type" : "employee", "_id" : "6", "_version" : 3, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1 }删除一个文档也不会立即生效,它只是被标记成已删除。ES 将会在你之后添加更多索引的时候才会在后台进行删除内容的清理
多版本控制
当我们更新文档时,会先 GET 到文档,然后修改它,最后一次性将整个新文档进行索引处理。
ES 会根据请求发出的顺序来选择出最新的一个文档进行保存。但是,如果你修改文档的同时其他人也发出了指令,那么他们的修改将会丢失。诸如电商系统中的库存数量的存储。特别是在集群部署的时候要注意。
通常,我们的基础数据都是存在关系数据库中,ES 只是用来进行提供搜索功能。在数据库内容变更时就会更新 ES 里的值,这时候如果有多进程并发,就可能出现同时对一个值进行变更的冲突问题。
ES 使用
_version元数据来确保所有的变更操作都被正确排序,可以参考 MySQL 里 innodb 事务的 mvcc 策略。比如,有一条数据当前的
_version的值是 1。我们提交变更时,ES 内部的操作顺序是先 GET,得到所有数据及_version的值 1。然后再执行修改,再执行索引。如果在我们执行索引前,有另外的程序已经对文档修改了,它此时的版本值是 2。这时候我们的索引程序就会报错,提示当前版本已经是 2,而我们还要修改版本 1 的内容。并返回 409 的错误码。有时候,我们需要进行冲突后的重试。可以在API上加上
retry_on_conflict来实现,如:curl -i -XPOST -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/2/_update?retry_on_conflict=5 -d '{"doc" : {"school":"someone"}}'上面表明API会重试 5 次。
局部更新
我们要更新一个文档,通过 PUT 进行重新索引。它会先 GET ,然后修改,再索引。除此之外,还可以通过 UPDATE 来做部分更新,它的流程和 PUT 一样,只不过它的操作会在一个片中完成,可以节省多次请求的开销。比如,我们要给现有数据添加新的字段,UPDATE 就很合适。如:
curl -i -XPOST -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/2/_update?pretty -d '{"doc" : {"school":"someone"}}' HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 226 { "_index" : "megacorp", "_type" : "employee", "_id" : "2", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 4, "_primary_term" : 1 }再获取数据就可以看到我们新添加的 school 的值了:
curl -i -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/2/_source?pretty HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 171 { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests" : [ "music" ], "school" : "someone" }mget 获得多个文档
mget 需要指定多个文档的
_index, _type, _id,哪怕这些文档不在同一个索引里。如:curl -XGET -H "Content-Type: application/json" http://localhost:9200/_mget?pretty -d' { "docs" : [ { "_index" : "megacorp", "_type" : "employee", "_id" : 2 }, { "_index" : "megacorp", "_type" : "employee", "_id" : 1 } ] } '返回内容:
{ "docs" : [ { "_index" : "megacorp", "_type" : "employee", "_id" : "2", "_version" : 2, "found" : true, "_source" : { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests" : [ "music" ], "school" : "someone" } }, { "_index" : "megacorp", "_type" : "employee", "_id" : "1", "_version" : 7, "found" : true, "_source" : { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests" : [ "sports", "music" ] } } ] }如果要找的文档都在同一个索引或类别中,可以在 url 中指定这些,如:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/_mget?pretty -d' { "docs" : [ { "_id" : 2 }, { "_id" : 1 } ] } '甚至进一步简化为:
curl -XGET -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/_mget?pretty -d' { "ids" : [ "2", "1"] } '注意:请求多个文档时,如果有某个文档不存在,不会影响其它文档的返回。而且,就算所有文档都没找到。请求返回的HTTP状态码还是 200,因为对于 mget 这个操作来说,它是成功了。
bulk 批量操作
mget 可以同时获得多个文档,如果我们想做多个操作打包处理。可以使用 bulk。如:
curl -i -XPOST -H "Content-Type: application/json" http://localhost:9200/_bulk?pretty -d ' { "delete": { "_index": "megacorp", "_type": "employee", "_id": "1" }} { "create": { "_index": "megacorp", "_type": "employee", "_id": "9" }} { "first_name": "bulk name" } { "update": { "_index": "megacorp", "_type": "employee", "_id": "2", "_retry_on_conflict" : 3} } { "doc" : {"first_name" : "bulk update name"} } '这里,我们为每个子句都分别指定了
_index, _type, _id,如果操作的数据是同一个索引或类型的,我们也可以直接在 url 里指定,如:curl -i -XPOST -H "Content-Type: application/json" http://localhost:9200/megacorp/employee/_bulk?pretty -d ' { "delete": { "_id": "1" }} { "create": { "_id": "9" }} { "first_name": "bulk name" } '返回内容:
HTTP/1.1 200 OK Warning: 299 Elasticsearch-6.2.4-ccec39f "Deprecated field [_retry_on_conflict] used, expected [retry_on_conflict] instead" "Mon, 07 May 2018 07:15:35 GMT" content-type: application/json; charset=UTF-8 content-length: 1132 { "took" : 119, "errors" : false, "items" : [ { "delete" : { "_index" : "megacorp", "_type" : "employee", "_id" : "1", "_version" : 8, "result" : "deleted", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 16, "_primary_term" : 2, "status" : 200 } }, { "create" : { "_index" : "megacorp", "_type" : "employee", "_id" : "9", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 2, "status" : 201 } }, { "update" : { "_index" : "megacorp", "_type" : "employee", "_id" : "2", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 5, "_primary_term" : 2, "status" : 200 } } ] }每个子请求都被单独执行。但当有任何一个执行有问题时,结果的 error 都会返回 true。具体错误信息会在各个子句的结果里显示出来。
通常,使用 bulk 是为了提升性能。但,ES运行时使用的内存是有限的,当 bulk 的内容太长时,留给其它功能使用的内存就不够了。所以 bulk 的值不要太多。可以尝试使用 500 (根据每个文档的数据量而定),然后观测监控数据,如果性能没影响,则可以增加,当增加到性能出现下降时,就可以适当减少一点并稳定。
-
oauth-php-server 部署
oauth-php
利用 bshaffer/oauth2-server-php 部署自己的 oauth 服务。https://github.com/bshaffer/oauth2-server-php
初始化测试项目
mkdir my-oauth2 cd my-oauth2 git clone https://github.com/bshaffer/oauth2-server-php.git -b master或者在自己项目里:
require bshaffer/oauth2-server-php "^1.10"或直接设置 composer.json:
require": { "php": ">=7.1.0", "bshaffer/oauth2-server-php": "^1.10" },然后 composer install.如果采用 composer 管理,后面代码里引用的方式就会不大一样。要引入 vendor/autoload.php
创建认证用的库
创建一个数据库,如
oauth2dbCREATE TABLE oauth_clients ( client_id VARCHAR(80) NOT NULL, client_secret VARCHAR(80), redirect_uri VARCHAR(2000), grant_types VARCHAR(80), scope VARCHAR(4000), user_id VARCHAR(80), PRIMARY KEY (client_id) ); CREATE TABLE oauth_access_tokens ( access_token VARCHAR(40) NOT NULL, client_id VARCHAR(80) NOT NULL, user_id VARCHAR(80), expires TIMESTAMP NOT NULL, scope VARCHAR(4000), PRIMARY KEY (access_token) ); CREATE TABLE oauth_authorization_codes ( authorization_code VARCHAR(40) NOT NULL, client_id VARCHAR(80) NOT NULL, user_id VARCHAR(80), redirect_uri VARCHAR(2000), expires TIMESTAMP NOT NULL, scope VARCHAR(4000), id_token VARCHAR(1000), PRIMARY KEY (authorization_code) ); CREATE TABLE oauth_refresh_tokens ( refresh_token VARCHAR(40) NOT NULL, client_id VARCHAR(80) NOT NULL, user_id VARCHAR(80), expires TIMESTAMP NOT NULL, scope VARCHAR(4000), PRIMARY KEY (refresh_token) ); CREATE TABLE oauth_users ( username VARCHAR(80), password VARCHAR(80), first_name VARCHAR(80), last_name VARCHAR(80), email VARCHAR(80), email_verified BOOLEAN, scope VARCHAR(4000), PRIMARY KEY (username) ); CREATE TABLE oauth_scopes ( scope VARCHAR(80) NOT NULL, is_default BOOLEAN, PRIMARY KEY (scope) ); CREATE TABLE oauth_jwt ( client_id VARCHAR(80) NOT NULL, subject VARCHAR(80), public_key VARCHAR(2000) NOT NULL );创建验证服务
创建公用的逻辑文件 server.php
require_once('App/oauth2-server-php/src/OAuth2/Autoloader.php'); /** 配置 */ $dsn = 'mysql:dbname=oauth2db;host=localhost'; $username = 'root'; $password = 'root'; // 错误报告(这毕竟是一个演示!) ini_set('display_errors', 1); error_reporting(E_ALL); OAuth2\Autoloader::register(); // 这里可以用 mysql, redis, mongodb 等多种方式.如果不是用 db,则不用建中间表 $storage = new OAuth2\Storage\Pdo(array('dsn' => $dsn, 'username' => $username, 'password' => $password)); $server = new OAuth2\Server($storage); $server->addGrantType(new OAuth2\GrantType\ClientCredentials($storage)); $server->addGrantType(new OAuth2\GrantType\AuthorizationCode($storage));token 验证服务
获取 token
1.创建文件 token.php
require_once __DIR__.'/server.php'; $server->handleTokenRequest(OAuth2\Request::createFromGlobals())->send();2.添加测试数据
INSERT INTO oauth_clients (client_id, client_secret, redirect_uri) VALUES ("testclient", "testpass", "http://localhost/");3.测试请求
curl -u testclient:testpass http://localhost:8080/token.php -d 'grant_type=client_credentials'返回数据:
{"access_token":"3e928644bc91c6522292c2704739735734052eb5","expires_in":3600,"token_type":"Bearer","scope":null}API验证
1.创建文件 resource.php
require_once __DIR__ . '/server.php'; if (!$server->verifyResourceRequest(OAuth2\Request::createFromGlobals())) { $server->getResponse()->send(); die; } echo json_encode(array('success' => true, 'message' => 'You accessed my APIs!'));2.测试请求
curl http://localhost:8080/resource.php -d 'access_token=3e928644bc91c6522292c2704739735734052eb5'返回内容:
{"success":true,"message":"You accessed my APIs!"}表明成功.把 token 改一下可以看到不成功.
