SVM 是目前最好的现成算法之一。它的好处是不用你做什么修改就可以直接使用。甚至不用理解它的原理。它和回归算法一样,也是用来进行数据的分类,求最优方式。
简单理解
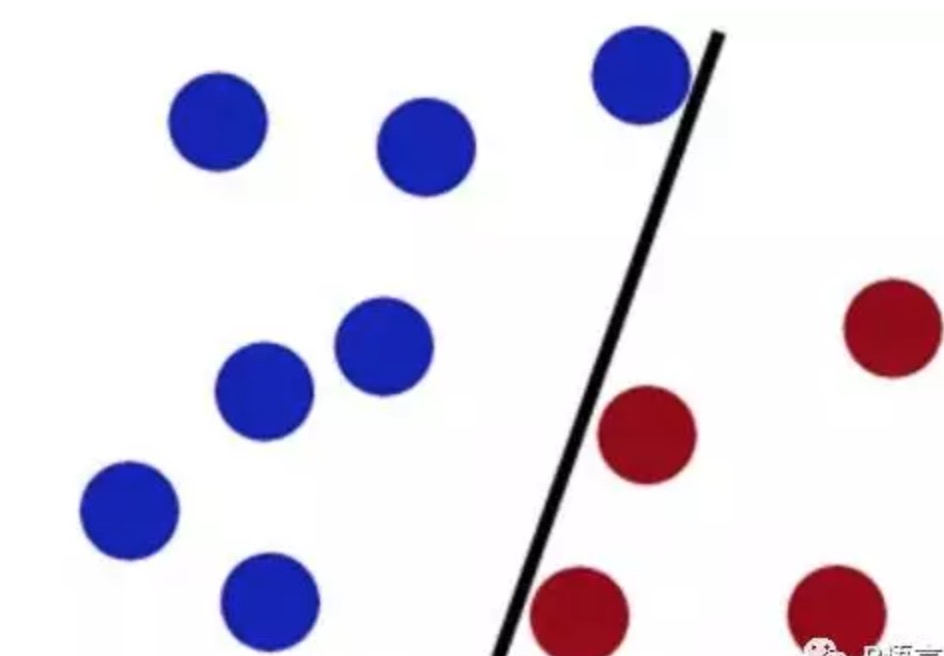
现在桌子上有两种颜色(红色和蓝色)的球需要分类(如图),我们有一根棍子作为工具,如何才能准确的分类呢?

我们不用多考虑,直接把棍子放中间一放即可:
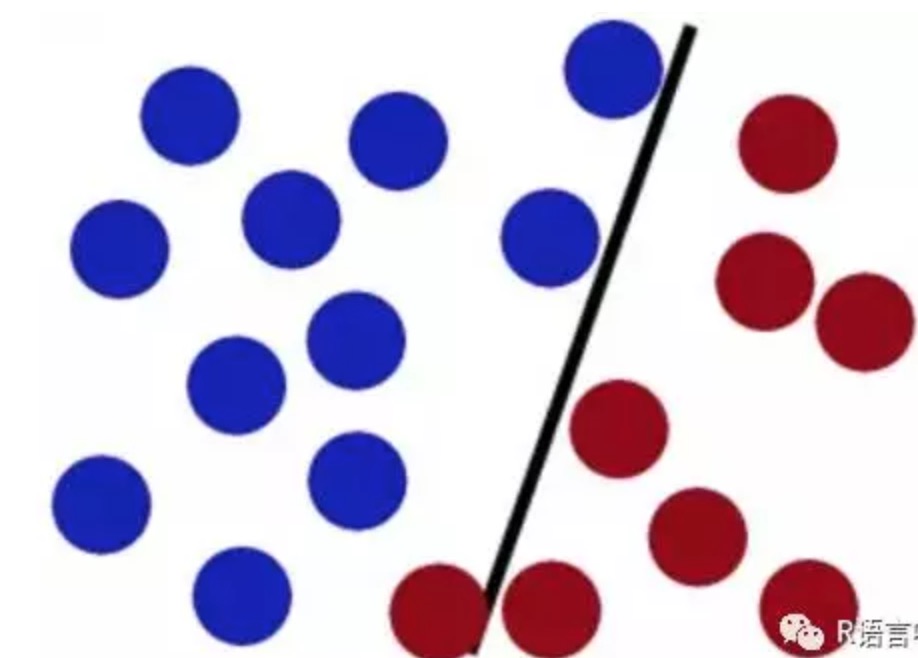
但如果这时候桌子上有更多的球,可能这个只能直线划分的棍子就不能完美的划分了,可能会有个别被划错。
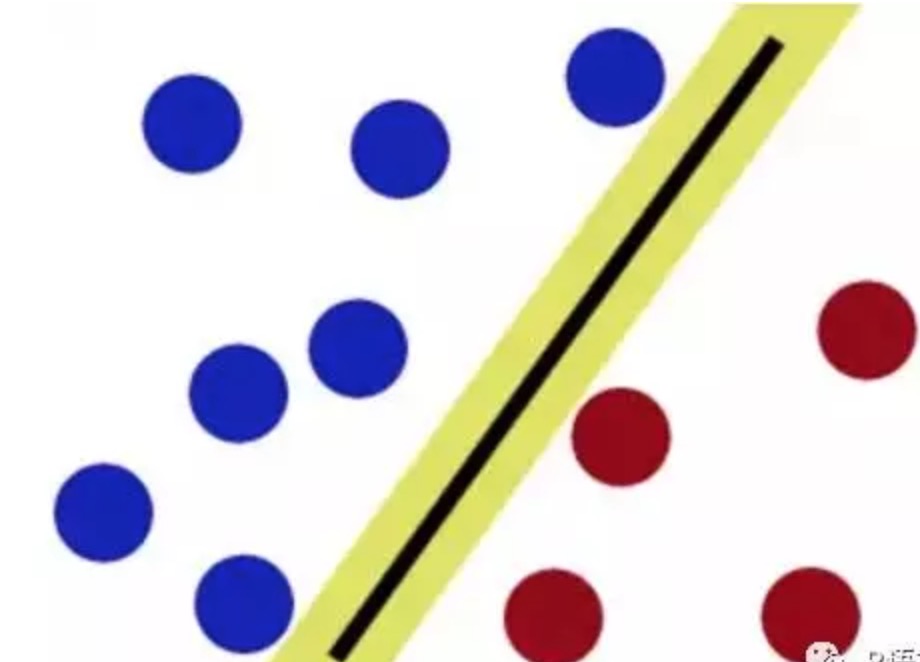
SVM便是将你手上的棍子放在最佳位置,这个最佳位置使得棍子两边的分类球有着最大的间隔
但是,如果两种颜色的球被混合到一起了。

用直直的棍子肯定就无法分隔了。这时候:猛地一拍桌子,所有的球顿时都飞到了空中,说时迟那时快,闪电般的抄起一张纸,刷的一下就飞到两种球中间,成功的将两种球分开了。
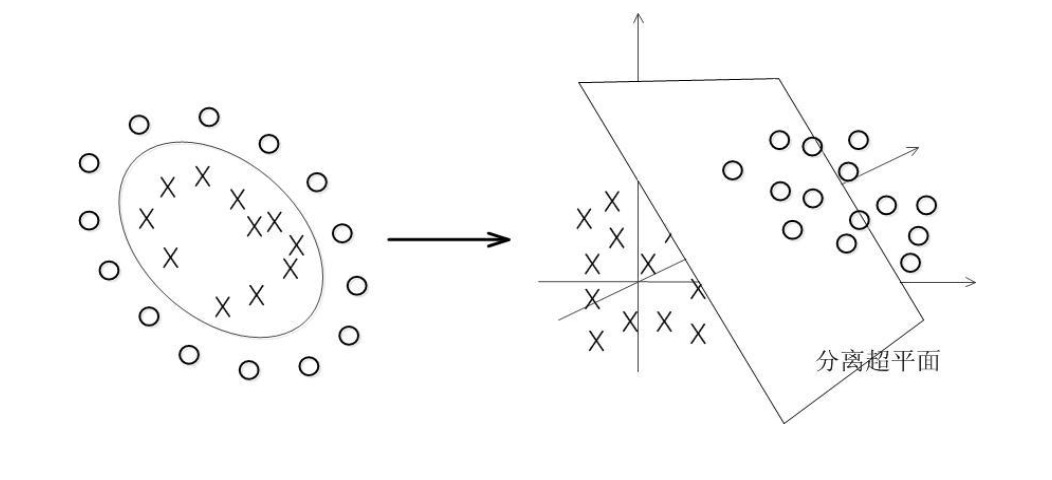
从平面上看,这些球就好像被一条曲线给分开了。
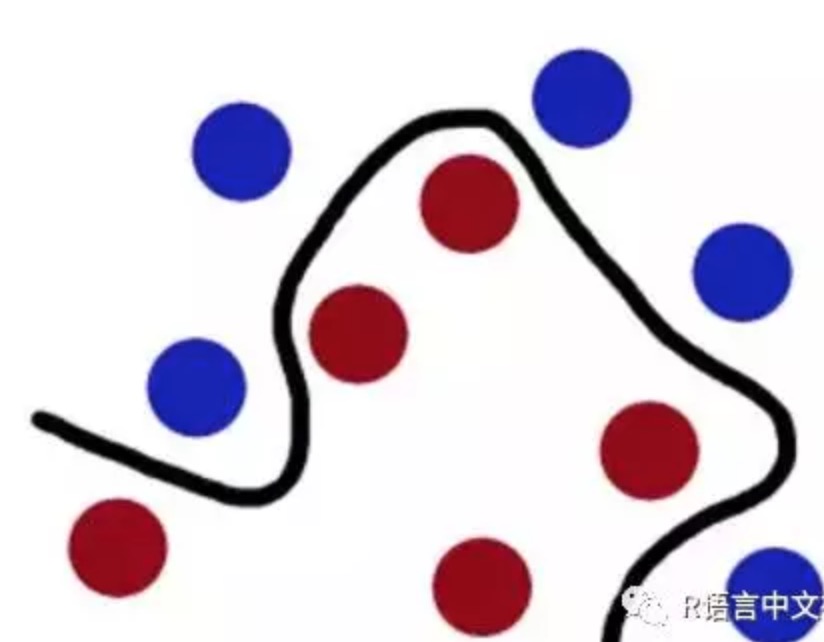
SVM算法中:这些球被称为数据,棍子被称之为分类器,使棍子两边间隔最大的方法叫做最优化,拍桌子那个技术被叫做核技术,那张被你抄向空中的纸叫做超平面,棍子由直线变成曲线便叫做软化。
在二维的空间中,我们需要做的是,找到一条线(一维),离两种球的距离都是最远。在三维空间中就是要找到一个面(二维),离两种球的距离都远。这里的二维,三维可以理解为实际应用中某事物的两个属性值或者三个属性值。即:我们要根据同一类事物同一属性不同的值,对事物进行区分。
既然是属性,就有可能有很多种,可能有成百上千个属性。比如 N 种,我们要找的实际上是一个 N-1 维的分界的超平面。
理论基础
svm 的目的是寻找一个超平面来对样本根据正例和反例进行分割。看上去象简单的线性回归。其实有非常大的区别。首先,SVM 要找出线性回归最优的情况;另外,非线性的时候也可以用SVM。
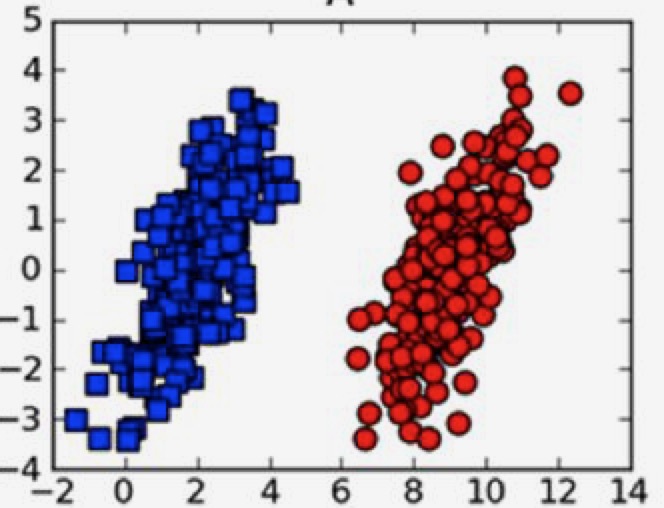
象这种,我们可以找出一条直线,把两种点完全分隔开,这种情况叫做线性可分。
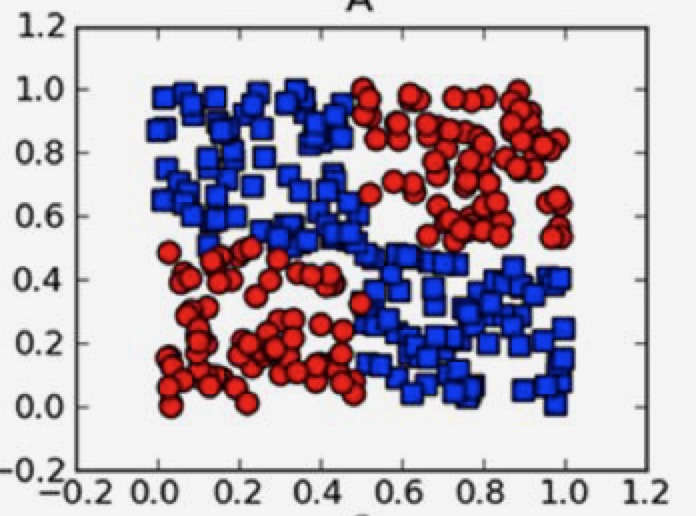
这种情况下,没法找出一条直线把两种点分隔,就叫线性不可分。
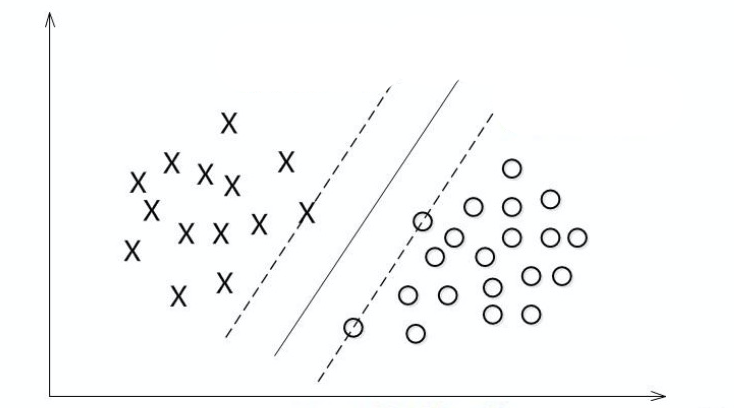
还有一种介于上面两种情况之间的状态:
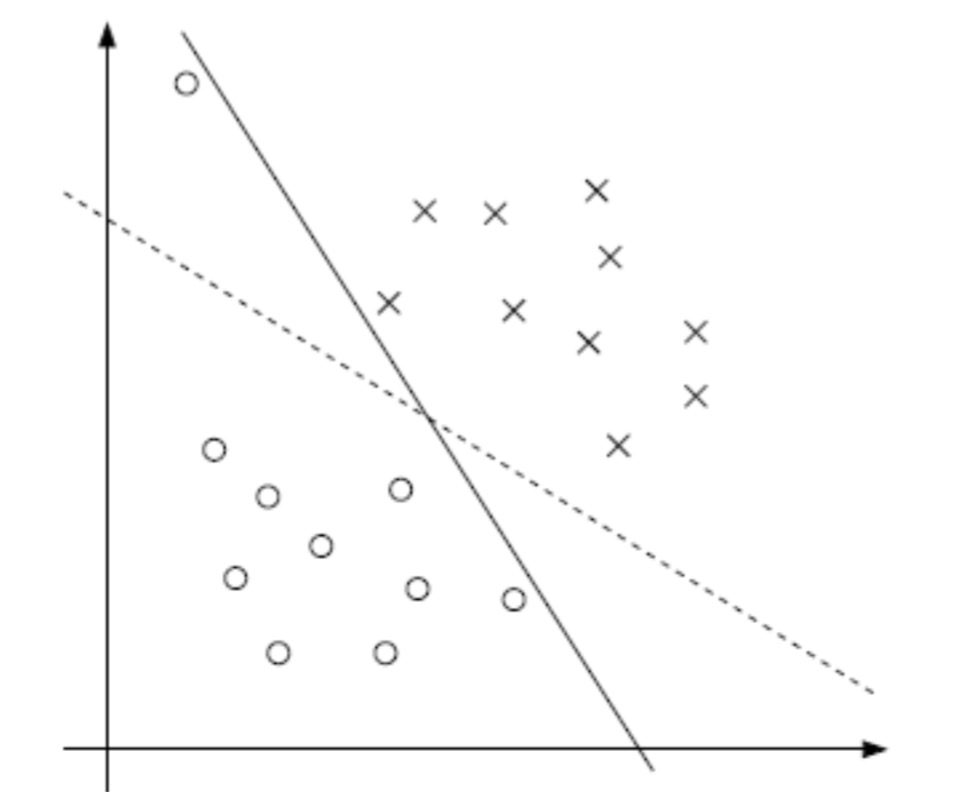
如图中虚线部分,看上去比实线更合理,但左上角有一个点是分错了的,但我们忽略掉这个点,选择虚线的划分算法。为了大多数的结果更准确。
SVM的核心思想是尽最大努力使分开的两个类别有最大间隔,这样才使得分隔具有更高的可信度。而且对于未知的新样本才有很好的分类预测能力(在机器学习中叫泛化能力)
那么怎么描述这个间隔,并且让它最大呢?SVM的办法是:让离分隔面最近的数据点具有最大的距离。
