回归常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
回归的目的是用来预测数值型的目标值。最直接的办法是写一个公式依据输入数据得到结果。比如,想要预测姐姐男友汽车功率的大小,可能的公式是:
功率 = 0.0015 * 每月薪水 + 0.99 * 存款数额
这个计算公式就是回归方程,而公式中的 0.0015, 0.99 就是回归系数。这里的薪水,存款,叫做因数变量,而功率叫做自变量。
通过许多测试数据及结果反向推算出系数值的过程就叫回归。意思就是:目前已经有了许多完整的数据,包括了 N 个人的汽车功率大小以及他们的每月薪水及存款数额,但我们不知道回归系数分别取多少才是合适的,我们需要计算出来,找到一个对所有测试数据都合适的值。
当然,我们得到系数后,再把每个人的数据代入公式,计算理到的最终值与每个人的实际值之间肯定会有误差。
回归分析是被用来研究一个结果变量(自变量)与一个或多个原因变量(因变量)之间关系的统计技术。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。通过回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权重可以根据危险因素预测一个人患癌症的可能性。
我们要做的就是找出各个因变量的权重,即回归系数。
象这种,认为自变量的值是各个因变量乘以回归系数再相加的方式叫作 线性回归。也有不认为它们是相加的,认为它们是相乘或相除的。
线性回归
我们假设自变量 y 与因变量 x1,x2,⋯,xn之间具有线性相关的关系,那么用公式就可以将线性回归模型表示为:
y = f(xi)=w1x1+⋯+wnxn
可以看出就是一个矩阵相乘的算法。
简化为: y = wTx
w 就是回归系数。
如果只有一个因变量,将因变量的值做为横坐标,自变量做为纵坐标。 这就相当于,我们知道了一些数据点,要找一条合适的线,让他们最大程度的拟合。这就是线性回归。即:
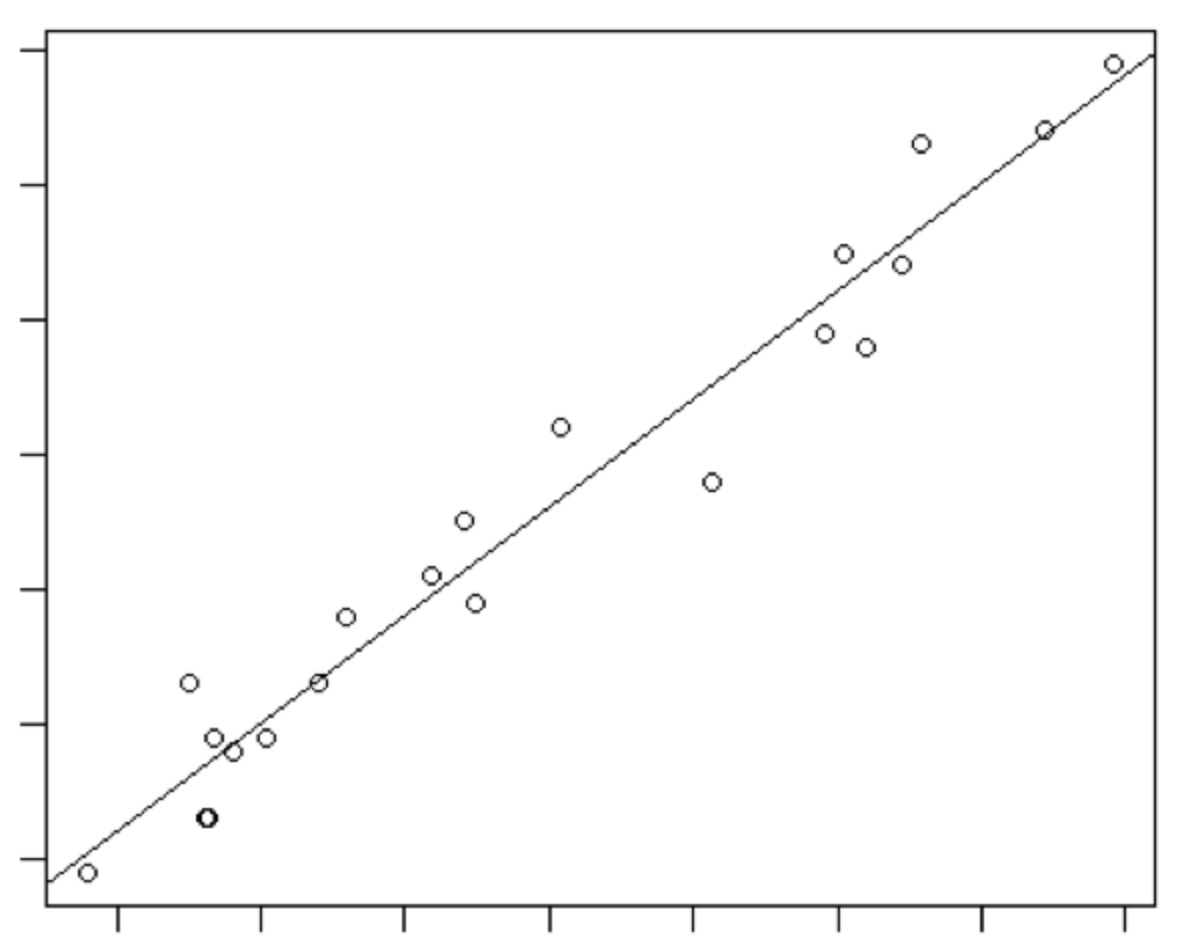
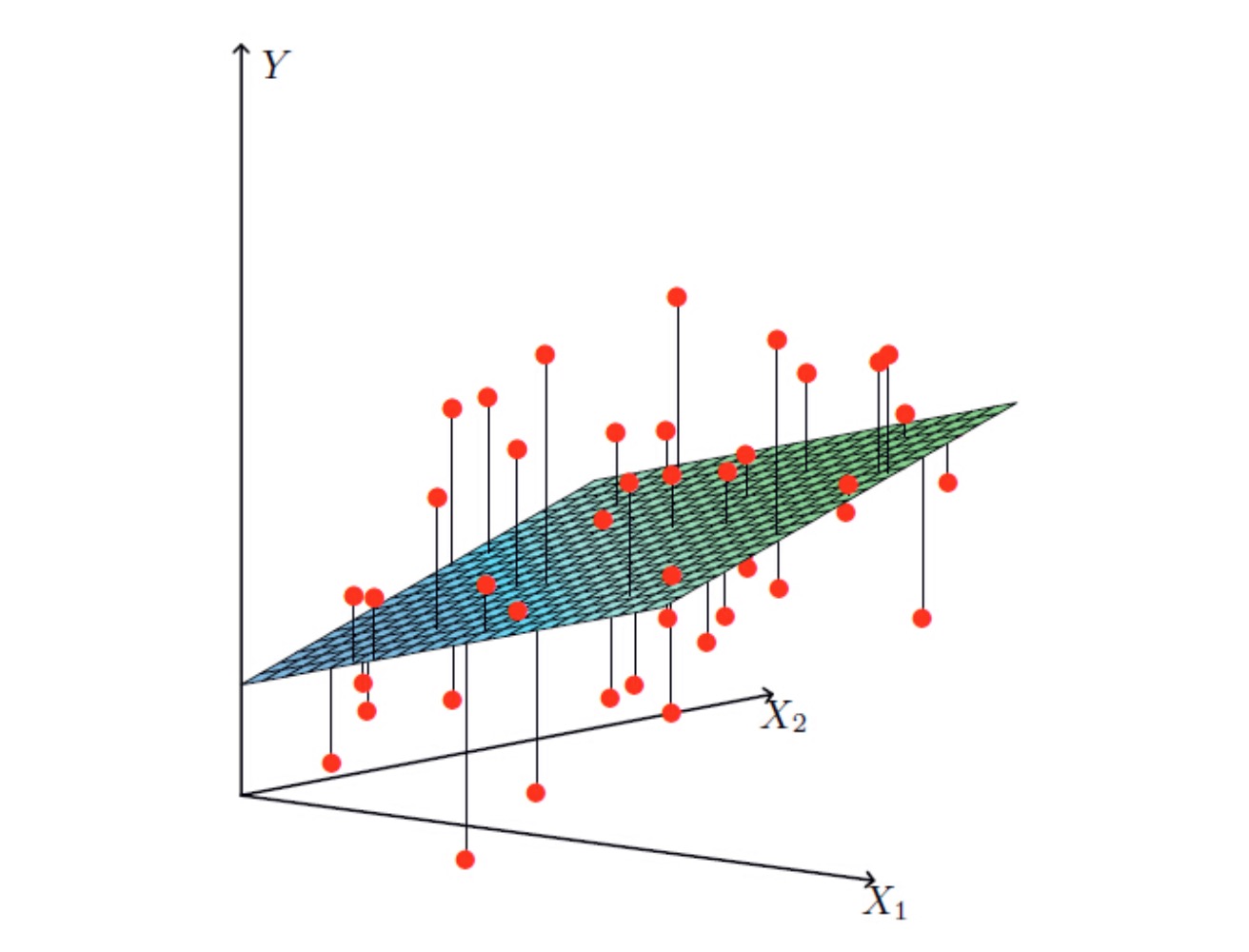
如果因变量有多个。用图表示:
已经有一堆数据 x 了,如何从中推导出回归系数 w 呢?一个常用的方法是找出使误差最小的 w。这里的误差指的就是公式计算出来的预测值 wTx 和真实值 y 之间的差值。我们要计算所有测试样本的误差(wTx - y),然后取一个最适中的值。由于误差可能为正,也可能为负,为了得到最合适的值,我们把所有的误差取平方然后相加。即:最小二乘法(最小平方法)。