三方认证服务
1.创建授权用文件 authorize.php
require_once __DIR__ . '/server.php'; $request = OAuth2\Request::createFromGlobals(); $response = new OAuth2\Response(); if (!$server->validateAuthorizeRequest($request, $response)) { $response->send(); die; } if (empty($_POST)) { exit(' <form method="post"> <label>Do You Authorize TestClient?</label><br /> <input type="submit" name="authorized" value="yes"> <input type="submit" name="authorized" value="no"> </form>'); } $is_authorized = ($_POST['authorized'] === 'yes'); $server->handleAuthorizeRequest($request, $response, $is_authorized); if ($is_authorized) { $code = substr($response->getHttpHeader('Location'), strpos($response->getHttpHeader('Location'), 'code=') + 5, 40); exit("SUCCESS! Authorization Code: $code"); } $response->send();在浏览器中访问:
http://localhost:8080/authorize.php?response_type=code&client_id=testclient&state=xyz可以看到授权是否同意的两个按钮。点击 Yes 后,会生成认证码,如:
609c064a18ae1d7780c45380dd2284f07e08628f, 该码会存在我们建好的表oauth_authorization_codes中。通过该认证码,我们可以获得 token:
curl -u testclient:testpass http://localhost:8080/token.php -d 'grant_type=authorization_code&code=609c064a18ae1d7780c45380dd2284f07e08628f'得到 token:
{"access_token":"9fa8b9bb6eef8f0a084df8c1ae5fa008aee59938","expires_in":3600,"token_type":"Bearer","scope":null,"refresh_token":"08a3fa732339b523a31439e36de7c73090b46ed6"}注意:生成的 code 只有 30 秒的有效期。如果获取 token 太晚了就过期了。
本地用户ID
三方登录成功后,我们可以把该用户记在表中,他们再请求时,我们就知道该 token 是哪个用户了。修改 authorize.php 如:
$userid = 1234; $server->handleAuthorizeRequest($request, $response, $is_authorized, $userid);这时候再在浏览器里访问
http://localhost:8080/authorize.php?response_type=code&client_id=testclient&state=xyz并授权。得到授权 code。这时候表 oauth_authorization_codes 除了记 code 外还会把用户 ID 也记下来。再请求的时候,可以通过如下逻辑得到用户ID。修改 resource.php:
if (!$server->verifyResourceRequest(OAuth2\Request::createFromGlobals())) { $server->getResponse()->send(); die; } $token = $server->getAccessTokenData(OAuth2\Request::createFromGlobals()); echo "User ID associated with this token is {$token['user_id']}";通过上面的 code 请求 token, 然后再请求 resource.php 就可以得到用户ID,如:
User ID associated with this token is 1234JWT
如果不想本地维护一份token库(不管是 db, redis, mongodb),可以使用JWT形式。它是用加密和解密的方式来处理的。所以不用本地存储。
生成公钥和密钥
openssl genrsa -out privkey.pem 2048 openssl rsa -in privkey.pem -pubout -out pubkey.pem测试文件 jwt.php
require_once('App/oauth2-server-php/src/OAuth2/Autoloader.php'); // 错误报告(这毕竟是一个演示!) ini_set('display_errors', 1); error_reporting(E_ALL); OAuth2\Autoloader::register(); $publicKey = file_get_contents('pubkey.pem'); $privateKey = file_get_contents('privkey.pem'); $storage = new OAuth2\Storage\Memory(array( 'keys' => array( 'public_key' => $publicKey, 'private_key' => $privateKey, ), 'client_credentials' => array( 'CLIENT_ID' => array('client_secret' => 'CLIENT_SECRET') ), )); $server = new OAuth2\Server($storage, array( 'use_jwt_access_tokens' => true, )); $server->addGrantType(new OAuth2\GrantType\ClientCredentials($storage)); $server->handleTokenRequest(OAuth2\Request::createFromGlobals())->send();测试访问
curl -i -v http://localhost:8080/jwt.php -u 'CLIENT_ID:CLIENT_SECRET' -d "grant_type=client_credentials"得到结果:
{"access_token":"eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJpZCI6IjI1NmExYjkzOGRhZDkzZGM2YmE1ODk0ODE3NmZjY2UzM2VmYjI2MDgiLCJqdGkiOiIyNTZhMWI5MzhkYWQ5M2RjNmJhNTg5NDgxNzZmY2NlMzNlZmIyNjA4IiwiaXNzIjoiIiwiYXVkIjoiQ0xJRU5UX0lEIiwic3ViIjpudWxsLCJleHAiOjE1MjU0MjI2NjEsImlhdCI6MTUyNTQxOTA2MSwidG9rZW5fdHlwZSI6ImJlYXJlciIsInNjb3BlIjpudWxsfQ.aEoSbwg4R2nK4MHXAImgkkP3GDAWnXE5ow8aH17VUP2vYxnj1vhjkuVAiaDXijPzLR1mdk2raPd1U4nLm1MsfeVnb7QfUsedQ_BGFyeAket97RKvbMfN0XGmzgMRcnO4M_tKjWFjYtEyvxphSFxIfAl8KMLMmXp5rGqaZxv_SkNEW3BBp4j66YDt5X6ktRtLkFUpYZAOsnCR7_z3_bz57RHz_C_amQcBRTxV0mQcKKeIVceq3Ny3ezF84GEoLBSk5z7B4VFAOpb3B6lzJLELPZGLfuocO-XzUHaSepfjZRwLAe5ywTQf9gruswWtFEMecCIPZpLZmqQbBpfln4gskA","expires_in":3600,"token_type":"bearer","scope":null}接口权限控制
如果接口和 oauth 是分开部署的。接口服务这边就只需要用到 pubkey。首先,我们请求 oauth 服务,得到 token,然后带着 token 去请求接口,jwt_resource.php:
require_once('App/oauth2-server-php/src/OAuth2/Autoloader.php'); // 错误报告(这毕竟是一个演示!) ini_set('display_errors', 1); error_reporting(E_ALL); OAuth2\Autoloader::register(); $publicKey = file_get_contents('pubkey.pem'); // no private key necessary $keyStorage = new OAuth2\Storage\Memory(array('keys' => array( 'public_key' => $publicKey, ))); $server = new OAuth2\Server($keyStorage, array( 'use_jwt_access_tokens' => true, )); if (!$server->verifyResourceRequest(OAuth2\Request::createFromGlobals())) { exit("Failed"); } echo "Success!";请求:
curl "http://localhost:8080/jwt_resource.php?access_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJpZCI6IjExZmQ1MjY3ZDUyNWU2NzlmYTExMjdhZmJhNmE5NmZhNWJkNDIzNGIiLCJqdGkiOiIxMWZkNTI2N2Q1MjVlNjc5ZmExMTI3YWZiYTZhOTZmYTViZDQyMzRiIiwiaXNzIjoiIiwiYXVkIjoiQ0xJRU5UX0lEIiwic3ViIjpudWxsLCJleHAiOjE1MjU0MjMxODUsImlhdCI6MTUyNTQxOTU4NSwidG9rZW5fdHlwZSI6ImJlYXJlciIsInNjb3BlIjpudWxsfQ.ZLNpLTqNIZwCrrxTZvG6O9xQ0jipCRUL2fyXiIaLkTQBL08OrjHV6WYBv9Ibzn6ce75x615DDRzsJU8cDZ6vAcIxlRb9c9OB6glJAiVIl6cZVHzQmnwbWiXssjUZgSEoYeKu0vkkwRLk1G77woFqg9soqG6XQwKbVnEitF7n9bkR0lPk4ue-4rINJ3jsed8PzgVWbeW-7SWmERmRrZA_QWagRZGUTzjGE8CXkhOXKyLgu3VIdpYaor3n3e6doPTQz2aq1XPYDOq7tf3rCxGdWEsEFX1Ia6_L_8oQNETvBYIapMIrc7TYi5MaAHUH4CmWWVakuG7okcFONMvJMj8RPA"
-
项目数据库管理doctrine/migrations
doctrine/migrations
thinkphp, laravel 等框架都有自己的 migration 命令行工具,方便项目开发的数据库管理工作。
但如果我们不用框架,想在自己的项目里管理,则可以用
doctrine/migrations安装
方法一:
composer require doctrine/migrations直接:
vendor/doctrine/migrations/bin/doctrine-migrations list 可看到命令方法二:
下载 doctrine-migrations.phar
https://github.com/doctrine/migrations/releases/download/v1.7.2/doctrine-migrations.phar php doctrine-migrations.phar list要设置数据库的配置文件或者在命令中传入数据库配置.配置文件要更合适
配置文件
migrations.xml:<?xml version="1.0" encoding="UTF-8"?> <doctrine-migrations xmlns="http://doctrine-project.org/schemas/migrations/configuration" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://doctrine-project.org/schemas/migrations/configuration http://doctrine-project.org/schemas/migrations/configuration.xsd" > <name>Maintainable Doctrine apps tutorial</name> <migrations-namespace>DoctrineMigrations</migrations-namespace> <migrations-directory>./migrations</migrations-directory> </doctrine-migrations>同时在项目根目录下创建新目录 migrations 用来存放 migration 声明文件
根目录下创建
migrations-db.php内容是:return array( 'driver' => 'pdo_mysql', 'host' => '127.0.0.1', 'user' => 'root', 'password' => 'root', 'dbname' => 'test' );测试:
php doctrine-migrations.phar migration:status执行成功后会在我们定义的库里创建一个表,名为:
doctrine_migration_versions, 里面会记录已经执行了哪些脚本php doctrine-migrations.phar migration:generate它会在上面创建的 migrations 目录下新建一个文件,如:
Version20180529075502.php内容如:
<?php declare(strict_types=1); namespace DoctrineMigrations; use Doctrine\DBAL\Migrations\AbstractMigration; use Doctrine\DBAL\Schema\Schema; /** * Auto-generated Migration: Please modify to your needs! */ final class Version20180529075502 extends AbstractMigration { public function up(Schema $schema) : void { // this up() migration is auto-generated, please modify it to your needs } public function down(Schema $schema) : void { // this down() migration is auto-generated, please modify it to your needs } }我们要在 up 和 down 里执行相应的代码,如:
<?php declare(strict_types=1); namespace DoctrineMigrations; use Doctrine\DBAL\Migrations\AbstractMigration; use Doctrine\DBAL\Schema\Schema; /** * Auto-generated Migration: Please modify to your needs! */ final class Version20180529075502 extends AbstractMigration { public function up(Schema $schema): void { // this up() migration is auto-generated, please modify it to your needs $this->addSql('CREATE TABLE t_user (id INT NOT NULL, name VARCHAR(20) NOT NULL, PRIMARY KEY(id)) ENGINE = InnoDB'); $users = array( array('name' => 'mike', 'id' => 1), array('name' => 'jwage', 'id' => 2), array('name' => 'ocramius', 'id' => 3), ); foreach ($users as $user) { $this->addSql('insert into t_user (id, name) VALUES (:id, :name)', $user); } $this->addSql('CREATE TABLE addresses (id INT NOT NULL, street VARCHAR(255) NOT NULL, PRIMARY KEY(id)) ENGINE = InnoDB'); } public function down(Schema $schema): void { // this down() migration is auto-generated, please modify it to your needs } }执行:
php doctrine-migrations.phar migration:execute 20180529075502参数就是上面文件名后面的版本号.执行成功后数据库里可以看到新建了表,表里插入了数据。
-
Composer
用于 PHP 依赖关系处理的 Composer
利用强大的开源工具从第三方库组装 PHP 项目
现在 PHP 开发人员往往依靠第三方库来帮助自己更快地构建项目。但是,软件重用的好处是有代价的:我们不仅必须管理每个应用程序安装所需的库的列表,还必须管理所创建的依赖关系树,因为所使用的库均构建于其他库之上。
其中一个解决方案是将自己所需的所有库与自己的代码放在一起。这种方式在某程度上是可行的,但所造成的麻烦往往比它解决的问题更大。如果我们需要维护自己的本地库代码,就必须通过下载新的版本,并将其加入代码中,再手动执行并进行错误修复。
最终,我们会在这些内容上做许多工作。由于这些原因,我们通常不对三方库进行更新。
PHP Extension and Application Repository (PEAR) 项目的部分设计目的是为了解决这个问题。PEAR 提供了一组配合工作的库,程序员可以为该库做出贡献。PEAR 还包括命令行工具,用于安装所需的库及其依赖关系(如果有的话)。PEAR 在很长一段时间中曾是最好的办法,并且有很多人使用它,但这个系统也有其不足之处:
PEAR 库是一些扩展,它装在操作系统里。虽然这种设计可以避免将库引入到您自己的代码中,增加维护成本。但它导致的问题也不少,我们永远不知道需要运行哪个版本的库。
2011 年 4 月,两位 PHP 开发人员(Nils Adermann 和 Jordi Boggiano)认为 PHP 的依赖关系处理问题需要有一个新的解决方案,并开始进行开发。他们在 2012 年 3 月 1 日发布了 Composer。在 Composer 中,您可以创建一个配置文件,指定应用程序所需的第三方库(无论它们被托管在哪里)。然后运行 Composer,编写 完整的应用程序:Composer 下载您指定所有的库及其所有依赖关系。
安装 Composer
Composer 是一个多平台工具。在任何基于 UNIX 或 Linux 的计算机上都可以安装:
curl -sS https://getcomposer.org/installer | phpCentOS 可以直接通过 yum 安装:
yum install composer而 mac 也可以直接
brew install composer如果是自己下载运行安装的,可以将运行后得到的执行文件放到 /usr/local/bin 下:
mv composer.phar /usr/local/bin/composer这样我们就可以全局使用该命令了
基本用法
最常见的用法是,根据第三方提供的配置,为第三方 PHP 应用程序或框架创建/下载/安装一个代码库。
例如,可以 使用 Composer 安装 phpunit及其所有依赖关系。
{ "require":{ "phpunit/phpunit":"4.8.*@dev" } }运行 Composer 的 install 命令,Composer 就会完成余下的工作。
composer installComposer 将所有的库安装到一个命名为 vendor 的文件夹,将它们与我们自己的项目代码区分开来。
在 vendor 文件夹中,它创建了一个名为 autoload.php 的文件。我们可以在项目中包括该文件,这等于为 Composer 所下载的所有库都安装了一个自动加载程序:
require 'vendor/autoload.php';Composer 如何查找库
要下载库包,Composer 首先需要知道在哪里可以找到这些软件包。信息由 Composer 存储库 提供:在线来源列出了 Internet 上提供的软件包、如何检索它们,以及它们自己的依赖关系。虽然任何人都可以维护自己的存储库,以提供对内部库的访问权限(Composer 网站为此提供了 说明),但我们通常使用的主要存储库是 Packagist(https://packagist.org/)。Packagist 提供为 PHP 中的大部分开源项目提供软件包。
要维护好这一个三方库的大集合,主要靠 PHP Framework Interop Group (原名 PHP Standards Group)。该组织是在 php[tek] 2009 会议 上成立的。成立 PHP-FIG(代表着众多流行的 PHP 应用程序和框架的一组人)就是为了看看人们的项目如何能够更好地协同工作。该合作的高潮是 PHP Standards Recommendations (PSR) 的创建,它描述库的可选标准。实现这些共同标准的库能够在一组共同的期望下互操作。
在此,感谢开源,感谢组织!