通俗的来说,我们可以这样:找出两个分类最近的两个点,在这两点上画出两条平行线;这两条线的中线就是分隔线。
假定所有的点都满足这样的表达式:y = f(w, x);该函数返回的值是 -1 或 1,用来表示某点属于哪个分类。记得 logistic 回归里面,我们是将 0 和 1 做为两个不同分类的标记。这里则改成 1 和 -1 。这和SVM的处理方式是有关系的。因为SVM是要找出三条互相平行的线,左边一条表示属于分类 1 的点,最右边的表示属于分类 2 的点,中间的是边界线。所以,如果我们让左边的函数值为 1,右边的为 -1,正好中间的就是 0。这样方便计算,如果我们还使用 0 和 1,则中间边界线的值就是 1/2 了。
其实我们可以把函数的值定义成做任意值,比如 10,100;只不过这种情况下,w 和 b 的值稍有不同,会做一些等比例放大或缩小。如:w * x + b = 100,可以把它转换为:(w * x) / 100 + b/100 = 1,所以,我们可以把函数值定义为做任意的值。只是最终求出来的 w 和 b 不同。不过,为了求解方便,我们把值定义为 1 和 -1,让中间值是 0。而且 1 和 -1 在运算的时候只相当于一个正负号,就更方便了。
现在有这样的一个分隔线,它的函数表达式是 wTX + b; 那么,任意一个点到分隔线的距离就是 label * (wTX + b), 其中 label 表示它的类别,值是 1 或 -1。不管点是在分隔线的哪边,该距离会下都是正数,运算起来比较方便。
现在,我们就要通过这三条线,找出公式 y = f(wTX + b) 中的 w 和 b 的值。
H1: y = wTx + b = +1 和 H2: y = wTx + b = -1

在这两个超平面上的样本点也就是理论上离分隔超平面最近的点,是它们的存在决定了H1和H2的位置,支撑起了分界线,它们就是所谓的支持向量,这就是支持向量机名称的由来。
有了这两个超平面就可以顺理成章的定义上面提到的间隔(margin)了,二维情况下 ax+by=c1和 ax+by=c2 两条平行线的距离公式为:
( |C1 - C2| ) / ( √a2 + b2 )
在这里,c1 = 1, c2 = -1。所以,距离 m = 2 / ( √a2 + b2 ) = 2 / ||w||
||w||: 范数,结果为w向量的各个元素的平方和的开平方
注意:上面的 label * (wTX + b) 是函数距离。不是几何距离。比如,我们同时缩小或放大几倍 w 和 b,该函数没有变化,但计算的函数距离即变了。所以我们要用几何距离来代替,即:label * (wTX + b) / ||w||。这里涉及到平面几何的推导。
H1和H2两个超平面的间隔为 2 / ||w||,即现在的目的是要最大化这个间隔。等价于求最小化 ||w||,为了之后的求导和计算方便,进一步等价于最小化 1/2 * ||w||2, 因为如果 1/2 * ||w||2 最小,||w|| 肯定是最小。不过,转换后我们计算起来要更方便。
根据上面的分类,则有:
wTxi + b >= 1, yi = 1
wTxi + b <= -1, yi = -1
只有有线 h1 和 h2 上的值才等于 1 和 -1,而其它的点对应的值则是 >1 或 <-1
不等式综合起来就是:
yi(wTxi + b) -1 >= 0