所以,误差的平方差表示为: ∑(yi - wxiT)2
在矩阵的世界中,矩阵的平方可以表示为矩阵乘以矩阵的转置。
所以,差值用矩阵来表示,则是:(y-wX)T(y-wX) 对它求导数得到:XT(y-wX)。这就是误差值的表达式,在最理想的情况下,误差值是 0。
0 = XT(y-wX)
0 = XTy - wXTX
w = XT / XTX
而除法的意思是取逆,所以 w 的值:
w = XT(XTX)-1y
其中:XTX 表示 X 转置后再和 X 相乘,(XTX)-1 表示再将相乘的结果取逆。
案例:求回归系数
现有如下测试数据:
1.000000 0.067732 3.176513
1.000000 0.427810 3.816464
1.000000 0.995731 4.550095
1.000000 0.738336 4.256571
1.000000 0.981083 4.560815
1.000000 0.526171 3.929515
1.000000 0.378887 3.526170
1.000000 0.033859 3.156393
1.000000 0.132791 3.110301
测试的代码:
# 读取测试数据,返回因变量和自变量矩阵两个列表
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t')) - 1
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
# 标准的线性回归
def standRegres(xArr, yArr):
xMat = mat(xArr)
yMat = mat(yArr).T
xTx = xMat.T * xMat
if linalg.det(xTx) == 0.0:
print "该矩阵是奇异的,不能取逆"
return
ws = xTx.I * (xMat.T*yMat)
return ws
# 加载测试数据
xar, yar = loadDataSet("ex0.txt")
# 用线性回归计算回归系数
# 得到的结果是一个行向量
res = standRegres(xar, yar)