最重要的 PSR 是 PSR-0 和 PSR-4,它们促进了 Composer 的创建。这些 PSR 为类和命名空间声明一个共同的命名方法,以及它们应该如何将文件映射到文件系统上。然后,一个共同的自动加载程序接口可以从它需要的任何库加载类。创建一个通用的标准方式,让库不需要覆盖彼此就可以共享它们的类,这使得 Composer 变得非常有效。
为自己的项目配置 Composer
我们开始编写一个新的 PHP 小程序,能够将 Markdown 文件转换为 HTML 输出。在 Packagist 搜索 markdown,显示 michaelf/php-markdown 库作为一个不错的选择。
为了告诉 Composer 在项目中要包括哪些文件,创建一个名为 composer.json 的配置文件。这个 JSON 格式的文件可以包含各种命令,但最常用的(而且往往是唯一的)命令是 require 键。将想要的软件包名称以及将要支持的版本传递给这个键:
{ "require":{ "michelf/php-markdown":"1.4.*" } }现在,在我们的应用程序目录中运行
composer install。 Composer 需要几分钟来下载指定的库到一个 vendor 目录中,并创建一个包括此目录的自动加载程序。执行完后可以看到当前目录下有了 vendor 目录,它的结构如下:
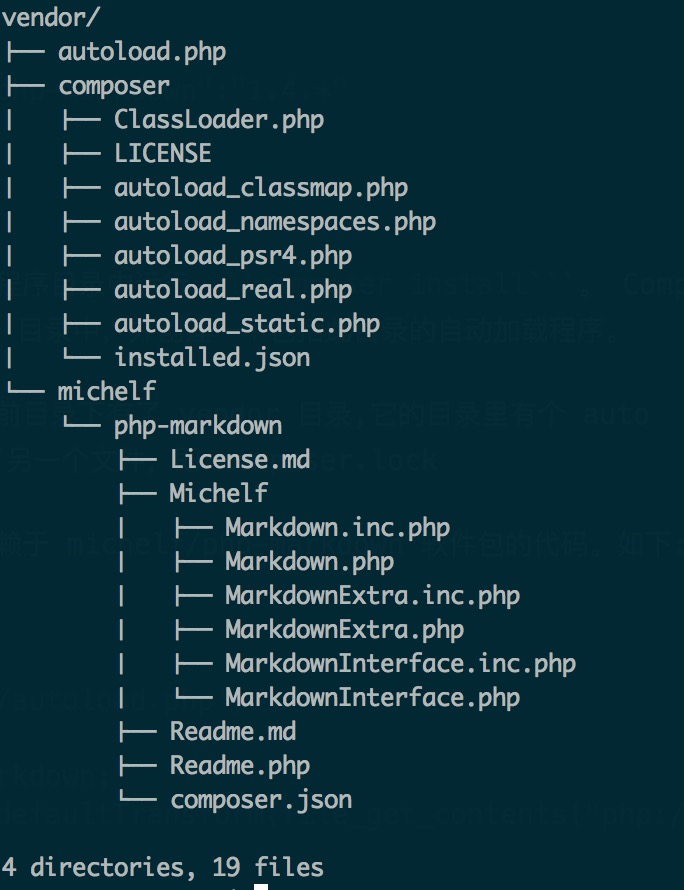
现在我们可以编写依赖于 michelf/php-markdown 软件包的代码。如下:
test.php
<?php require 'vendor/autoload.php'; use \Michelf\Markdown; echo Markdown::defaultTransform(file_get_contents("php://stdin"));我们运行上面的代码:
php test.php这时候我们可以在终端上输入文字。我们要输入的是 markdown 格式的内容,输入完后按 ctrl+d 终止。程序会输出相应的 html 代码,如:
hello === ```yum install composer``` 下面的是输出的内容: <h1>hello</h1> <p><code>yum install composer</code></p>项目运行成功! 我们选择的 Markdown 包碰巧没有额外的依赖关系。如果我们选择了一个有依赖关系的软件包,Composer 将在同一时间自动下载所有这些依赖关系并配置它们。
指定版本
我们可以根据自己的需求,将任意数量的库添加到 composer.json 文件。此外,对于每一个库,都可以指定想接受的版本。指定版本是一个很重要的部分,可以确保代码始终可用。通过在版本号中使用通配符,甚至可以允许 Composer 以我们的名义升级库。
在前面的示例中,我指定的版本为 “1.4.“。现在,每当运行 composer install 时,Composer 将查找 1.4 版库的最新版本,但不会接受 1.5、2.0 或其他任何更高版本。如果我希望总是获得库的最新版本,那么我可以指定 ““(但如果库底层 API 被更改,这可能会引起问题,又要我们自己适配)。
指定版本的方式还有几种,分别是:
确切版本 1.0.2 软件包的确切版本。 范围 >1.0 >=1.0 <2.0 >=1.0 <1.1 || >=1.2 比较运算符可以指定有效版本的范围。有效的运算符是 >、>=、<、<= 和 !=。可以定义多个范围,而且默认情况下按照 AND 处理,或者用双竖线 (||) 分开它们,则作为一个 OR 运算符。 连字符范围 1.0 - 2.0 创建一个包容性的版本集。 通配符 1.0.* 带有 * 通配符的模式。1.0.* 相当于 >=1.0 <1.1。 波浪运算符 ~1.2.3 “下一个重要版本”:允许最后一位数字增加,因此变得和 >=1.2.3 <1.3.0 一样。允许最后一位数字增加。 ^运算符 ^1.2.3 “下一个重要版本”:类似于波浪线运算符,但假设语义版本和直到下一个主要版本的所有变更都应该被允许,因此变得和 >=1.2.3 <2.0 一样。 软件包稳定性
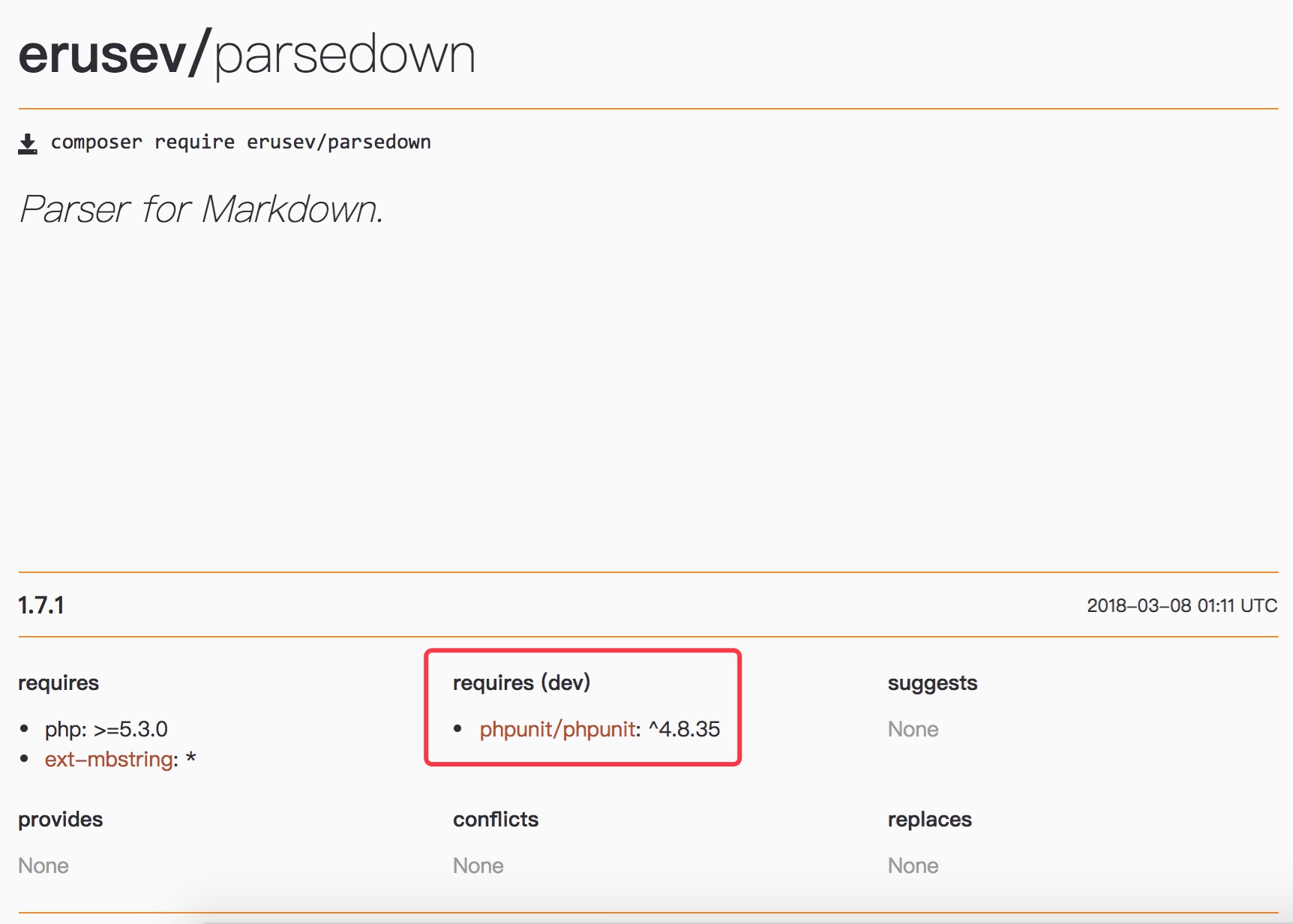
在配置 Composer 获取项目所需要的准确的库时,另一个要考虑的因素是想要的库版本有多稳定。如果需要最新的版本或正在帮助测试软件,那么可以请求软件包的测试版或开发分支。我们可以指定稳定性标志,将它添加到 require 字符串的末尾,并使用 @。例如,为了请求 PHPUnit 的最新开发版本,可以指定:
{ "require":{ "phpunit/phpunit":"4.8.*@dev" } }对于引用,Packagist 显示存在哪些分支,以及引用它们需要使用的字符串。packagist 的库详情页面里有标识。如:
版本锁定
使用 Composer 的巨大好处是,我们的代码中不需要包括第三方库。在发布软件时,让 Composer 为我们下载并配置所有库,从而保持代码精简。但是,可能会遇到问题: 代码要部署到 20 个服务器,代码的部署和 composer install 的运行分别在不同的时间发生,可能导致不同服务器上下载不同版本的库,其结果可能是灾难性的。
这就要求我们在配置库的版本的时候要十分注意。当然,我们也可以把该任务交给 composer.lock 文件。初次运行 composer install 时,会自动创建了一个 composer.lock 文件。该文件指定到底要安装哪些库,以及过程中下载哪些特定的版本。当我们将项目提交到版本控制软件(Git, SVN等)中的时候,提交 composer.lock 文件,而不是 vendor 目录。当准备好一个代码的新部署,并且运行了 composer install 的时候,Composer 会首先查找一个锁定文件。如果找到该文件,则会安装一个与原始安装完全相同的副本,以确保所有安装的一致性。
如果我们要升级三方库,当然可以删除整个 vendor目录以及 composer.lock 文件。也可以直接运行
composer update。Composer 会比较已安装的软件版本与锁定文件。如果在配置允许的版本范围内有新的版本可用,那就会自动为我们更新。为自己的类创建一个自动加载程序
Composer 还有许多内置的功能。其中一个最好的功能是,我们可以在配置中指定自己的类,使得 Composer 可以自动在自动加载程序中生成相应的代码。更改一下 composer.json:
{ "require":{ "michelf/php-markdown":"1.4.*" }, "autoload":{ "psr-4":{"Converter\\":"src/"} } }我指定了一个名为 Converter 的命名空间,并说明该命名空间的所有类文件均存在于名为 src 的相对目录中。
将之前生成的 vendor 目录删除。然后重新执行
composer install。这时候会重新下载一份库,并且生成自动加载的代码(在 vendor/composer 目录中)。其中,目录中有一个 autoload_psr4.php 文件,它里面有如下代码:
<?php // autoload_psr4.php @generated by Composer $vendorDir = dirname(dirname(__FILE__)); $baseDir = dirname($vendorDir); return array( 'Converter\\' => array($baseDir . '/src'), );可以理解为:已经帮我们做好了 Converter 全名空间里各类自动加载的定义。
所以,如果我有一个名为 Converter\CommandLine 的类,自动加载程序将会查找这个类,它在文件系统中的地址是 src/CommandLine.php。
提供自己的软件包
此时,我可以将 Markdown 到 HTML 的转换器应用程序提供为一个 Packagist 上的软件包。(由于转换器是一个应用程序,而不是一个可重用的库,将它作为一个软件包提供并没有实际意义,但是,为了本练习的需要,我们假装它是一个库)。
从本质上讲,通过创建我的 composer.json 文件,该应用程序本身是一个软件包,可以安装它。
包名称的格式必须是 vendor/package。所以,在我的例子中,我将下面的代码添加到配置文件:
"name":"EliW/Converter",其他一些配置也值得补充。可以将所需的 PHP 版本指定为 Composer 将执行的虚拟软件包名称。为了指定 PHP 版本号,并将我自己的转换器打包为完整的软件包:
{ "name":"EliW/Converter", "require":{ "michelf/php-markdown":"1.4.*", "php":">=5.3.0" }, }配置现在是完整的。可以将自己的应用程序提交给一个在线版本控制系统(如 GitHub),然后登录到我的 Packagist 帐户,并提交我的软件包信息,让其他人可以将我的应用程序包含在他们的项目中。
使用国内镜像
有两种方式启用本镜像服务:
- 系统全局配置: 即将配置信息添加到 Composer 的全局配置文件 config.json 中。
- 单个项目配置: 将配置信息添加到某个项目的 composer.json 文件中。
全局配置
打开命令行窗口(windows用户)或控制台(Linux、Mac 用户)并执行如下命令:
composer config -g repo.packagist composer https://packagist.phpcomposer.com当前项目配置
打开命令行窗口(windows用户)或控制台(Linux、Mac 用户),进入你的项目的根目录(也就是 composer.json 文件所在目录),执行如下命令:
composer config repo.packagist composer https://packagist.phpcomposer.com上述命令将会在当前项目中的 composer.json 文件的末尾自动添加镜像的配置信息(你也可以自己手工添加):
"repositories": { "packagist": { "type": "composer", "url": "https://packagist.phpcomposer.com" } }以 laravel 项目的 composer.json 配置文件为例,执行上述命令后如下所示(注意最后几行):
{ "name": "laravel/laravel", "description": "The Laravel Framework.", "keywords": ["framework", "laravel"], "license": "MIT", "type": "project", "require": { "php": ">=5.5.9", "laravel/framework": "5.2.*" }, "config": { "preferred-install": "dist" }, "repositories": { "packagist": { "type": "composer", "url": "https://packagist.phpcomposer.com" } } }镜像原理
一般情况下,安装包的数据(主要是 zip 文件)一般是从 github.com 上下载的,安装包的元数据是从 packagist.org 上下载的。
然而,由于众所周知的原因,国外的网站连接速度很慢,并且随时可能被“墙”甚至“不存在”。
“Packagist 中国全量镜像”所做的就是缓存所有安装包和元数据到国内的机房并通过国内的 CDN 进行加速,这样就不必再去向国外的网站发起请求,从而达到加速 composer install 以及 composer update 的过程,并且更加快速、稳定。因此,即使 packagist.org、github.com 发生故障(主要是连接速度太慢和被墙),你仍然可以下载、更新安装包。
-
Git 常用命令
git
CVS、SVN 底层采用的为增量式文件系统,当文件变动发生提交时,该文件系统存储的是文件的差异信息。
Git 底层文件系统存储的则为文件快照,即整个文件内容,并保存指向快照的索引,如果文件内容没有发生任何变化,该文件系统则不会重复保存文件,只是简单地保存文件的链接。
Git 分支本质上是一个指向索引对象的可变指针,而每一个索引对象又指向文件快照。这样一来,创建分支可以瞬间完成,几乎不需要花费太多代价。换句话说,Git 分支是廉价的、轻量级的。我们看看各种 CVS、SVN 项目,分支通常意味着源代码的完整拷贝,其代价是昂贵的、重量级的。
CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统。
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内效率还能接受,可如果在互联网上,遇到大文件就很吃力了。
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。那多个人如何协作呢?比如你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,只需把各自的修改推送给对方,就可以互相看到对方的修改了。
在实际使用中,其实很少在两人之间的电脑上推送版本库的修改。通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
创建版本库
mkdir -p /data/git/testproject cd /data/git/testproject git config --global user.name "sun86yu" git config --global user.email wuxuegang.123@163.com git init瞬间Git就把仓库建好了,这时候是一个空的仓库(empty Git repository),而且当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的,千万不要手动修改这个目录里面的文件。
向缓冲区提交文件
git add f1.txt f2.txt这里提到了”缓冲区”的概念。因为执行上述命令后并没有真正提交到服务器,而是提交到缓冲区。我们可以执行多次 add 命令,分批把多个新加或修改过的文件添加到缓冲区,然后一次性提交到版本库。
提交版本并注释,将缓冲区的文件提交
git commit -m 'add 2 files'查看版本库状态
查看当前版本库里是否有文件未提交等.