那么,现在的问题就变成了: 在 yi(wTxi + b) -1 >= 0 条件下,求 1/2 * ||w||2 的最小值。在它取最小值的时候,w 和 b 的值就是我们需要的最佳系数。这时候,wTx + b = 0 是分割线的函数表达式。
这里可以用拉格朗日乘子法,它是专门用来解决函数在约束条件下极值的。通过求解与原问题等价的对偶问题(dual problem)得到原始问题的最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
那什么是拉格朗日对偶性呢?简单来讲,通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier)α, 将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题。上面的约束条件和求极值整合为:
L(w, b, a) = 1/2 * ||w||2 - ∑αi(yi(wTxi + b) - 1)
对 w 和 b 求偏导,得到: w = ∑αiyixi
这里就可以看出:如果 α 为 0,则不管 x 取什么值,都不会影响结果;也就是说 α 为 0 的这些点是非支撑向量。也就是说,我们要找的就是那些 α 不为 0 的,它们就是支撑向量。
∑αiyi = 0
这个结论带来的结果是,我们在推算 α 时,要成对的进行;当我们调高一个 αi 的值时,一定要相应调低另外一个 αj 的值,以满足这个要求。
将该式带回上面拉格朗日公式中。得到结论:
L(w, b, a) = ∑αi - 1/2 ∑αiαjyiyjxixj
此时的拉格朗日函数只包含了一个变量,那就是 α。
现在就是要求 max ∑αi - 1/2 ∑αiαjyiyjxixj
条件是:∑αiyi = 0 且 α >= 0
到目前为止,我们都是假设数据是线性可分的。但实际中往往不这么理想。于是我们引入松弛变量 ξ,且 ξ >= 0 。允许有些数据出现在错误的位置。
这时候,前面的不等式:yi(wTxi + b) -1 >= 0 就变成了:
yi(wTxi + b) -1 + ξ >= 0
要求的最小值从 1/2 * ||w||2 变为:1/2 * ||w||2 = C∑ξ
后面拉格朗日表达式等都要经过一系列的变化。最终发现要求的变成:
max ∑αi - 1/2 ∑αiαjyiyjxixj
条件是:∑αiyi = 0 且 C >= α >= 0
按照坐标上升的思路,我们首先固定除 α1 外的所有参数,然后在 α1 上求极值。但由于要保证 ∑αiyi = 0。所以,在对 α1 进行微量改变的时候,需要对另外一个 α 进行相反的改变。
这里,我们假定取 α1 和 α2 进行优化。根据已有公式得到:
α1y1 + α2y2 + ∑αiyi = 0
其中 ∑ 里,i 取值是从 3 到 n。
于是得到 α1y1 + α2y2 = -∑αiyi
在我们把现在的各个 α 称为 old,调整后的 α 值称为 new,则有:
α1newy1 + α2newy2 = α1oldy1 + α2oldy2 = -∑αiyi
等号右侧的各个 α 都是固定值,于是右侧是个固定的值。我们把它记为 θ:
α1newy1 + α2newy2 = α1oldy1 + α2oldy2 = θ
y1 和 y2 是两个样本点的标签,取值只可能是 1 或 -1。