# 通过回归系数,为一个新数据推测结果值
# 声明一个测试数据数组,然后转换为矩阵,转换完后,它是一个列向量
test_data = mat([1, 0.378887])
# 由于 test_data 是一个列向量,res 是行向量,所以两者就没必要进行转置了。可以直接相乘
# 就算拿我们测试数据中现有的值来计算,它的结果和原来的结果也会有差别
test_res = test_data * res
Logistic 回归
Logistic regression可以用来回归,也可以用来分类。比如,目前我们要判断某用户是否患有癌症,那么自变量只能有两个:0,1 分别表示是否患癌,因变量有很多。我们就需要一个函数,任意输入我们的因变量,输出 0 或 1 的结果。
这种情况下,线性回归是没法解决的;因为线性回归只能找出一堆数据中最拟合的回归系数,从而通过公式对新的值进行预测。
而我们现在需要的是通过算法,找到不同分类数据的边界,得到边界处各个系数,然后通过公式对新的值进行计算,把结果和边界处的值进行比较,大于的则判定它属于分类1,小于边界处值的则判定它属于分类2。
从这个逻辑上来看,这属于一个二项分布。而二项分布的分布律是:P(y) = py * (1-p)1-y
对于边界线,我们可以知道它的函数是:F(x) = wTx = 0 并且,这条边界线上的点,属于两边的概率是一样的,即:P(Y = 1 | x) / P(Y = 0 | x) = 1且有: P(Y = 1 | x) + P(Y = 0 | x) = 1
我们将该等式 P(Y = 1 | x) / P(Y = 0 | x) = 1 变换一下,就变成了:ln(P(Y = 1 | x) / P(Y = 0 | x)) = 0
由于 wTx = 0, 将等式右侧的 0 进行替换:
==>ln(P(Y = 1|x) / P(Y = 0|x)) = wTx
由于 P(Y = 1 | x) + P(Y = 0 | x) = 1, 可以得知 P(Y = 1 | x) = 1 - P(Y = 0 | x)将等式左侧进行替换:
==>ln(P(Y = 1 | x) / (1- P(Y = 1 | x))) = wTx
==>ewTx = P(Y = 1 | x) / (1- P(Y = 1 | x))
P(Y = 1 | x) 的意思是某点的结果是 1 的概率,我们简化为 P
==>ewTx = P / (1 - P)
==> P = (1 - P)ewTx
==> P = ewTx - P * ewTx
==> P(1 + ewTx) = ewTx