git status查看修改的内容
git diff放弃变更
如果已经将文件提交到缓冲区,但想放弃,想后面再提交。可以通过该命令取消。
git reset -- f1.txt如果不加文件参数表示撤销所有缓冲区里的内容。
查看某文件或者整个库的提交记录
git log [f1.txt]图形查看提交记录
git log --graph --pretty=oneline --abbrev-commit向前回滚 N 个版本
git reset -hard HEAD~1查看操作记录
git reflog可以看到之前的各个操作及版本号。版本号可以用来后面的回滚。
回滚到某个版本
git reset -hard 263972a放弃工作区内的变更
相当于用版本库里的文件覆盖本地工作区内的文件
git checkout -- readme.txt删除文件
git rm f2.txt git commit创建分支并切换到该分支
git checkout -b dev这时候通过
git status可以看出当前是在 dev 分支下查看分支情况
git branch列出所有分支(主干也是一个分支)。当前所在分支前用星号表示
切换到某分支
git checkout master合并某分支到当前分支
git merge [--no-ff] -m 'mergh branch' dev加上–no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并
删除分支
git branch -d dev强行删除某分支
git branch -D dev隐藏现场
如果有修改,但不想提交,可以先隐藏现场。或者本地对代码做了一些修改,但这时候需要远程更新代码。这种情况下如果直接更新,会提示无法进行操作。可以先隐藏,然后再更新,接着再恢复现场。
git stash可以多次执行该动作。不同的现场会有不同编号。
恢复现场
git stash apply恢复后,现场记录还存在。后面还可以再恢复。
恢复现场并删除现场记录
git stash pop这时候现场内容已经删除。
恢复指定现场
git stash apply stash@{0}把本地库和远程库关联
git remote add origin https://youserver/youproject.git git remote add origin git@121.40.168.157:/home/git/mining_admin.gitorigin 相当于是远程库的别名。我们可以给一个远程库建多个别名。如:
git remote add origin https://youserver/youproject.git git remote add myremote https://youserver/youproject.git后续我们往远程库推送版本或更新版本时都会用别名。
提交版本到远程库
git push [-u] origin master从远程库更新
git pull git@github.com:sun86yu/remotetest.git git pull origin master如果是更新到同名的库,则只需要写远程库的分支名。如果分支不同,则需要指明。
从远程库 dev 更新文件到本地的 master.
git pull origin dev:master和远程仓库解除绑定 —
git remote remove origin在本地创建和远程分支对应的分支
git checkout -b branch-name origin/branch-name将本地分支与远程库的关联
git branch --set-upstream branch-name origin/branch-name查看远程库信息
git remote -v给当前分支打标签
git tag v1.0打标签可以方便我们快速的查询。通常在一些重要的发布节点可以进行标记。上面命令执行后会给当前版本最近的一次提交打上标签。我们也可以给之前的某一次提交打上标签。
git tag v0.9 6224937后面的参数是提交的ID值.通过提交记录可以查到
查看所有标签
git tag查看提交记录
git log --pretty=oneline --abbrev-commit查看某标签的详细信息
git show v1.0删除标签
git tag -d v1.0将标签推到远程库
git push orgin v1.0一次性推送所有的标签到远程
git push origin --tags删除远程标签
删除远程标签时,先要删除本地标签,然后再 push 到远程
git push origin :refs/tags/v1.0git命令别名
git config --global alias.st status这样,如果想看 git 的状态,就不用写 git status 了,直接用 git st 再如:
git config --global alias.co checkout git config --global alias.ci commit git config --global alias.br branch git config --global alias.last 'log -1' git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"搭建Git服务器
远程仓库实际上和本地仓库没啥不同,纯粹为了7x24小时开机并交换大家的修改。
先选定一个目录作为Git仓库,假定是
/data/sample.git,在/data目录下输入命令:git init --bare sample.gitGit就会创建一个裸仓库,裸仓库没有工作区,因为服务器上的Git仓库纯粹是为了共享,所以不让用户直接登录到服务器上去改工作区,并且服务器上的Git仓库通常都以.git结尾。
创建一个git用户,用来运行git服务:
groupadd git useradd git -G git更改版本库目录权限:
chown -R git:git sample.git管理公钥
如果团队很小,把每个人的公钥收集起来放到服务器的/home/git/.ssh/authorized_keys文件里就是可以的。如果团队有几百号人,这时,可以用Gitosis来管理公钥。
配置完毕后就可以远程下载库了:
git clone git@server:/data/sample.git实践:
-
master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活。
-
干活都在dev分支上,比如1.0版本发布时,再把dev分支合并到 master上,在master分支打标签,发布1.0版本。
-
小伙伴们每个人都在dev分支上干活,每个人都有自己的本地版本库,时不时地往dev分支上合并就可以了
-
每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。
-
开发新功能也建一个临时分支,完成后合并到 dev,如果中途放弃,直接不合并,用
git branch -D删除分支 -
重要的提交要打标签.先 commit,再打标签。
-
忽略文件,如 eclipse的配置文件。 建立 .gitignore /Application/Runtime/*
-
上线发布:本地切换到 master,把 dev 合并到 master,把 master push 到远程。删除之前的分支(–no-ff)。
-
-
Swoole 基础
Swoole 使用纯 C 语言编写,提供了 PHP 语言的异步多线程服务器,异步 TCP/UDP 网络客户端,异步 MySQL,异步 Redis,数据库连接池,AsyncTask,消息队列,毫秒定时器,异步文件读写,异步DNS查询。 Swoole内置了Http/WebSocket服务器端/客户端、Http2.0服务器端。
它是一个 php 的扩展。
安装
Swoole-2.x需要 PHP-7.0.0 或更高版本 同时,2.x 版本默认添加了许多内置依赖,不再要求必须安装诸如 mysqld 等扩展
下载地址:
http://pecl.php.net/package/swoole这里选择 2.x 的 stable 版本: 2.1.1
wget http://pecl.php.net/get/swoole-2.1.1.tgz tar -zxf swoole-2.1.1.tgz cd swoole-2.1.1 phpize ./configure --with-php-config=/usr/local/opt/php/bin/php-config make clean make make install1.8.7或更高版本不再需要设置
--enable-async-mysql和--enable-async-httpclient. async_mysql 和 async_httpclient改为内置了其它参数有:
--enable-swoole-debug打开调试日志,开启此选项后swoole将打印各类细节的调试日志。生产环境不要启用。
--enable-sockets增加对sockets资源的支持,依赖sockets扩展。开启此参数,swoole_event_add就可以添加sockets扩展创建的连接到swoole的事件循环中。 另外Server和Client的getSocket()方法也需要依赖此编译参数。
--enable-openssl启用SSL支持,使用操作系统提供的libssl.so动态连接库
--with-openssl-dir指定openssl库的路径。–with-openssl-dir=/opt/openssl/
--enable-http2增加对HTTP2的支持,依赖nghttp2库
--enable-async-redis增加异步 Redis 客户端支持, 依赖 hiredis 库
先安装 hiredis 库
git clone https://github.com/redis/hiredis cd hiredis/ make -j make install // ldconfig--enable-mysqlnd启用mysqlnd支持,启用swoole_mysql::escapse方法。启用此参数后,PHP必须有mysqlnd模块,否则会导致swoole无法运行。
安装成功后会生成 swoole.so,将它添加到 php.ini 中
添加完后可以通过如下命令查看是否成功:
php --ri swoole 或者 php -m | grep swoole进程管理
默认使用 SWOOLE_PROCESS 模式,因此会额外创建 Master 和 Manager 两个进程。 在设置worker_num之后,实际会出现2 + worker_num个进程。 服务器启动后,可以通过kill 主进程ID来结束所有工作进程。
Swoole提供的绝大的部分模块只能用于cli命令行终端。目前只有Client同步客户端可以用于php-fpm环境下。请勿在Web环境中使用Server等模块。
案例
tcp服务器
tcp_server.php
<?php //创建Server对象,监听 127.0.0.1:9501端口 $serv = new swoole_server("127.0.0.1", 9501); //监听连接进入事件 $serv->on('connect', function ($serv, $fd) { echo "Client: Connect.\n"; }); //监听数据接收事件 $serv->on('receive', function ($serv, $fd, $from_id, $data) { echo "Client: $data"; $serv->send($fd, "Server: replay ".$data); }); //监听连接关闭事件 $serv->on('close', function ($serv, $fd) { echo "Client: Close.\n"; }); //启动服务器 $serv->start(); ?>这里就创建了一个TCP服务器,监听本机9501端口。 它的逻辑很简单,当客户端Socket通过网络发送一个 hello 字符串时,服务器会回复一个 Server: replay hello 字符串。并打印 Client: hello
swoole_server是异步服务器,所以是通过监听事件的方式来编写程序的。当对应的事件发生时底层会主动回调指定的PHP函数。
如当有新的TCP连接进入时会执行onConnect事件回调,当某个连接向服务器发送数据时会回调onReceive函数。
- 服务器可以同时被成千上万个客户端连接,$fd就是客户端连接的唯一标识符
- 调用
$server->send()方法向客户端连接发送数据,参数就是$fd客户端标识符 - 调用
$server->close()方法可以强制关闭某个客户端连接 - 客户端可能会主动断开连接,此时会触发onClose事件回调
执行程序
php tcp_server.php在命令行下运行server.php程序,启动成功后可以使用 netstat 工具看到,已经在监听9501端口。
netstat -nat | grep LISTEN通过 telnet 进行连接测试:
telnet 127.0.0.1 9501 hello Server: helloudp服务器
udp_server.php
<?php //创建Server对象,监听 127.0.0.1:9502端口,类型为SWOOLE_SOCK_UDP $serv = new swoole_server("127.0.0.1", 9502, SWOOLE_PROCESS, SWOOLE_SOCK_UDP); //监听数据接收事件 $serv->on('Packet', function ($serv, $data, $clientInfo) { $serv->sendto($clientInfo['address'], $clientInfo['port'], "Server ".$data); var_dump($clientInfo); }); //启动服务器 $serv->start(); ?>UDP服务器与TCP服务器不同,UDP没有连接的概念。启动Server后,客户端无需Connect,直接可以向Server监听的9502端口发送数据包。 对应的事件为onPacket。
$clientInfo是客户端的相关信息,是一个数组,有客户端的IP和端口等内容 调用
$server->sendto方法向客户端发送数据执行程序
php udp_server.phpUDP服务器可以使用
netcat -u来连接测试netcat -u 127.0.0.1 9502 hello Server: hello服务端打印内容:
array(4) { ["server_socket"]=> int(5) ["server_port"]=> int(9502) ["address"]=> string(9) "127.0.0.1" ["port"]=> int(51019) }http服务器
http_server.php
<?php $http = new swoole_http_server("0.0.0.0", 9501); $http->on('request', function ($request, $response) { var_dump($request->get, $request->post); $response->header("Content-Type", "text/html; charset=utf-8"); $response->end("<h1>Hello Swoole. #".rand(1000, 9999)."</h1>"); }); $http->start(); ?>Http服务器只需要关注请求响应即可,所以只需要监听一个onRequest事件。当有新的Http请求进入就会触发此事件。 事件回调函数有2个参数,一个是
$request对象,包含了请求的相关信息,如GET/POST请求的数据。另外一个是response对象,对request的响应可以通过操作response对象来完成。
$response->end() 方法表示输出一段HTML内容,并结束此请求。
0.0.0.0 表示监听所有IP地址,一台服务器可能同时有多个IP, 如127.0.0.1;本地回环IP:192.168.1.100;局域网IP:210.127.20.2 外网IP。这里也可以单独指定监听一个IP
9501 监听的端口,如果被占用,程序会抛出致命错误,中断执行。
执行程序
php http_server.php同样执行完后可以查看当前 LISTEN 的端口。 这时候在浏览器中访问:
http://127.0.0.1:9501,页面上显示 Hello Swoole. #6552websocket服务器
ws_server.php
<?php //创建websocket服务器对象,监听0.0.0.0:9502端口 $ws = new swoole_websocket_server("0.0.0.0", 9502); //监听WebSocket连接打开事件 $ws->on('open', function ($ws, $request) { var_dump($request->fd, $request->get, $request->server); $ws->push($request->fd, "hello, welcome\n"); }); //监听WebSocket消息事件 $ws->on('message', function ($ws, $frame) { echo "Message: {$frame->data}\n"; $ws->push($frame->fd, "server: {$frame->data}"); }); //监听WebSocket连接关闭事件 $ws->on('close', function ($ws, $fd) { echo "client-{$fd} is closed\n"; }); $ws->start(); ?>WebSocket服务器是建立在Http服务器之上的长连接服务器,客户端首先会发送一个Http的请求与服务器进行握手。 握手成功后会触发onOpen事件,表示连接已就绪,onOpen函数中可以得到