当它们两者相等时,它们是同号。如果两者都是 1,表达式是:
α1new + α2new = α1old + α2old = θ
因为 α1new 是在 0 - C 之间,所以假设α1new = 0,那么 α2new 可以取到最大值为θ,也就是 α1old + α2old。而 α2new又不能大于 C,所以其最大取值为 min(C, α1old + α2old)。
同理如果 α1new = C,那么 α2new 可以取到最小值为 θ − C,也就是 α1old + α2old − C,而 α2new 最小不能小于0。所以α2new 的下限值就为 max(0, α1old + α2old−C)。
如果 y1 和 y2 相等取 -1 呢?
−α1new − α2new = −α1old − α2old = θ
两边乘以 -1,就是 α1new + α2new = α1old + α2old = -θ,因为不知道−θ是多少,不过一个字母而已,那么用θ代替−θ吧,接下来的讨论过程一模一样。从而属于同类别的时候 α2new 上下限就有了。同理去计算下不同类的时候的上下限。最终的结果是:
if y1 ≠ y2 有 L = max(0, α2old − α1old), H = min(C ,C + α2old − α1old)
if y1 = y2 有 L = max(0, α2old + α1old − C), H = min(C, α2old + α1old)
到这只是给出了 α2new 的范围。
再看一下这个结论:
α1newy1 + α2newy2 = α1oldy1 + α2oldy2 = θ
两边都分别乘以 y1,得到:
α1newy12 + α2newy1y2 = α1oldy12 + α2oldy1y2 = θy1
y12 肯定等于 1,则有:
α1new + α2newy1y2 = α1old + α2oldy1y2 = θy1 = -y1∑αiyi = -∑αiyiy1
∑ 里的取值从 3 开始。
回到原来的问题,我们要求的是
L(w, b, α) = W(α) = ∑αi - 1/2 ∑αiαjyiyjxixj 的最大值。
且有 ∑αiyi = 0, 0 <= αi <= C
经过对偶处理,该问题又可以转换为:
求最小:W(α) = 1/2 ∑∑yiyjK(xi, xj) - ∑αi
我们把 α1 和 α2 分离出来,得到:
W(α) = W(α1) + W(α2) + W(α3…αn)
= 1/2 * K11α12 + 1/2 * K22α22 + y1y2K12α1α2 + y1α1v1 + y2α2v2 - α1 - α2 + W(α3…αn)
其中:
K 表示矩阵的点乘,K22 = x2 * x2, K11 = x1 * x1
v 是一个关于 α1, α2, y1, y2 的表达式:
v = ∑yjαjKij
∑ 里,j 从 3 开始取值
可以看到公式的后面部分和 α1, α2 没关系。又由于有前面的等式:
α1newy1 + α2newy2 = α1oldy1 + α2oldy2
old 是调整之前的值,是已知的。所以,我们可以把 α1 表示为 α2 以及一些已经值的表达式。
α1new = α1old + y1y2(α2old - α2new)