==> P = ewTx / (1 + ewTx)
==> P = 1 / (1 + e-wTx)
注意,上面的推导是专门针对边界线上的点进行的。我们观察上面的等式。分母中 wTx</sup> 就是直线的表达式。那么,我们就可以知道,无论边界是不是直线,只要它能用函数表达式出,就能使用上面的等式。
即,上面的等式可以简化为:
P = 1 / (1 + e-z)
其中,z 就是边界线的函数表达式。
上面的函数就是 Logistic 回归的描述函数了
该函数的曲线是:
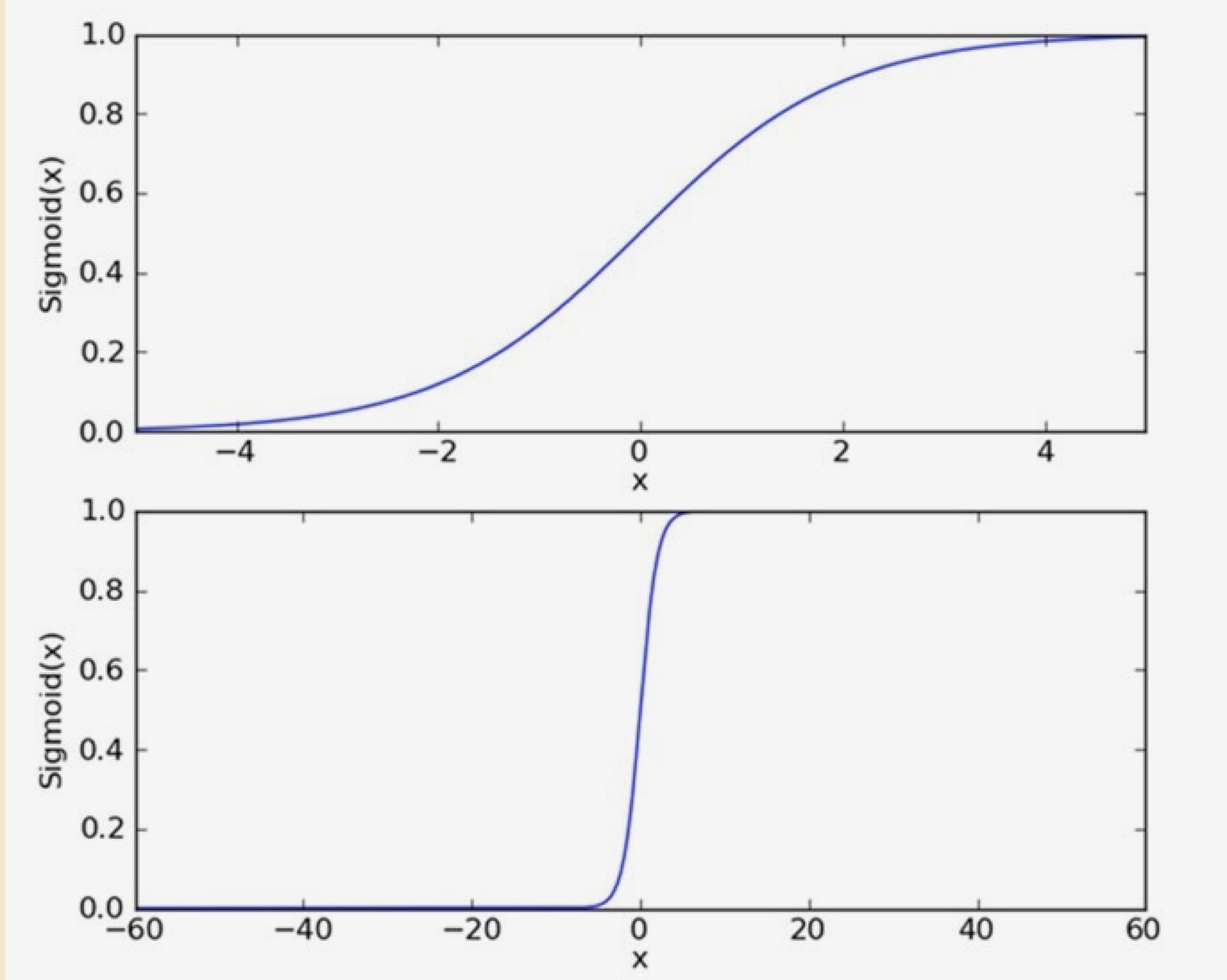
它将无穷的值映射到了(0,1), 描述的是属于类别 1 的概率。对于 z = 0 的点,就是前面提到的分界线上的点,函数值是 0.5,表示它属于类别 1 的概率是 0.5,于是它属于类别 2 的概率也是 0.5。
那么,剩下的任务就是如何找到边界,确定边界的函数了。对于直线分隔的两个分类,函数就是 wTx,而该函数里要确定的就是各个参数的值:w。
梯度上升算法求边界
前面已经知道该公式:
y = w0+w1x1+⋯+wnxn
我们将它简化成: y = wTx。x 是各个因变量的值,w 就是我们要得到的各个因变量的权重。也称最佳系数。我们需要找到最合适的系数,让这个公式表示的直线正好把不同分类的数据分隔开。即:这条线是不同数据的边界。
这里我们使用梯度上升算法来判断边界在何处。思路是:要找到某函数的最大值,最好的方法就是沿着该函数的梯度方向探寻。
案例:
给定一个样本集,每个样本点有两个维度值(X1,X2)和一个结果值,结果只有两种,我们以 0 和 1 代表。数据如下所示:
| 样本 | x1 | x2 | 结果 |
| 1 | -1.4 | 4.7 | 1 |
| 2 | -2.5 | 6.9 | 0 |
机器学习的任务是找一个函数,给定一个数据两个维度的值,该函数能够预测其结果为 1 的概率。 这个函数的模样如下:
h(x) = sigmoid(z)
z = w0 + w1 * X1 + w2 * X2
现在,问题转化成了: 根据现有的样本数据,找出最佳的参数 w(w0,w1,w2)的值。
假设现在手上已经有一个函数h(x),那么我们可以把样本1和样本2的数据代进去,看看这个函数的预测效果如何,假设样本1的预测值是p1 = 0.8,样本2的预测值是:p2 = 0.4。