$request对象,包含了Http握手的相关信息,如GET参数、Cookie、Http头信息等。建立连接后客户端与服务器端就可以双向通信了。
客户端向服务器端发送信息时,服务器端触发onMessage事件回调 服务器端可以调用
$server->push()向某个客户端(使用$fd标识符)发送消息 服务器端可以设置onHandShake事件回调来手工处理WebSocket握手执行程序
php ws_server.php可以使用Chrome浏览器进行测试,JS代码为:
var wsServer = 'ws://127.0.0.1:9502'; var websocket = new WebSocket(wsServer); websocket.onopen = function (evt) { console.log("Connected to WebSocket server."); }; websocket.onclose = function (evt) { console.log("Disconnected"); }; websocket.onmessage = function (evt) { console.log('Retrieved data from server: ' + evt.data); }; websocket.onerror = function (evt, e) { console.log('Error occured: ' + evt.data); };不能直接使用swoole_client与websocket服务器通信,swoole_client是TCP客户端 必须实现WebSocket协议才能和WebSocket服务器通信,可以使用swoole/framework提供的PHP WebSocket客户端 (https://github.com/swoole/framework/blob/master/libs/Swoole/Client/WebSocket.php)
WebSocket服务器除了提供WebSocket功能之外,实际上也可以处理Http长连接。只需要增加onRequest事件监听即可实现Comet方案Http长轮询。
定时器
swoole提供了类似JavaScript的setInterval/setTimeout异步高精度定时器,粒度为毫秒级。使用也非常简单。
<?php //每隔2000ms触发一次 swoole_timer_tick(2000, function ($timer_id) { echo "tick-2000ms\n"; }); //3000ms后执行此函数 swoole_timer_after(3000, function () { echo "after 3000ms.\n"; }); ?>swoole_timer_tick函数就相当于setInterval,是持续触发的
swoole_timer_after函数相当于setTimeout,仅在约定的时间触发一次
swoole_timer_tick和swoole_timer_after函数会返回一个整数,表示定时器的ID 可以使用 swoole_timer_clear 清除此定时器,参数为定时器ID
异步任务
在Server程序中如果需要执行很耗时的操作,比如一个聊天服务器发送广播,Web服务器中发送邮件。如果直接去执行这些函数就会阻塞当前进程,导致服务器响应变慢。
Swoole提供了异步任务处理的功能,可以投递一个异步任务到TaskWorker进程池中执行,不影响当前请求的处理速度。
基于第一个TCP服务器,只需要增加onTask和onFinish,2个事件回调函数即可。另外需要设置task进程数量,可以根据任务的耗时和任务量配置适量的task进程。
async_task.php
<?php $serv = new swoole_server("127.0.0.1", 9501); //设置异步任务的工作进程数量 $serv->set(array('task_worker_num' => 4)); $serv->on('receive', function($serv, $fd, $from_id, $data) { //投递异步任务 $task_id = $serv->task($data); echo "Dispath AsyncTask: id=$task_id\n"; }); //处理异步任务 $serv->on('task', function ($serv, $task_id, $from_id, $data) { echo "New AsyncTask[id=$task_id]".PHP_EOL; for($i = 0; $i<10;$i++){ echo $task_id . " - " . $i.PHP_EOL; sleep(1); } //返回任务执行的结果 $serv->finish("$data -> OK"); }); //处理异步任务的结果 $serv->on('finish', function ($serv, $task_id, $data) { echo "AsyncTask[$task_id] Finish: $data".PHP_EOL; }); $serv->start(); ?>执行程序
php async_task.php在另外一个终端
telnet 127.0.0.1 9501 abc def bbc服务端的打印:
Dispath AsyncTask: id=0 New AsyncTask[id=0] 0 - 0 0 - 1 0 - 2 Dispath AsyncTask: id=1 New AsyncTask[id=1] 1 - 0 0 - 3 1 - 1 0 - 4 1 - 2 0 - 5 1 - 3 Dispath AsyncTask: id=2 New AsyncTask[id=2] 2 - 0 0 - 6 1 - 4 2 - 1 0 - 7 1 - 5 2 - 2 0 - 8在客户端输出的时候是可以连续输入的,而且输入后服务端马上做出影响。 但从 task 里的输出可以看出,多次任务并不是按我们的输入顺序同步执行的。而是异步。
同步tcp客户端
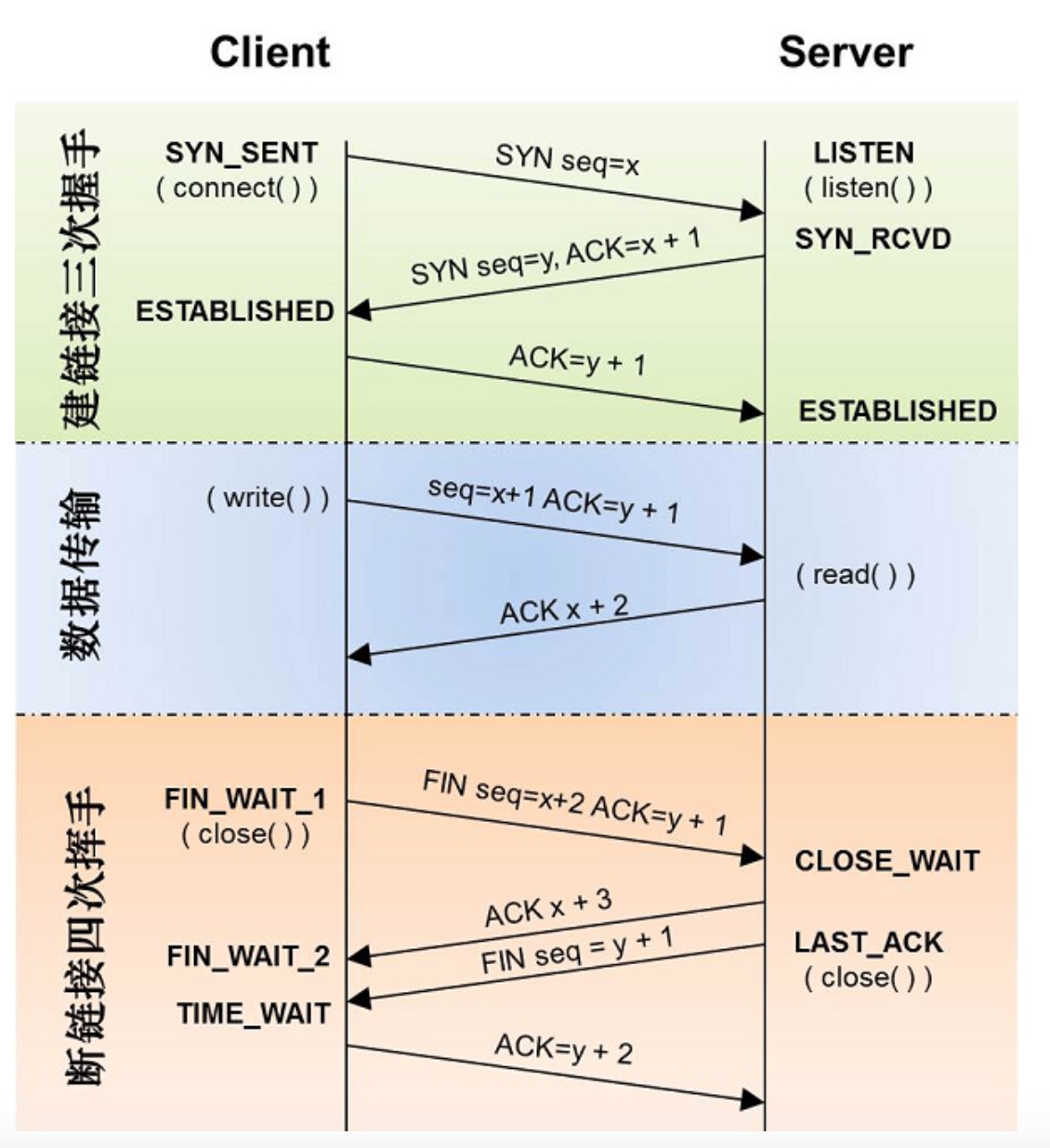
tcp_client.php
<?php $client = new swoole_client(SWOOLE_SOCK_TCP); //连接到服务器 if (!$client->connect('127.0.0.1', 9501, 0.5)) { die("connect failed."); } //向服务器发送数据 if (!$client->send("hello world")) { die("send failed."); } //从服务器接收数据 $data = $client->recv(); if (!$data) { die("recv failed."); } echo $data; //关闭连接 $client->close(); ?>先运行前面的
php tcp_server.php然后再运行php tcp_client.php当前代码会向服务端发送一个 hello world,服务端会响应一个 Server: hello world。
这个客户端是同步阻塞的,connect/send/recv 会等待IO完成后再返回。
同步阻塞操作并不消耗CPU资源,IO操作未完成当前进程会自动转入sleep模式,当IO完成后操作系统会唤醒当前进程,继续向下执行代码。
TCP需要进行3次握手,所以connect至少需要3次网络传输过程
在发送少量数据时
$client->send都是可以立即返回的。发送大量数据时,socket缓存区可能会塞满,send操作会阻塞。recv操作会阻塞等待服务器返回数据,recv耗时等于服务器处理时间+网络传输耗时之和。
断开连接时又要进行四次网络传输,即四次挥手。
异步tcp客户端
tcp_async_client.php
<?php $client = new swoole_client(SWOOLE_SOCK_TCP, SWOOLE_SOCK_ASYNC); //注册连接成功回调 $client->on("connect", function($cli) { $cli->send("hello world\n"); }); //注册数据接收回调 $client->on("receive", function($cli, $data){ echo "Received: ".$data."\n"; }); //注册连接失败回调 $client->on("error", function($cli){ echo "Connect failed\n"; }); //注册连接关闭回调 $client->on("close", function($cli){ echo "Connection close\n"; }); //发起连接 $client->connect('127.0.0.1', 9501, 0.5); ?>异步客户端与上一个同步TCP客户端不同,异步客户端是非阻塞的。可以用于编写高并发的程序。 swoole官方提供的 redis-async、mysql-async都是基于异步swoole_client实现的。
异步客户端需要设置回调函数,有4个事件回调必须设置onConnect、onError、onReceive、onClose。分别在客户端连接成功、连接失败、收到数据、连接关闭时触发。
$client->connect()发起连接的操作会立即返回,不存在任何等待。当对应的IO事件完成后,swoole底层会自动调用设置好的回调函数。异步客户端只能用于cli环境。不能用在 php-fpm 这类处理中。fpm本身是leader follower同步阻塞模型,同一时间只能处理一个请求,支持不了异步。 这样可以看出,异步客户端主要用来一些微服务化的处理。比如聊天室消息处理。 虽然异步客户端只能在 cli 环境下用,但我们可以用异步服务端。
异步 mysql 客户端
PHP提供的MySQL、CURL、Redis 等客户端是同步的,会导致服务器程序发生阻塞。 Swoole提供了常用的异步客户端组件,来解决此问题。编写纯异步服务器程序时,可以使用这些异步客户端。
异步客户端可以配合使用SplQueue实现连接池,以达到长连接复用的目的。在实际项目中可以使用PHP提供的Yield/Generator语法实现半协程的异步框架。 也可以基于Promises简化异步程序的编写。
async_mysql.php
<?php $db = new Swoole\MySQL; $server = array( 'host' => '127.0.0.1', 'user' => 'test', 'password' => 'test', 'database' => 'test', ); $db->connect($server, function ($db, $result) { $db->query("show tables", function (Swoole\MySQL $db, $result) { var_dump($result); $db->close(); }); }); ?>与mysqli和PDO等客户端不同,Swoole\MySQL是异步非阻塞的,连接服务器、执行SQL时,需要传入一个回调函数。
connect的结果不在返回值中,而是在回调函数中。query的结果也需要在回调函数中进行处理。
异步 redis 客户端
async_redis.php
<?php $redis = new Swoole\Redis; $redis->connect('127.0.0.1', 6379, function ($redis, $result) { $redis->set('test_key', 'value', function ($redis, $result) { $redis->get('test_key', function ($redis, $result) { var_dump($result); }); }); }); ?>异步 http 客户端
async_http.php
<?php $cli = new Swoole\Http\Client('http://www.edeng.cn', 80); $cli->setHeaders(array('User-Agent' => 'swoole-http-client')); $cli->setCookies(array('test' => 'value')); $cli->post('/', array("test" => 'abc'), function ($cli) { var_dump($cli->body); $cli->get('/index.php', function ($cli) { var_dump($cli->cookies); var_dump($cli->headers); }); }); ?>注意事项
常见问题
不要在代码中执行sleep以及其他睡眠函数,这样会导致整个进程阻塞
exit/die是危险的,会导致Worker进程退出
PHP代码中如果有异常抛出,必须在回调函数中进行try/catch捕获异常,否则会导致工作进程退出
类/函数重复定义
由于Swoole是常驻内存的,所以加载类/函数定义的文件后不会释放。
因此引入类/函数的php文件时必须要使用include_once或require_once,否会发生cannot redeclare function/class 的致命错误。
异步编程
异步程序要求代码中不得包含任何同步阻塞操作
异步与同步代码不能混用,一旦应用程序使用了任何同步阻塞的代码,程序即退化为同步模式
-
锦标赛排序算法
锦标赛排序
利用二叉树这个数据结构,或者说工具,我们就能实现一个经典的计算机算法,叫做锦标赛排序算法。 顾名思义,它是受到体育比赛的启发想出来的。
在单淘汰的锦标赛中,选手们两两比赛,胜者晋级,败者被淘汰。比如世界乒乓球锦标赛或者大满贯网球赛就是这么进行的。
这样一来,就可以把比赛的赛程和结果对应成一个二叉树。在树中每一个选手是二叉树中的一个叶子结点,每一场比赛就相当于两个数字在比大小。数字大的选手获胜进入下一轮,也就是说比大小,大的那个选手,进入上一层,成为枝干上的根。
所以,进入到某一轮比赛的选手,其实都是某个子树干的根结点。最后的冠军自然就是整个二叉树的根结点。当然,这种赛制的合理性来自下面一个假设:如果张三赢了李四,李四赢了王五,那么张三一定能赢王五。 也就是说:A>B, B>C, 那么必然有A>C。我们不妨称这种合理的假设为“输赢的传递性”。
只要上面这种胜负的传递性成立,通过这种比赛的结果得到的冠军,一定是最好的选手。但是,第二名是否如此,就难说了。因为冠军一路打下来,被他刷掉的选手可能水平都不差,只是运气不好,提前遇到他了,在决赛之前被淘汰了。
比如说在某次网球比赛中,德约科维奇(人称小德)半决赛赢了费德勒,决赛赢了纳达尔。小德的冠军,不会有什么异议,但你说到底是纳达尔该得亚军,还是费德勒更厉害,还真不好说。费德勒只能怪自己那次抽签运气不好。因此,如果真要较真,就需要把被冠军淘汰下来的人放到一个组里再相互比赛,才能知道谁是亚军。当然,如今体育比赛规则已经成型,大家遵守就好,不必那么麻烦赛出第二名。
但是,在工程中如果要对比两个数字的大小,总不能说哪个数字最后被最大的比下去,就是第二大的吧。因此,如果采用类似锦标赛的方法排出了一、二、三名来,第一大的数字可以完全按照锦标赛淘汰制的方式来。但是第二大的数字,就需要从所有与最大数字比较过被淘汰的数字中,再次比较选择才能确定。当第二大的数字确定后,就可以用这种方法找到第三大的数字了。
这种算法,由于受到锦标赛的启发,因此被称为是“锦标赛排序法”(也称为树形选择排序)。
总结一下这种方法,它分为两步:
- 把所有的数字放到二叉树的叶子结点,然后按照锦标赛单淘汰的方式,两两比较选出最大的。
- 对于第二大的,从所有被最大的数字淘汰的数字中选择。
比如在某次比赛中,被小德淘汰的分别是纳达尔、费德勒、穆雷等人,那么这些人再进行单淘汰,选亚军。对于第三、第四大的数字,可以以此类推。
如果用这种方式将所有的数字排序,算法的复杂度,或者说量级是 N 乘以 Log N,和快速排序差不多。
那么为什么不直接使用快速排序,而要发明出这样一种不太容易理解的算法呢?因为在特定的场合下,它更快速。比如说,如果我们只需要选出第一名,这种算法的复杂度只有 N,不是 N 乘以 Log N。如果还需要选出第二名,则额外增加Log N 次计算就可以了,对第三名也是如此。也就是说,这种方法在从N个选手中选出K个选手的事情中特别快。
示例
假定有二十五名短跑选手比赛竞争金银铜牌,赛场上有五条赛道,因此一次可以有五个人同时比赛。比赛并不计时,只看相应的名次。假如选手的发挥是稳定的,也就是说如果约翰比张三跑得快,张三比凯利跑得快,那么约翰一定比凯利跑得快。最少需要几组比赛才能决出前三名?