我们要对最后这个值求最小,于是可以求导数再让它等于 0 。就可以算出 α2new:
α2new = α2old - y2(E1 - E2) / η
其中,E表示推测值和实际值的误差。η = 2K(x1, x2) - K(x1, x1) - K(x2, x2)
至此,α1new,α2new 就全部求出来了。然后再通过:
w = ∑αiyixi
可以算出权重值。
对于在边界上的点(支撑向量),它们有:yi(w * x + b) = 1 的等式。然后把bnew对应等式中相同的部分用bold对应的等式里面的东西替换掉,比如说里面有一个求和,拆开后是从α3以后的求和(因为α1,α2要用),这个求和在前后是一样的替换掉。那么一顿替换化简以后对应α1的就会有一个b1new,同理对于α2的就会有一个b2new,他们的最终结果如下:
b1new = bold − E1 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x1, x2)
b2new = bold − E2 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x2, x2)
那么每次更新会出来两个b,选择哪个呢?谁准就选谁,那么怎么判断准不准呢?就是变换后的哪个α在0-C之间,也就是在分界线的边界上,也就是属于支持向量了,那么谁就准。于是就给一个判断:
if 0 ≤ α1new ≤ C, b = b1new
if 0 ≤ α2new ≤ C, b = b2new
其它情况下: b = (b1new + b2new) / 2
至此,所有的数据都能求出来了。现在总结一下 SMO 的过程:
选择两个α,看是否需要更新(如果不满足KKT条件),不需要再选,需要就更新。一直到程序循环很多次了都没有选择到两个不满足KKT条件的点,也就是所有的点都满足KKT了,那么就大功告成了。 从计算上来看,过程大致是:
1.初始化 α 为一个内容全为 0 的矩阵;初始化 b = 0。选取一对样本 x1 和 x2,根据 f(x) = wx + b 以及 w = ∑αyx,得到各自的预测值 y1 和 y2,然后可以算出和真实值之间误差 E1 和 E2。并将 α1 和 α2 做为 α1-old 及 α2-old 保留备用。
2.取其中一个 α1,得到它的取值范围 L 和 H,并裁剪到 [0, C] 之间。如果 L 和 H 的值相等,选取另外两个样本重复前面的步骤。
3.计算 η = 2 * K(x1, x2) - K(x1, x1) - K(x2, x2)
4.根据 η 的值计算 α1-new = α2old - y2(E1 - E2) / η。并将 α1-new 也裁剪到 [0, C] 之间。
5.由于 α1-new 相对 α1-old变了,由于要满足 ∑αy = 0,所以要对 α2-old 也进行一定调整,调整后的值是 α2-new, 它调整的值和 α1-new 相对 α1-old 的量相等,但方向相反。
6.根据公式
b1new = bold − E1 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x1, x2)
b2new = bold − E2 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x2, x2) 算出 b1 和 b2 的值。