函数在样本1上犯的错误为e1=(1-0.8)= 0.2,在样本2上犯的错误为e2=(0-0.4)= -0.4,总的错误 E 为 -0.20(e1+e2)。如下表所示:
| 样本 | x1 | x2 | 结果 | 预测值 | 误差 |
| 1 | -1.4 | 4.7 | 1 | 0.8 | 0.2 |
| 2 | -2.5 | 6.9 | 0 | 0.4 | -0.4 |
知道了算法的误差,我们就需要改进算法,让误差尽量小。通常,评判误差值的方法有很多种,叫作损失函数,如:平方损失函数,对数损失函数。
平方损失函数是用最小二乘法,它的原理是中心极限定律,将每个测试数据预测值和实际值的差值求平方然后再累加。即: L(yi, f(xi)) = ∑(yi - f(xi))2 在线性回归算法中,我们就是用平方损失函数来判断直线是否最拟合的。且,损失函数中的 f(x) = wTx
对数损失函数的原理是极大似然估计。
对于样本 1 来说: 我们的预测值比理论值小,所以我们要提高函数输出的值。即提高 w1 * X1 的值。由于 X1 是负数,所以我们要达到目标,必须减少 w1 的值。
对于样本 2 来说: 我们的预测值比理论值大,所以我们要减少函数输出。即减小 w1 * X1 的值。由于 X1 是负数,为了达到目标,必须增大 w1 的值。
同样的算法,对样本1来说,调高系数会让算法更准确;对样本2,调低系数会更准确。这时候,我们就要进行取舍,看怎么调整会让最终的结果更准确。比如:调高后,样本1 的错误大大减少,样本2 的错误稍微增加,那么就可以调高。具体要增加多少,可以用一个变量 alpha 来表示,通过一次次的非常微小的调整来进行尝试。当最终的准确度达到最高后,终止尝试。这种做法就叫:梯度上升法,我们找到函数的最大值。我们也可以通过调低的方式来进行调整,这样我就找的就是最小值,那就叫:梯度下降法
画决策边界
现有如下数据集:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
有 100 个样本数据坐标点。第一列表示横坐标,第二列是纵坐标,第三列表示点的类型。这里用颜色区分,1 表示是红色,0 表示蓝色。这些点在坐标系中如下图:
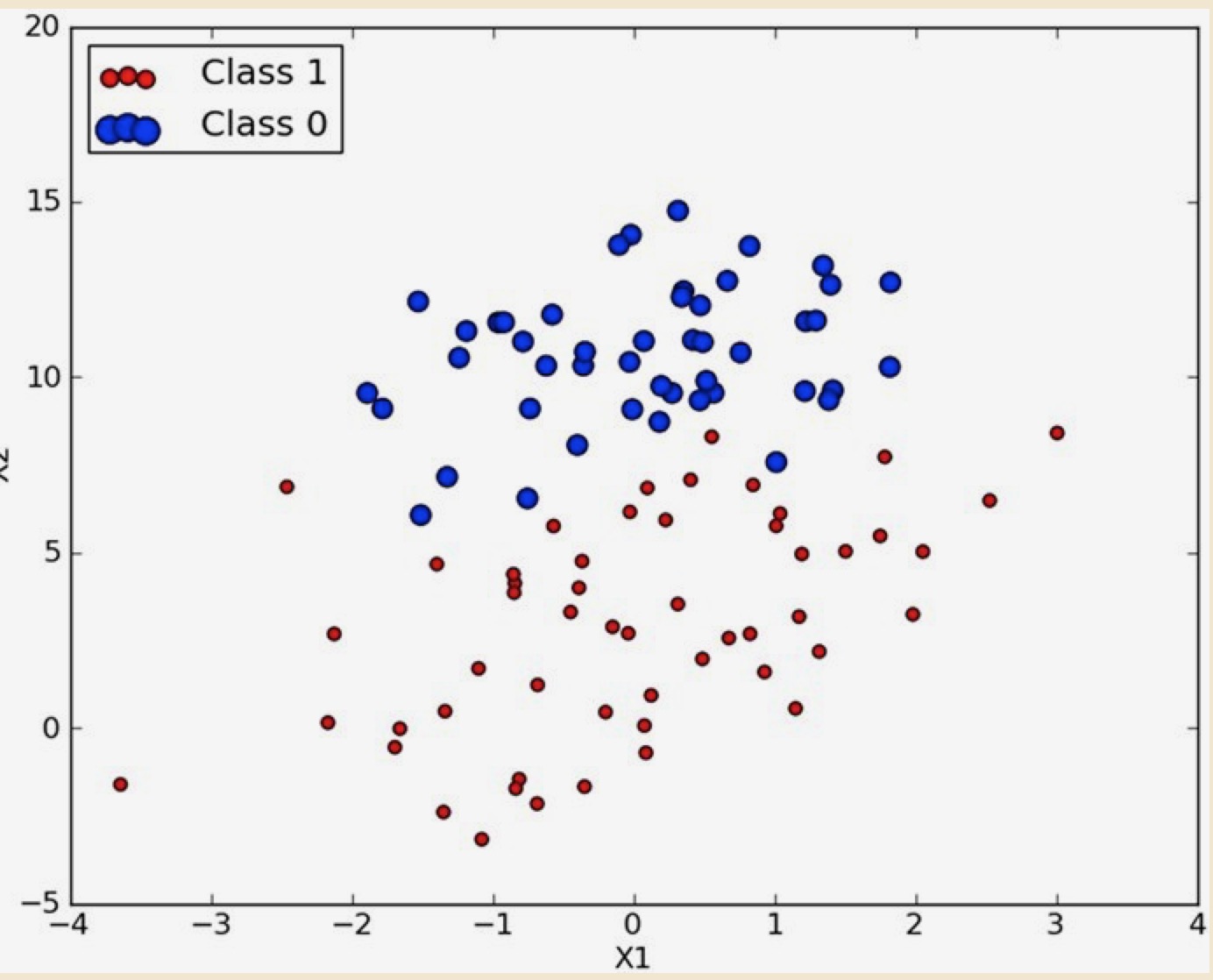
现在想要:给出一个点的坐标,预测他是红还是蓝。将问题转换一下,就是:找出红蓝的边界线。然后找出该点的横坐标处的边界的纵坐标。如果点的纵坐标大于边界纵坐标,点就是蓝色,反之是红色。
代码如下:
# -*- coding: utf-8 -*-
from numpy import *
# 加载测试数据.将 csv 格式的数据读取到多维数组中.
# 数组的每一个值又是一个数组。数组的第一个值是1.0,因为后面的矩阵运算会用乘法,而公式中规定: p = w0 + w1 * x1 + w2 * x2 ... wn * xn
# w0 是固定的值,不能在运算时变化,所以这里给矩阵引入一个 x0, 且值为 1
# 公式就变为: p = w0 * x0 + w1 * x1 + w2 * x2 ... wn * xn, 且x0 = 1
# 后面两个值是测试数据的头两行,即横坐标和纵坐标
# 数据中的结果单独在一个数组中
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
# sigmoid 算法.将值归到 0 - 1 之间.它是随输入值变大页递增的
# 当 x = 0 时,Sigmoid 的值是 0.5;x 越大,值越逼近 1。x 越小,值越逼近 0。
def sigmoid(inX):
return 1.0/(1+exp(-inX))
# 算出回归系数
# 回归算法: y = w0+w1x1+⋯+wnxn ; w0 是固定值
def gradAscent(dataMatIn, classLabels):
# 数组转换为矩阵.大小是 100 * 3
dataMatrix = mat(dataMatIn)
# 数组转矩阵.大小是 100 * 1
labelMat = mat(classLabels).transpose()
# 测试数据矩阵的形状.测试数据是 100 条,加载数据时每一行的长度又是 3
# 所以这里 m = 100; n = 3
m, n = shape(dataMatrix)
# 在递增测试时,给出一个一次加多少的系数
alpha = 0.001
# 循环多少次,以找到函数的最优系数
maxCycles = 500
# 初始值.是一个 3 x 1 的矩阵.就是 w0, w1, w2
# w0 表示算法中固定的值.w1 表示数据坐标点横坐标的系数; w2 表示数据坐标点纵坐标的系数;
# 后面会在算法中对该矩阵进行 N 次的微调
weights = ones((n, 1))
# 循环找边界
for k in range(maxCycles):
# 计算当前的函数输出值
h = sigmoid(dataMatrix * weights)
# 计算当前算法的误差值。
# 从数学角度来说,边界线的函数是 f(x, w) = w1x1 + w2x2 + ... + wnxn = wTx, w 就是参数矩阵,就是这里的 weights
# 如果差值大于 0,表示建模的函数值比较实际的要小,需要把参数调大;如果有效期值小于 0,则要把参数调小。
error = (labelMat - h)
# 根据误差调整参数.如果差值大于 0,这里的运算会把参数调高;
weights = weights + alpha * dataMatrix.transpose() * error return weights
# 画边界
def plotBestFit(weights):
import matplotlib.pyplot as plt
# 加载数据
dataMat,labelMat = loadDataSet()
dataArr = array(dataMat)
# 数据条数
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
# 遍历数据.将各个数据按最后一列的值分类存放
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
# 添加各个坐标点.并按类别显示不同的颜色
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