大家经过简单的思考,通常会认为需要 8 次才能决出前 3 名,分别是:
- 将25名选手分为五个组,每组五个人,为了便于说明,把这25人根据所在的组进行编号,A1-A5 在A组,B1-B5 在B组……最后 E1-E5 在最后的E组。然后让每个组分别比赛,排出各组的名次来。我们假设他们的名次就是他们在小组中的编号,即 A 组的名次是 A1、A2、A3、A4、A5…
- 让各组的第一名,也就是 A1、B1、C1、D1、E1 再比一次。这样就能决出第一名。由于 A1 是第一名,根据我们前面讲的淘汰赛的问题,A2 可能也很厉害,只是运气不好,小组赛遇到了 A1,当 A1 已经获得冠军了,他就应该作为亚军的候选。接下来,就进入第三步。
- A2 和另外四个组的第一名竞争亚军。如果这一次 A 2赢了,他显然是亚军,就由 A3 递进参加争夺第三名的比赛。如果A2没有赢,另四个组的某个第一名赢了,那个赢的人是亚军,就由那个组下一位选手递进,决逐第三名。
如果这样来规划,实际上还会有许多不必要的比较。前两轮比赛肯定是必须的,它要决出各组的名次和整体的第一名。
但是,在第六组比赛(即五个第一名的比赛)结束之后,最后的两名已经没有资格决逐前三名了。我们不妨假设那一次比赛从最快到最慢的结果是 A1、B1、C1、D1、E1。在D1和E1之前已经有三名选手了,他们肯定不是前三名。
那么谁还会是第二名的候选呢?根据锦标赛排序的原则,直接输给第一名的人,也就是 A 组中的 A2,以及最后附加赛输给他的 B1,仅此两人而已。除了 A2 和 B1,谁还会是第三名的候选呢?和 A1 在某一组比赛的第三名,他们是 A3、C1,或者输给第二名候选人 B1的人那个人,即B2。
因此,第二、三名的候选人一共只有五个,即 A2、A3、B1、B2 和 C1。刚好凑一组。让他们五个人再跑一次即可。这样加上前六次,只需要赛七组,这是最佳的方法。
-
二叉树/B-Tree/B+Tree
二叉查找树
不同于数组、链表、哈希表等其它数据存储结构的一种结构。对于其中的每个节点,左子节点的值都比它 小,而右子节点的值都比它大。
如下图:
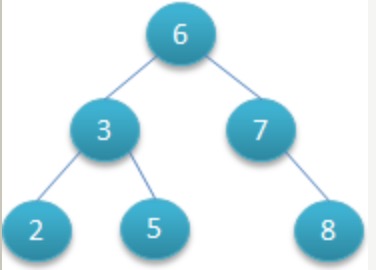
如果要查找 5,要先找到根节点 6。由于 6 比 5 小,所以要往左边的分支找。找到了 3,3 比 5 小,于是要再往右边的分支找。这样就找到了 5。
可以看到,在二叉树里查找一个值是很快的,和二分法差不多的效率。它的平均查找时间是 O(log n),在最坏的情况下是 O(n);在有序的数组中查找时,最坏的情况下也只要 O(log n),但二叉树的插入和删除要比数据快得多。时间表示如下:

当然,二叉树有个明显的缺陷就是不能进行随机访问,比如:第 5 个元素是什么?
二叉树的根节点可以是任意的一个值,比如同样是上面的 2 - 8 几个数字,也可以如下构造:
但如果我们要查找 8,它就得经过 2,3,5,7,最后找到 8。但在前面的结构中,只需要经过 6,7,8。所以这样的树结构性能就比较差。在应用中,我们如果要让树效率高,就要让树“平衡”。
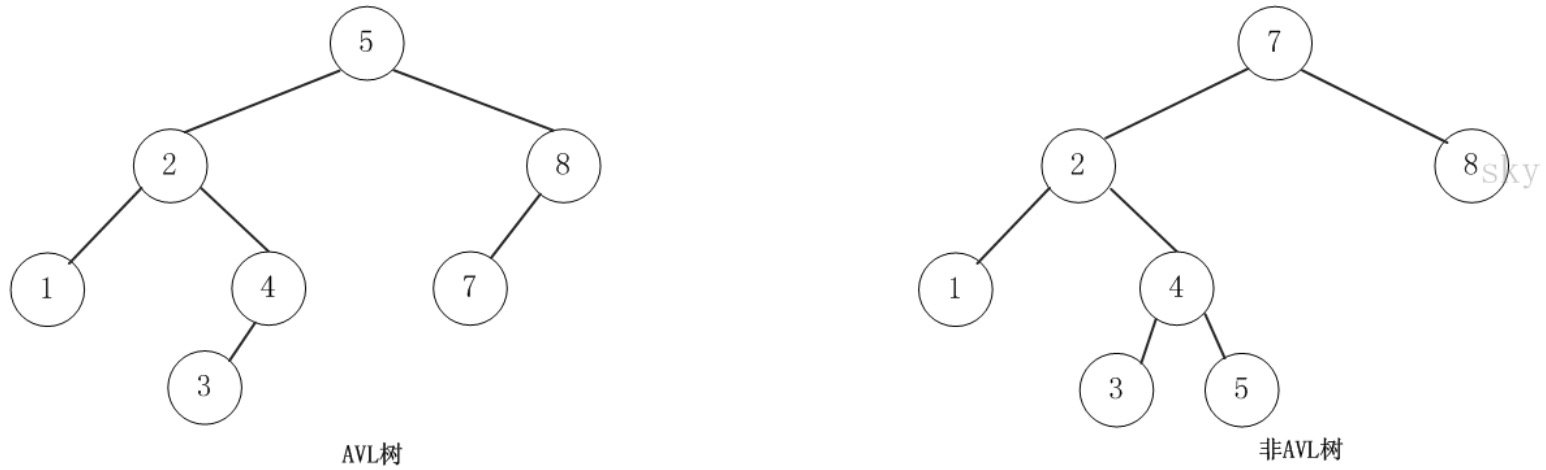
平衡二叉树(AVL Tree)
平衡二叉树(AVL树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。下面的两张图片,左边是AVL树,它的任何节点的两个子树的高度差<=1;右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1:
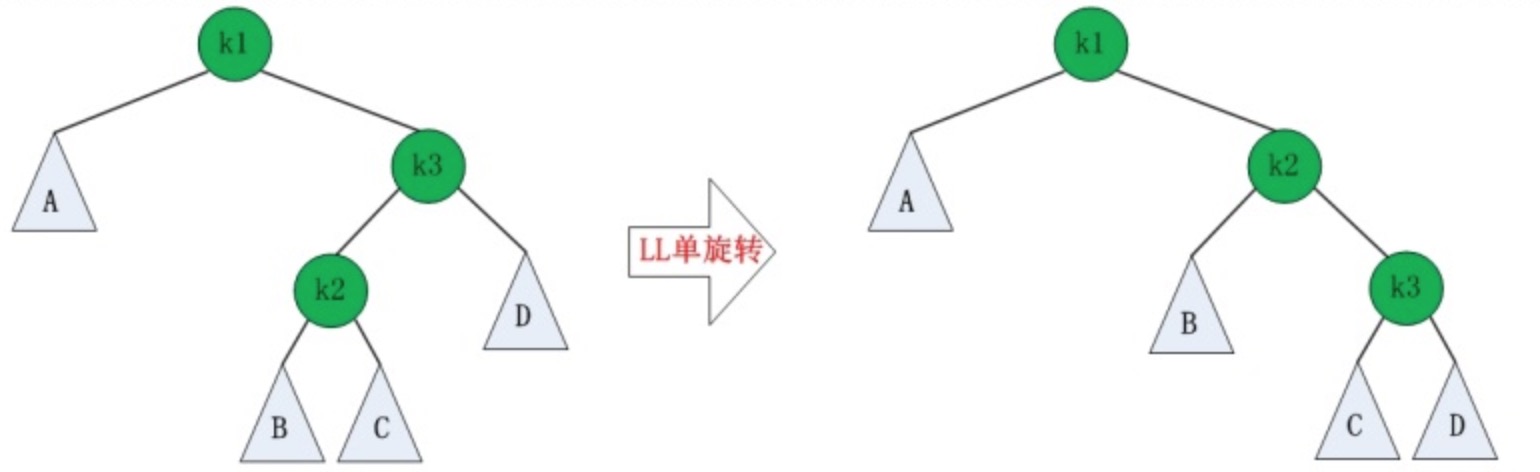
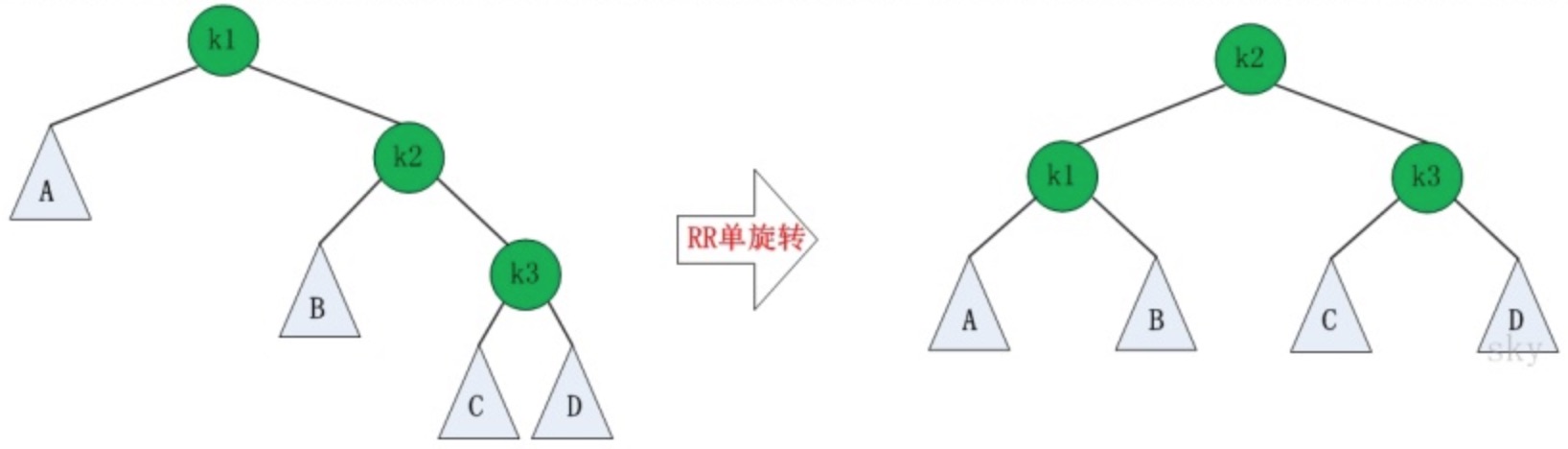
如果在AVL树中进行插入或删除节点,可能导致AVL树失去平衡,这种失去平衡的二叉树可以概括为四种姿态:LL(左左)、RR(右右)、LR(左右)、RL(右左)。它们的示意图如下:
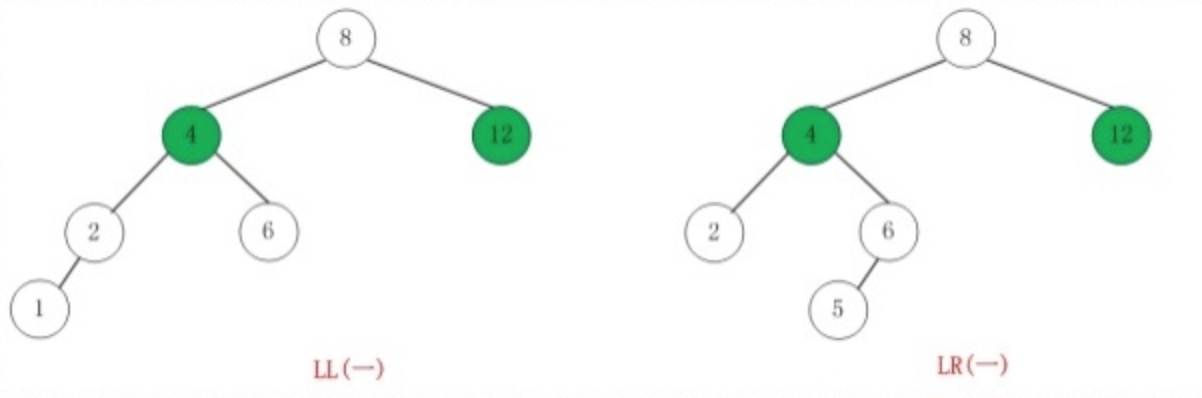
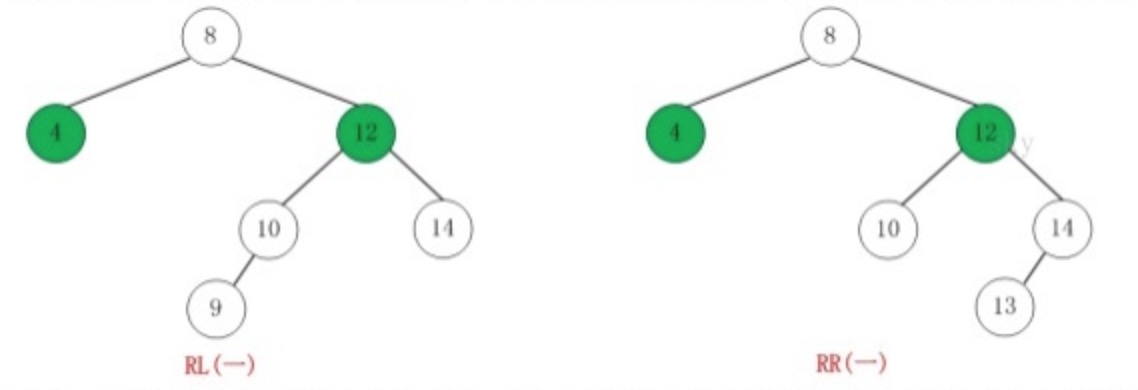
这四种失去平衡的姿态都有各自的定义:
-
LL:LeftLeft,也称“左左”。插入或删除一个节点后,根节点的左孩子(Left Child)的左孩子(Left Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
-
RR:RightRight,也称“右右”。插入或删除一个节点后,根节点的右孩子(Right Child)的右孩子(Right Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
-
LR:LeftRight,也称“左右”。插入或删除一个节点后,根节点的左孩子(Left Child)的右孩子(Right Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
-
RL:RightLeft,也称“右左”。插入或删除一个节点后,根节点的右孩子(Right Child)的左孩子(Left Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
AVL树失去平衡之后,可以通过旋转使其恢复平衡。下面分别介绍四种失去平衡的情况下对应的旋转方法。
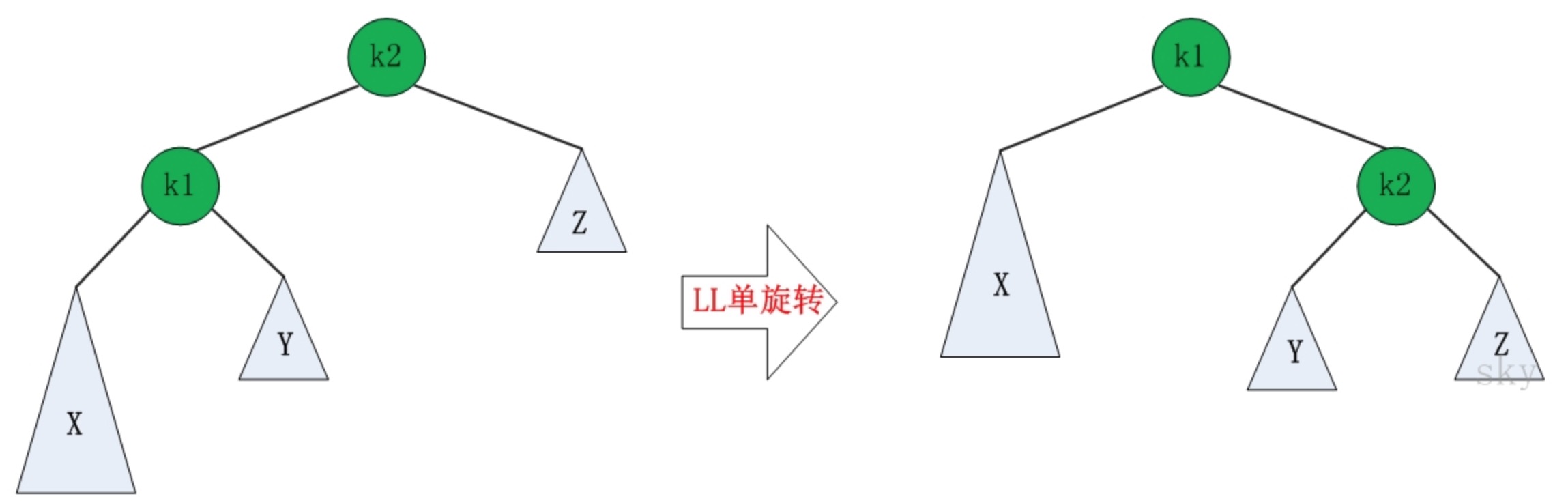
LL的旋转
LL失去平衡的情况下,可以通过一次旋转让AVL树恢复平衡。步骤如下:
- 将根节点的左孩子作为新根节点。
- 将新根节点的右孩子作为原根节点的左孩子。
- 将原根节点作为新根节点的右孩子。
图示如下:
RR的旋转
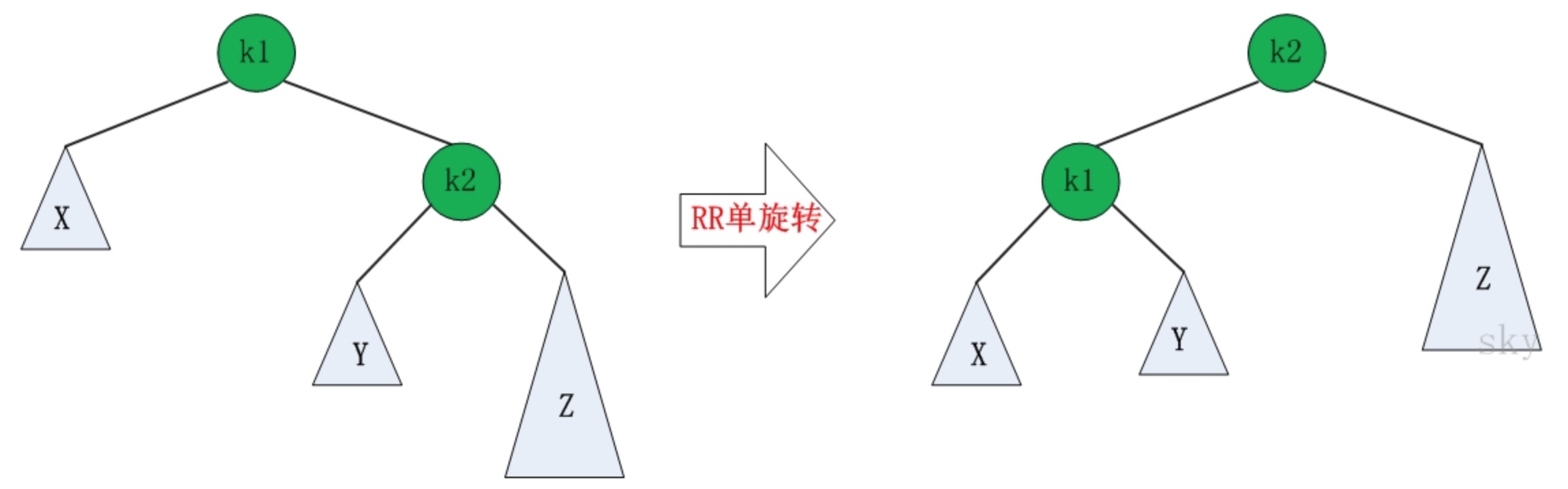
RR失去平衡的情况下,旋转方法与LL旋转对称,步骤如下:
- 将根节点的右孩子作为新根节点。
- 将新根节点的左孩子作为原根节点的右孩子。
- 将原根节点作为新根节点的左孩子。
图示如下:
LR的旋转
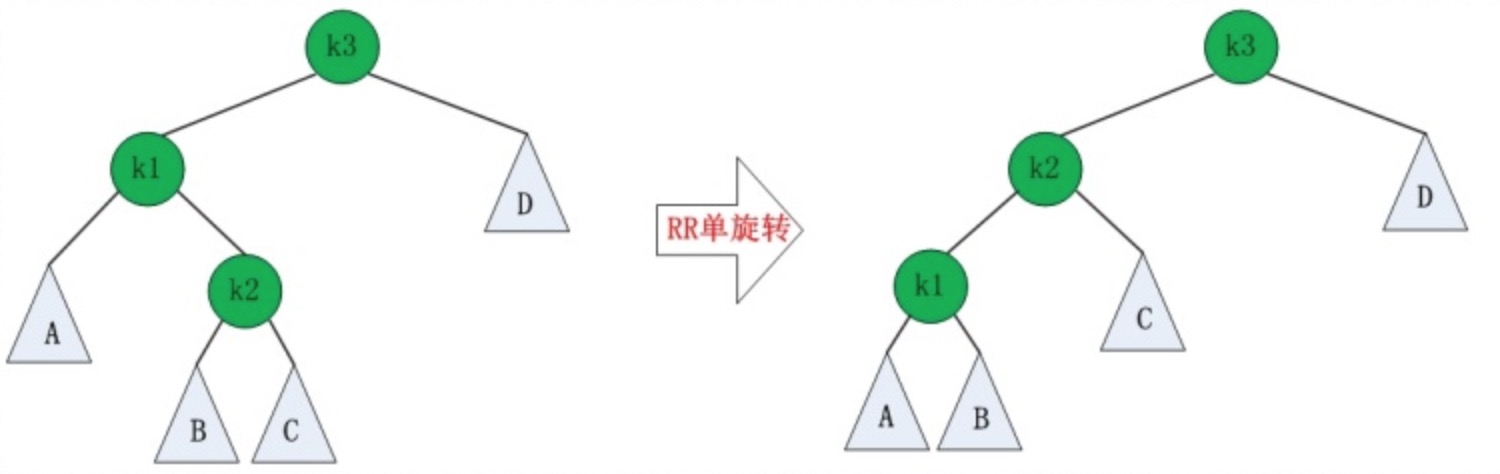
LR失去平衡的情况下,需要进行两次旋转,步骤如下:
- 围绕根节点的左孩子进行RR旋转。