再根据当前 α1new 和 α2new 的值判断哪个值对应的 b 更合理。
7.至此,w, b 的值在上述步骤中都调整过一次。现在要做的就是重复 N 次,并且每次选取不同的样本进行计算,以保证参数的泛化能力。
最终当对所有的样本,参数都没法再调整时,这时的参数就是最优参数。当有新的数据过来时,我们把它代入到新参数的公式中,计算得到的值就应该是它的真实值。
案例:简单 smo 算法实现
# -*- coding: utf-8 -*-
from numpy import *
from time import sleep
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0, m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 数据集、类别标签、常数C(松驰变量)、容错率、退出前最大循环次数
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
# 列表转化为矩阵.
dataMatrix = mat(dataMatIn)
# 对标签列表进行了转置,最终它是一个列向量
labelMat = mat(classLabels).transpose()
# 设置一个默认的常量,在后面的优化中不断变化
b = 0
# 数据集的大小 m 是行数;n是列数
m, n = shape(dataMatrix)
# 构建一个空的向量.行数和数据集一样,只有一列
# 它是函数的系数.通过对该系数进行微调,找到最合适的值
alphas = mat(zeros((m, 1)))
iter = 0
# 开始循环.循环的最大次数是我们自己定义的
while (iter < maxIter):
# 表示当前的 alpha 值是否已经优化过
alphaPairsChanged = 0
# 对每个训练数据集,都进行遍历
for i in range(m):
# 分类函数是 f(x) = wx + b
# 而 w = ∑αyx, 所以 f(x) = (∑αyx)*x + b = ∑αy<xi, xj> + b, xj 是样本,xi 是待预测的数据
# 第 i 个样本的预测值
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
# 计算得的值和实际值之差就是当前参数下的误差值
Ei = fXi - float(labelMat[i])
# 如果误差太大,就需要对参数进行优化
# 如果 alphas 的值等于了 0 或 C,表明值在边界上,它不能再优化了。就直接退出
if ((labelMat[i] * Ei < - toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
# 从所有的测试样本中随机取一个
j = selectJrand(i, m)
# 根据公式计算随机取值的预测值
fXj = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
# 计算随机样本计算值的误差
Ej = fXj - float(labelMat[j])