# 分界线的位置.我们判断时的标准是:函数得到的值小于 0.5, 则认为它是结果 0;大于 0.5 认为是结果 1.所以,边界处的函数值是 0.5.
# 由于边界值是经过 sigmoid 计算过的.而 0.5 对应 sigmoid 之前的值是 0,即此处 w0 + w1x1 + w2x2 的值是 0
# 由此,先定义一个概念:边界处的函数输出值是 0
# 0 = w0 + w1x1 + w2x2 就是边界线的方程.w0, w1, w2 已经在 weights 数组中
# x1 是横坐标, x2 是纵坐标.所以 x2 = (-w0 - w1x1) / w2
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
# 加载测试数据
data, label = loadDataSet()
res = gradAscent(data, label)
plotBestFit(res.getA())
运行后生成图:
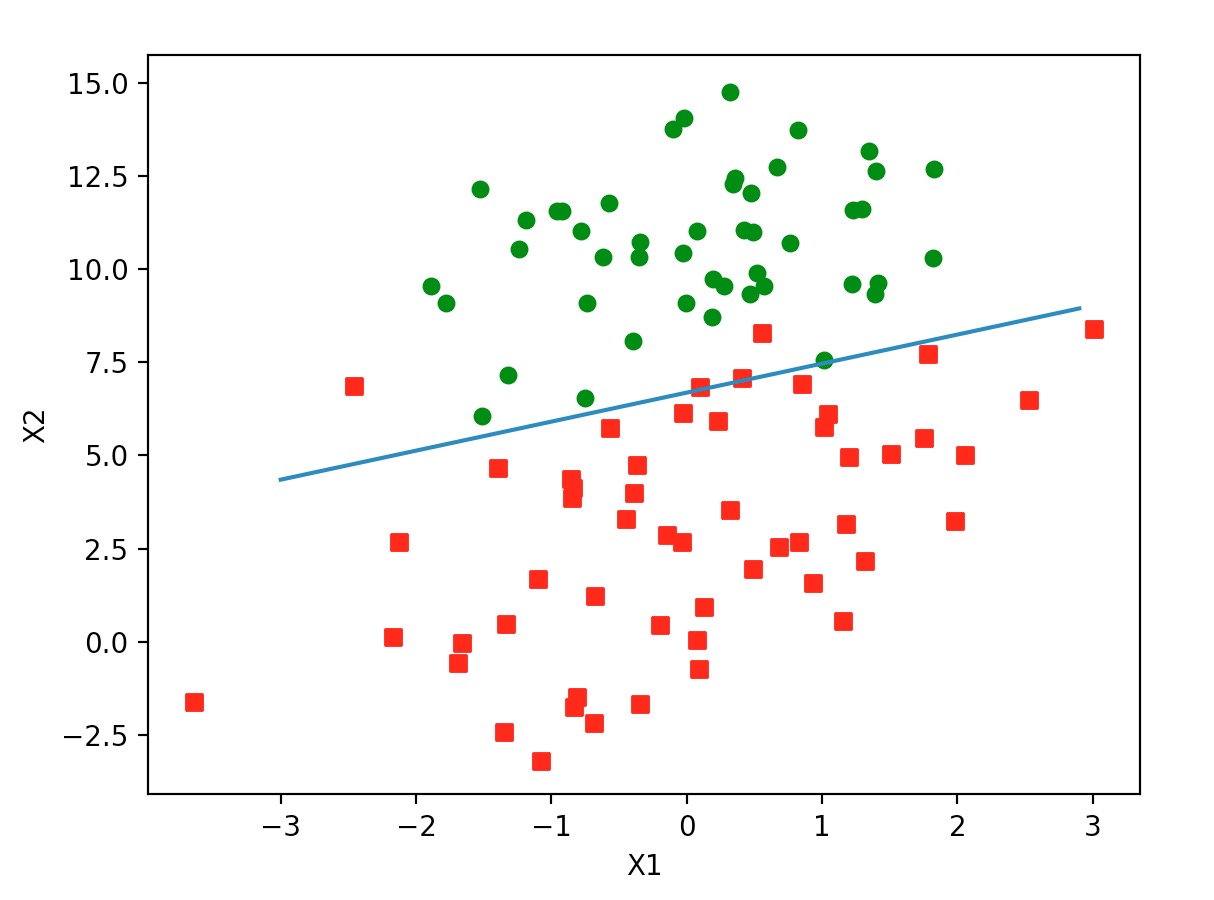
从图中可以看到只有少数几个点是被错误划分了。说明准确率还是不错的。但通过代码我们可以看到。在 500 次的循环中,每次都要对整个数据矩阵进行运算。矩阵是 100 * 3 的,即每个循环都要进行 300 次乘法运算。如果数据量非常大,这就很慢了,而且消耗资源巨大。一种改进办法是:一次只对一个样本数据进行运算。代码如下:
# -*- coding: utf-8 -*-
from numpy import *
# 加载测试数据.将 csv 格式的数据读取到多维数组中.
# 数组的每一个值又是一个数组。数组的第一个值是1.0,因为后面的矩阵运算会用乘法,而公式中规定: p = w0 + w1 * x1 + w2 * x2 ... wn * xn
# w0 是固定的值,不能在运算时变化,所以这里给矩阵引入一个 x0, 且值为 1
# 公式就变为: p = w0 * x0 + w1 * x1 + w2 * x2 ... wn * xn, 且x0 = 1
# 后面两个值是测试数据的头两行,即横坐标和纵坐标
# 数据中的结果单独在一个数组中
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
# sigmoid 算法.将值归到 0 - 1 之间.它是随输入值变大页递增的
# 当 x = 0 时,Sigmoid 的值是 0.5;x 越大,值越逼近 1。x 越小,值越逼近 0。
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
# 动态调整系数.会随着运行减少,但永远不会减少到 0。这样就保证了该值对最后的结果是有影响的,而且它的正负性质不会改变
# 也可以自己定义一个算法
alpha = 4/(1.0+j+i)+0.0001
# 每次随机取一个样本来计算
randindex = int(random.uniform(0, len(dataIndex)))
h = sigmoid(sum(dataMatrix[randindex] * weights))
error = classLabels[randindex] - h
# 根据不同参数来调整系数.这里 alpha, error 成为了数值, 不是向量;这就又减少了运算量
# 对参数的处理方式和之前一样。如果差值大于 0,表示建模的函数值比较实际的要小,需要把参数调大;如果有效期值小于 0,则要把参数调小。
weights = weights + alpha * error * dataMatrix[randindex]
# 为保证调整后下次不再取到它,把它从列表中删除
del(dataIndex[randindex])
return weights
# 画边界
def plotBestFit(weights):
import matplotlib.pyplot as plt
# 加载数据
dataMat,labelMat = loadDataSet()
dataArr = array(dataMat)