- 围绕根节点进行LL旋转。
图示如下:
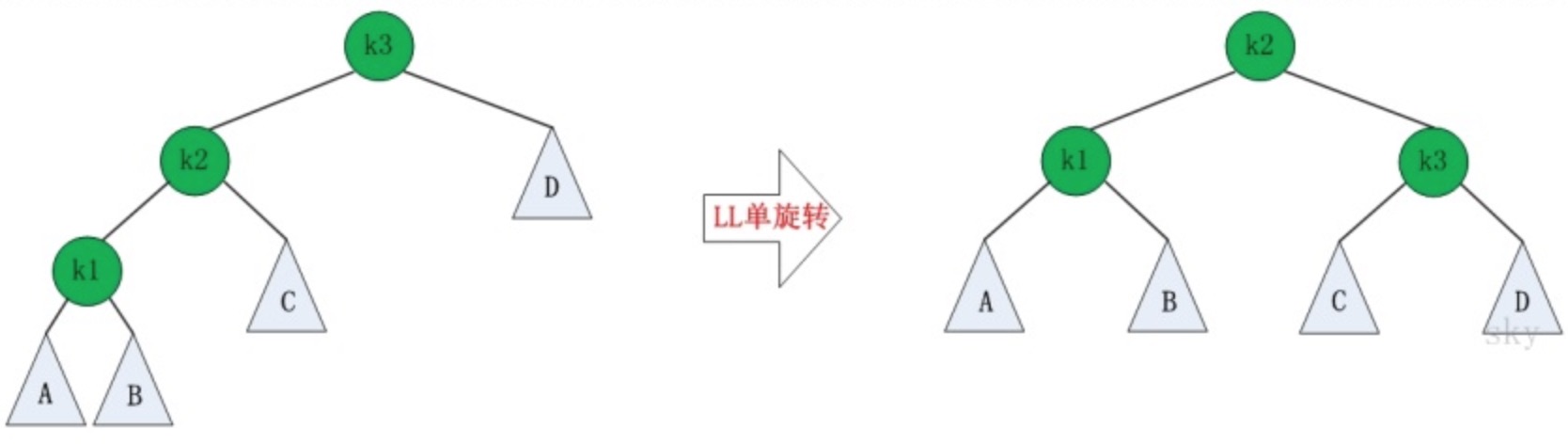
RL的旋转
RL失去平衡的情况下也需要进行两次旋转,旋转方法与LR旋转对称,步骤如下:
- 围绕根节点的右孩子进行LL旋转。
- 围绕根节点进行RR旋转。
图示如下:
平衡多路查找树(B-Tree)
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+ 1 row in set (0.01 sec)而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。
InnoDB在把磁盘数据读入到内存时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。
一个 m 阶的B-Tree有如下特性
- 每个节点最多有 m 个孩子。
- 除了根节点和叶子节点外,其它每个节点至少有 Ceil(m / 2)个孩子。
- 若根节点不是叶子节点,则至少有2个孩子
- 所有叶子节点都在同一层,且不包含其它关键字信息
- 每个非终端节点包含n个关键字信息(P0, P1, … Pn, k1, …kn)
- 关键字的个数 n 满足:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)为关键字,且关键字升序排序。
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
如图有一个三阶 B-Tree:
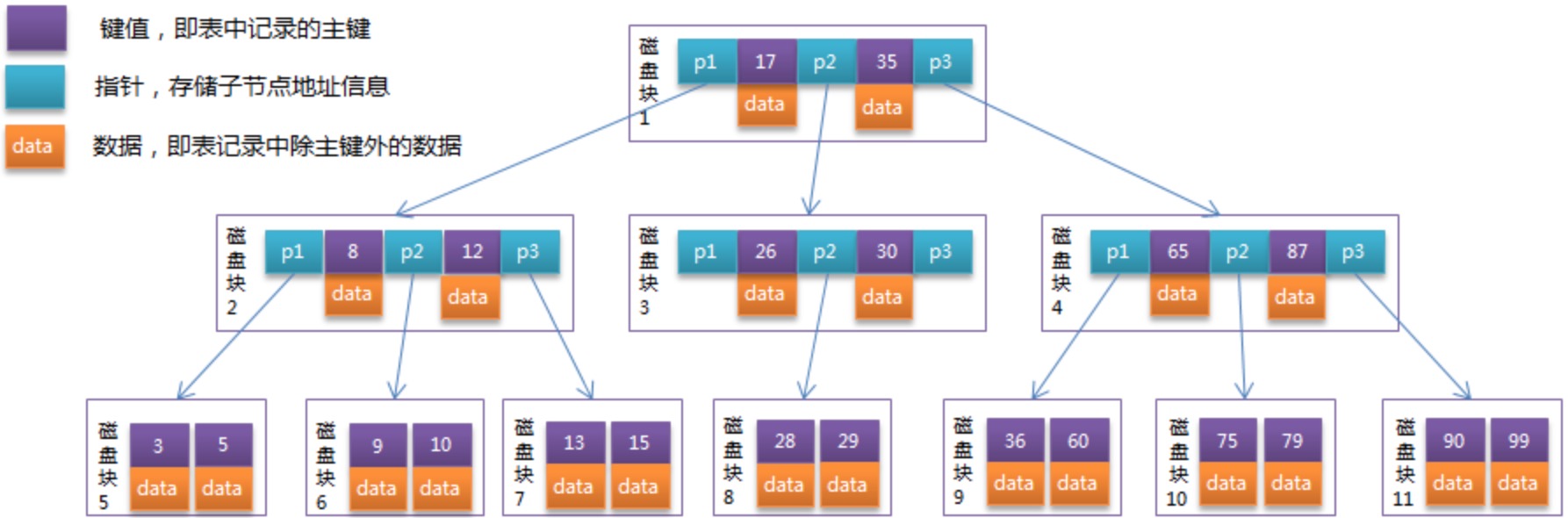
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字(ceil(3/2)-1<=n<=3-1)和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
- 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
- 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字29。
需要3次磁盘I/O操作,和3次内存查找操作就可以找到了。
B-Tree相对于AVLTree缩减了节点个数,它一个节点存入了更多的数据。使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB 存储引擎就是用B+Tree实现其索引结构。
B-Tree 的结构中,各个节点不仅包括了 key 的值,还包括了 data 的值。而每一页的空间是有限的,所以注定保存不了多少节点。这样就会导致树的深度会特别大,增大磁盘I/O的次数,影响查询效率。
在 B+Tree 中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
所以,B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
将前面的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
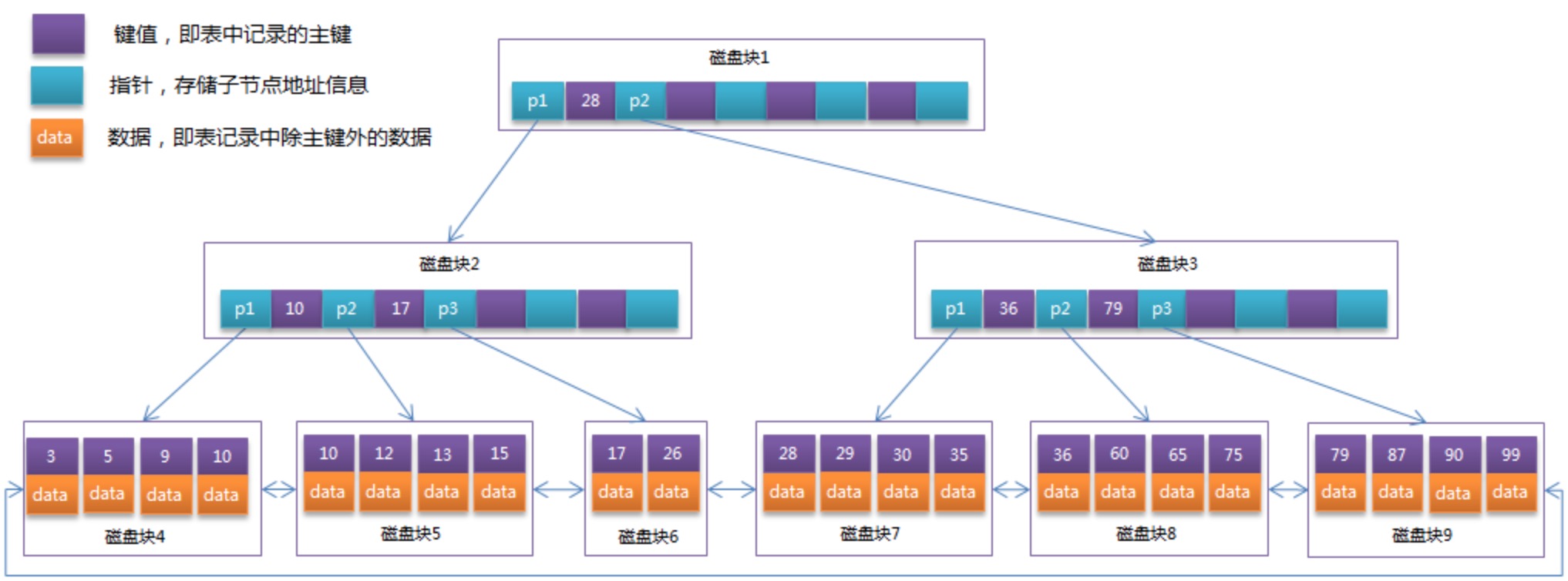
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用32位,4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为10^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。
辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
-
-
vagrant+vitrualbox打造开发环境
安装 vagrant 和 vbox
https://www.virtualbox.org/wiki/Downloads https://www.vagrantup.com/downloads.html下载虚拟机镜像
镜像是后缀名为 .box 文件,如下载一个 centos7.0比较纯净的版本,总大小只有 400多M:
https://github.com/tommy-muehle/puppet-vagrant-boxes/releases/download/1.1.0/centos-7.0-x86_64.box添加镜像
vagrant box add centos7 /data/soft/centos-7.0-x86_64.box查看当前镜像列表
vagrant box list关于 vagrant 的命令,可以使用
vagrant list-commonds查看它所有的命令box 相关的操作,可查看:
vagrant box list-commonds,
add: 添加 box 文件到镜像列表
list: 列出所有的镜像
outdated: 检查当前项目使用的box是否有更新
prune:
remove: 从镜像列表移除某个
repackage: 重打包box到当前目录,其中3个参数由vagrant box list获取
update: 从远程更新自定义配置
创建虚拟机目录 /Develop/centos7 及虚拟机描述文件 Vagrantfile 内容如下:
# -*- mode: ruby -*- # vi: set ft=ruby : # Vagrantfile API/syntax version. Don't touch unless you know what you're doing! VAGRANTFILE_API_VERSION = "2" Vagrant.configure(VAGRANTFILE_API_VERSION) do |config| config.vm.box = "centos7" config.vm.network "private_network", ip: "192.168.123.123" config.vm.provider "virtualbox" do |vb| vb.customize ["modifyvm", :id, "--memory", "2048"] end end设定好IP和该虚拟机要使用的 box 名称,还可以把本地电脑上的目录绑定到虚拟机上。这样可以实现在本地开发,虚拟机里文件同步的功能。方便调试。
还可以让虚拟机启动后执行一些脚本:
# -*- mode: ruby -*- # vi: set ft=ruby : # Vagrantfile API/syntax version. Don't touch unless you know what you're doing! VAGRANTFILE_API_VERSION = "2" Vagrant.configure(VAGRANTFILE_API_VERSION) do |config| config.vm.box = "edengdev-CentOS6.4x86_64" config.vm.network "private_network", ip: "192.168.192.192" config.vm.synced_folder "../../sites", "/home/httpd/sites", create:true, owner:"www", group:"www" config.vm.provision "shell", inline: "/etc/init.d/nginx.sh start", run: "always" config.vm.provision "shell", inline: "/etc/init.d/php-fpm start", run: "always" config.vm.provider "virtualbox" do |vb| vb.customize ["modifyvm", :id, "--memory", "2048"] end end这里在绑定目录时添加了 owner, group 参数,表明了它所属的用户和组。这样就不会受本机目录权限的影响导致程序运行时出错。
启动虚拟机
vagrant up // 启动 vagrant ssh // 登录导出虚拟机
我们可以通过
vagrant package命令把当前运行的镜像导出到一个box,发给别人使用(当然是指虚拟机里面环境安装好了之后)。用法如下:vagrant package -h Usage: vagrant package [options] [name|id] Options: --base NAME 虚拟机在 VirtualBox 中的名字,如: Html_default_1522149094762_41259 --output NAME 导出后,box的名称 --include FILE,FILE.. 和镜像一起导出的文件,比如项目配置文件,代码文件等 --vagrantfile FILE 和镜像一起导出的 Vagrantfile 文件,方便别人使用。因为里面可能已经设置了许多启动脚本,目录关联。示例:
vagrant package --base Html_default_1522149094762_41259 --output lnmp.box --vagrantfile Vagrantfile --include btjdxx_xinqigu_com.conf,demo_xinqigu_com.conf导出的时候它会先关闭虚拟机.如果不指定 –base ,它会找到当前目录所处的虚拟机。
导出完毕后,当前目录下就会多一个 box 了,可以把它添加到镜像列表,然后再创建一个虚拟机试试。
vagrant box add centos7_lnmp lnmp.box在另外一个目录:
vagrant init centos7_lnmp vagrant up启动后
vagrant shh进入虚拟机查看,发现 ip, 其它配置都和之前的一样,而且之前配置的vagrantfile里的设置也在该虚拟机上实现,添加的文件也在。导出成功!删除虚拟机
vagrant halt // 停止虚拟机 vagrant destroy // 删除虚拟机 vagrant box remove centos7_lnmp // 从镜像列表移除关联已经存在的虚拟机
本地使用 virtualbox 创建的虚拟机,然后使用 vagrant 来作为简易的管理。
同样的场景可能是:但有一天没关虚拟机就关电脑了,导致一些文件丢失,其中就有 vagrant 用来和虚拟机关联的,.vagrant/ 目录。
使用 vagrant init 命令可以创建一些配置。它会在当前目录下创建一个隐藏目录,叫 .vagrant,结构如:
.vagrant/machines/default/virtualbox/最终文件夹下的文件分别是:
action_provision action_set_name id synced_folders其中 id 文件中的内容就是和它关联的虚拟机的唯一ID,该文件夹丢失,导致使用 vagrant status 来查看虚拟机时,总是提示未创建。但是该虚拟机在 virtualbox 中确实是存在的,于是,用如下方法来手动关联:
先查看当前所有的 virtualbox 虚拟机:
VBoxManage list vms "nginx_web_conf_default_1417763838159_49997" {b969dad8-37d8-4237-8d3c-a01243bb91b3} "postdev-servers_default_1416493203261_51912" {00f2a72e-3431-430a-a1c6-25132ecdba63}每一行的前面双引号中是虚拟机的名称,后面花括号中的虚拟机的ID。
然后再将要关联的虚拟机的ID,写入上面说的对应 vagrant 目录下对应的 id 文件中,如:
echo -n "b969dad8-37d8-4237-8d3c-a01243bb91b3" > ~/Develop/edeng/.vagrant/machines/default/virtualbox/id然后再查看虚拟机状态:
vagrant status Current machine states: default poweroff (virtualbox)发现现在是关机状态,而不再是未创建,这时候就可以成功启动虚拟机了:
vagrant status