# 将两个样本调整前的 α 复制出来.做为 α-old,方便后面计算 α-new
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
# label 的值只可能是 1 或 -1
# 如果 labelMat[i] 和 labelMat[j] 不相等,表示它们不同符号.
# 如果两者相等. 则两者可能同为 1 或 -1
# L 是 alpha 能取值的最小范围, H 是最大范围.但我们要让 alpha 尽量往该范围的中心值靠
# if y1 ≠ y2 有 L = max(0, α2old − α1old), H = min(C ,C + α2old − α1old)
# if y1 = y2 有 L = max(0, α2old + α1old − C), H = min(C, α2old + α1old)
# 随着计算的进行,会对各个 alpha 进行调整.但我们保证它的值是在 0--C 之间
# 当 L 和 H 相等时,表明没办法再调整了
if labelMat[i] != labelMat[j]:
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
# print "L: %s , H: %s" % (L, H)
if L == H:
print "L==H 无法再优化.对下一个数据进行优化"
continue
# η = 2K(x1, x2) - K(x1, x1) - K(x2, x2)
eta = 2.0 * dataMatrix[i, :]*dataMatrix[j, :].T - dataMatrix[i, :]*dataMatrix[i, :].T - dataMatrix[j, :]*dataMatrix[j, :].T
if eta >= 0:
print "eta>=0"
continue
# α2new = α2old - y2(E1 - E2) / η
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
# 保证参数在 0 - C 之间
alphas[j] = clipAlpha(alphas[j], H, L)
# 检查变化后的系数和之前的变化量.如果量不够,说明当前的 α 已经没什么好调整
# 取下一对 α 值调整
if (abs(alphas[j] - alphaJold) < 0.00001):
print "j 没多少变化量了.直接进行下一个样本的训练"
continue
# 对 i 进行修改,修改量与 j 相同,但方向相反.以保证 ∑αy = 0
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
# 通过之前得到的各个值.计算常数项.
# b1new = bold − E1 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x1, x2)
# b2new = bold − E2 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x2, x2)
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
# 根据条件,判断哪个 b 的值才是更合理的
# if 0 ≤ α1new ≤ C, b = b1new
# if 0 ≤ α2new ≤ C, b = b2new
# 其它情况下: b = (b1new + b2new) / 2
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
# 表示当前参数做过修改
alphaPairsChanged += 1
print "第 %d 次比较. i:%d, 参数调整 %d 次" % (iter, i, alphaPairsChanged)
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print "循环次数: %d" % iter
return b, alphas
dataArr, labelArr = loadDataSet('testSet.txt')
b, alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
print b
# 支持向量个数
print shape(alphas[alphas > 0])
# 支持向量
for i in range(100):
if alphas[i] > 0.0:
print dataArr[i], labelArr[i]
优化版SMO
测试数据 testSet.txt 里的数据如下:
3.542485 1.977398 -1
3.018896 2.556416 -1
7.551510 -1.580030 1
2.114999 -0.004466 -1
8.127113 1.274372 1
7.108772 -0.986906 1
总共有 100 条数据。上面的代码运行需要 4 秒左右。如果有 100 万条数据呢,这个效率肯定是不能接受的。回头看上面的逻辑,数学计算方面是无法改变的。但我们选择两个点的方式是可以改变的。目前是采用遍历测试样本做为外循环,然后在内部随机选择一个其它的样本做为内循环,这样会有许多重复的计算。当 alpha 是 0 或 C 时,表明它在边界上,无法再优化。我们其实可以把这一部分点跳过,不参与计算。这样,我们就需要有一个列表来记录各个 alpha 的值并且在计算时跳过边界值。过程是:
选择第一个 alpha,并计算得到 Ei,然后算法通过内循环选择第二个;选择的方法是:先计算各个计算值和真实值的误差 Ej,当 Ei - Ej 的值最大值,选择当前这两个值进行优化。
代码如下:
# -*- coding: utf-8 -*-
from numpy import *
from time import sleep
def loadDataSet(fileName):
dataMat = [];
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
# smo 运算中的一些数据,统一存放在该类中
class optStructK:
def __init__(self, dataMatIn, classLabels, C, toler):
# 数据矩阵
self.X = dataMatIn
# 结果矩阵
self.labelMat = classLabels
# 常量
self.C = C
self.tol = toler
# 样本集长度
self.m = shape(dataMatIn)[0]
# 初始化一个变量数据集.和样本一样的行数,只有一列.默认用 0 填充
self.alphas = mat(zeros((self.m, 1)))
# y = wt + b 中的常量 b
self.b = 0
# 初始化一个缓存集.用来存储各个样本集的误差.尺寸是 m * 2
# 行数和样本一样, 是 m。第一列是表示当前数据是否有效;第二列是实际的误差值.默认都用 0 填充
self.eCache = mat(zeros((self.m, 2)))
# 计算各样本在某参数下的误差值
# 计算函数值 wt + b,用它和真实的值相减,得到的值就是误差
def calcEkK(oS, k):
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
# 随机找另一个样本以配对优化
def selectJrand(i, m):
# 随机找一个和当前值不同的值
j = i
while (j == i):
j = int(random.uniform(0, m))
return j
# 修剪数据,保证它在取值范围内
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 选择另一样本配对优化的第二种方法
def selectJK(i, oS, Ei):
maxK = -1;
maxDeltaE = 0;