# 数据条数
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
# 遍历数据.将各个数据按最后一列的值分类存放
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
# 添加各个坐标点.并按类别显示不同的颜色
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
# 分界线的位置.我们判断时的标准是:函数得到的值小于 0.5, 则认为它是结果 0;大于 0.5 认为是结果 1.所以,边界处的函数值是 0.5.
# 由于边界值是经过 sigmoid 计算过的.而 0.5 对应 sigmoid 之前的值是 0,即此处 w0 + w1x1 + w2x2 的值是 0
# 由此,先定义一个概念:边界处的函数输出值是 0
# 0 = w0 + w1x1 + w2x2 就是边界线的方程.w0, w1, w2 已经在 weights 数组中
# x1 是横坐标, x2 是纵坐标.所以 x2 = (-w0 - w1x1) / w2
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
# 加载测试数据
data, label = loadDataSet()
res = stocGradAscent(array(data), label)
plotBestFit(res)
案例:疝气病症预测病马的死亡率
目前我们已经有了梯度上升的算法 stocGradAscent(dataMatrix, classLabels, numIter=150) ,它可以接受一个数据集合,结果集合,和遍历次数。就可以求出最佳系数的集合。那么,我们就可以用它来进行预测,逻辑是:
- 拿到一些数据进行训练,得到最佳系数。
- 拿到需要测试的数据,把系数和数据带入公式中,计算回归值。
- 把回归值进行 Sigmoid 运算,得到的值和 0.5 进行比较,以判断结果。
训练数据:
2.000000 1.000000 38.500000 66.000000 28.000000 3.000000 3.000000 0.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 3.000000 5.000000 45.000000 8.400000 0.000000 0.000000 0.000000
1.000000 1.000000 39.200000 88.000000 20.000000 0.000000 0.000000 4.000000 1.000000 3.000000 4.000000 2.000000 0.000000 0.000000 0.000000 4.000000 2.000000 50.000000 85.000000 2.000000 2.000000 0.000000
2.000000 1.000000 38.300000 40.000000 24.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 33.000000 6.700000 0.000000 0.000000 1.000000
1.000000 9.000000 39.100000 164.000000 84.000000 4.000000 1.000000 6.000000 2.000000 2.000000 4.000000 4.000000 1.000000 2.000000 5.000000 3.000000 0.000000 48.000000 7.200000 3.000000 5.300000 0.000000
2.000000 1.000000 37.300000 104.000000 35.000000 0.000000 0.000000 6.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 74.000000 7.400000 0.000000 0.000000 0.000000
2.000000 1.000000 0.000000 0.000000 0.000000 2.000000 1.000000 3.000000 1.000000 2.000000 3.000000 2.000000 2.000000 1.000000 0.000000 3.000000 3.000000 0.000000 0.000000 0.000000 0.000000 1.000000
1.000000 1.000000 37.900000 48.000000 16.000000 1.000000 1.000000 1.000000 1.000000 3.000000 3.000000 3.000000 1.000000 1.000000 0.000000 3.000000 5.000000 37.000000 7.000000 0.000000 0.000000 1.000000
1.000000 1.000000 0.000000 60.000000 0.000000 3.000000 0.000000 0.000000 1.000000 0.000000 4.000000 2.000000 2.000000 1.000000 0.000000 3.000000 4.000000 44.000000 8.300000 0.000000 0.000000 0.000000
2.000000 1.000000 0.000000 80.000000 36.000000 3.000000 4.000000 3.000000 1.000000 4.000000 4.000000 4.000000 2.000000 1.000000 0.000000 3.000000 5.000000 38.000000 6.200000 0.000000 0.000000 0.000000
2.000000 9.000000 38.300000 90.000000 0.000000 1.000000 0.000000 1.000000 1.000000 5.000000 3.000000 1.000000 2.000000 1.000000 0.000000 3.000000 0.000000 40.000000 6.200000 1.000000 2.200000 1.000000
测试数据:
2 1 38.50 54 20 0 1 2 2 3 4 1 2 2 5.90 0 2 42.00 6.30 0 0 1
2 1 37.60 48 36 0 0 1 1 0 3 0 0 0 0 0 0 44.00 6.30 1 5.00 1
1 1 37.7 44 28 0 4 3 2 5 4 4 1 1 0 3 5 45 70 3 2 1
1 1 37 56 24 3 1 4 2 4 4 3 1 1 0 0 0 35 61 3 2 0
2 1 38.00 42 12 3 0 3 1 1 0 1 0 0 0 0 2 37.00 5.80 0 0 1
1 1 0 60 40 3 0 1 1 0 4 0 3 2 0 0 5 42 72 0 0 1
2 1 38.40 80 60 3 2 2 1 3 2 1 2 2 0 1 1 54.00 6.90 0 0 1
2 1 37.80 48 12 2 1 2 1 3 0 1 2 0 0 2 0 48.00 7.30 1 0 1
代码如下:
def classifyVector(inX, weights):
# 计算回归值,然后再计算 sigmoid 的值
prob = sigmoid(sum(inX*weights))
# 根据 sigmoid 的值进行预测
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
# 训练用的数据
frTrain = open('horseColicTraining.txt')
# 待测试的数据
frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
# 遍历训练数据.对于某些缺少数值的列,我们可以用 0 来填充.
# 用 0 填充后,后面梯度上升算法计算系数时 weights = weights + alpha * error * dataMatrix[randindex], 权重会不变,这样对结果就不会产生影响
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
# 数据最后一列是结果
trainingLabels.append(float(currLine[21]))
# 计算最优系数.进行 1000 次计算
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
# 开始测试系数准确度
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print "预测错误率是: %f" % errorRate
return errorRate
colicTest()