Ej = 0
# 将当前样本的误差值设置为 1 和误差中的较大值.
oS.eCache[i] = [1, Ei]
# 选择缓存数据里,第一列不为空的集合.这些数据就是有效数据
# 初始状态时列表为空
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if (len(validEcacheList)) > 1:
# 遍历缓存的数据.找一个误差最大的
for k in validEcacheList:
# 不要和自己比较
if k == i:
continue
Ek = calcEkK(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k;
maxDeltaE = deltaE;
Ej = Ek
return maxK, Ej
else:
# 初始状态时,没有符合要求的样本,先用随机选择法选取样本
j = selectJrand(i, oS.m)
Ej = calcEkK(oS, j)
return j, Ej
# 更新缓存数据集中的值.表明当前值已经优化过,且把优化后的误差值记入
# 后面它还可能被选中
def updateEkK(oS, k):
Ek = calcEkK(oS, k)
oS.eCache[k] = [1, Ek]
# 选择一对样本进行优化,并返回是否优化了
def innerLK(i, oS):
# 当前选择的参数的误差值
Ei = calcEkK(oS, i)
# 如果当前样本已经不可优化,直接返回
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
# 选择另一个样本,初始时是随机选择的,后面会从样本中选择误差值最大的值
j, Ej = selectJK(i, oS, Ei)
# 将两个样本调整前的 α 复制出来.做为 α-old,方便后面计算 α-new
alphaIold = oS.alphas[i].copy();
alphaJold = oS.alphas[j].copy();
# label 的值只可能是 1 或 -1
# 如果 labelMat[i] 和 labelMat[j] 不相等,表示它们不同符号.
# 如果两者相等. 则两者可能同为 1 或 -1
# L 是 alpha 能取值的最小范围, H 是最大范围.但我们要让 alpha 尽量往该范围的中心值靠
# if y1 ≠ y2 有 L = max(0, α2old − α1old), H = min(C ,C + α2old − α1old)
# if y1 = y2 有 L = max(0, α2old + α1old − C), H = min(C, α2old + α1old)
# 随着计算的进行,会对各个 alpha 进行调整.但我们保证它的值是在 0--C 之间
# 当 L 和 H 相等时,表明没办法再调整了
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print "L==H 无法再优化.对下一个数据进行优化"
return 0
# η = 2K(x1, x2) - K(x1, x1) - K(x2, x2)
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
if eta >= 0:
print "eta>=0"
return 0
# α2new = α2old - y2(E1 - E2) / η
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
# 保证参数在 0 - C 之间
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
# 将当前样本相应的值记入缓存
updateEkK(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print "j 没多少变化量了.直接进行下一个样本的训练"
return 0
# 对 i 进行修改,修改量与 j 相同,但方向相反.以保证 ∑αy = 0
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
# 同理,将 j 相应的值也记入缓存
updateEkK(oS, i)
# 通过之前得到的各个值.计算常数项.
# b1new = bold − E1 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x1, x2)
# b2new = bold − E2 − y1(α1new − α1old)K(x1,x1)−y2(α2new−α2old)K(x2, x2)
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[i,:] * oS.X[j,:].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j,:] * oS.X[j,:].T
# 根据条件,判断哪个 b 的值才是更合理的
# if 0 ≤ α1new ≤ C, b = b1new
# if 0 ≤ α2new ≤ C, b = b2new
# 其它情况下: b = (b1new + b2new) / 2
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
# 处理完毕.返回 1
return 1
else:
# 未处理.返回 0
return 0
def smoPK(dataMatIn, classLabels, C, toler, maxIter):
# 初始化信息
oS = optStructK(mat(dataMatIn), mat(classLabels).transpose(), C, toler)
iter = 0
# 是否从整个样本中选取参数对.初始时是这样.随着优化的进行,就直接从缓存列表中进行选择
entireSet = True;
# 被修改的参数对计数
alphaPairsChanged = 0
# 遍历 N 次.每次都选两个参数进行优化.如果达到设定的处理次数,或者没有参数被改动了,退出处理
# 过程是:先把样本集中各个值都优化一次.后面就对非边界值进行优化,直到没有可优化的点;这时候再把整个样本集挨个优化一次。
# 这样循环着来,直到达到最大优化次数或者没有可优化的数据
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
# 处理整个样本集
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerLK(i, oS)
print "全量优化, 第 %d 次循环. 当前 i:%d, 修改值个数: %d" % (iter, i, alphaPairsChanged)
iter += 1
else:
# 非边界值优化
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerLK(i, oS)
print "非边界值优化, 第 %d 次循环.当前 i:%d, 修改值个数: %d" % (iter, i, alphaPairsChanged)
iter += 1
if entireSet:
# 全量优化后转变为边界优化
entireSet = False
elif (alphaPairsChanged == 0):
# 如果边界优化一遍循环下来一个值都没有被修改,那就再执行一次全量优化
# 如果全量优化下一个值都没被修改,外层的循环就会退出了
entireSet = True
print "iteration number: %d" % iter
return oS.b, oS.alphas
dataArr, labelArr = loadDataSet('testSet.txt')
b, alphas = smoPK(dataArr, labelArr, 0.6, 0.001, 40)
print b
# 支持向量个数
print shape(alphas[alphas > 0])
# 支持向量
for i in range(100):
if alphas[i] > 0.0:
print dataArr[i], labelArr[i]
使用上面的算法后,结果是秒出。 经过算法得到 alpha, b 的值后。我们就可以通过 alpha 得到 w 的值。于是预测值 wt + b 就可以得到了。如:
dataArr, labelArr = loadDataSet('testSet.txt')
b, alphas = smoPK(dataArr, labelArr, 0.6, 0.001, 40)
X = mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i,:].T)
# 预测
dataMat = mat(dataArr)
cat_result = dataMat[0] * mat(w) + b
print "预测结果: %s" % cat_result
如果结果大于 0,它属于 1 类;如果值小于 0,则属于 -1类。