欢迎来到夜宇工作间
这里是我的个人IT学习回忆录-
高可用架构
高可用架构
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
很多公司的高可用目标是4个9,也就是99.99%。这就意味着,系统的年停机时间为8.76个小时。
在小型公司或者项目初期,通常都是单点设计,一旦出现故障就直接停止服务了,应该尽量在系统设计的过程中避免单点。高可用保证的原则是“集群化”,或者叫“冗余”。挂了还有其他备机能够顶上。
有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
于是我们就得出结果:通过 冗余 + 自动故障转移 实现高可用
常见架构
常见的互联网服务架构是分层的:负载均衡、WEB服务、缓存、数据库。在各层,我们都可以进行各自的高可用架构。
负载均衡
负载均衡通常通过 LVS 或者 nginx 实现。如果我们要实现冗余,我们则需要多个负载均衡的服务器,并且需要一个虚拟IP。而自动故障切换则借助 keepalived 来实现。
WEB 服务
服务层通常是用集群的方式,在负载均衡这一层进行存活的检测。在反向代理的过程中,通过负载的策略,将请求转移到对应的机器上。对于挂掉的服务器,负载均衡这一层将它从集群中移出。
缓存
常用缓存有 memcached, redis。
memcached 支持分布式。采用的是一致性哈希的方式,我们需要自己实现冗余和请求的转发。
redis则有主/从的机制,同时也支持分布式集群。redis官方也有sentinel哨兵机制,来做redis的存活性检测。当redis主挂了的时候,sentinel能够探测到,会通知调用方访问新的redis,整个过程由sentinel和redis集群配合完成。
数据库
数据库这一核心层通常是读写分离、主从结构以及在这基础上更复杂的多主从同步及中继中从等方式。
故障转移也可以借助 keepalived。
核心概念
keepalived
Keepalived 有一个服务器列表,当它检查到有机器有故障时,就将它从列表中去除,正常后再加到列表中。这些都是全自动的,人工只需要修复坏的机器即可。
虚拟 IP
现在已经拥有一个公网 IP. 我们要访问一台服务器上的资源,只需要将该 IP 绑定到该台服务器上,然后进行资源的映射。
虚拟 IP 技术是指在 N 台机器上都绑定该 IP ,然后通过其它软件去控制将请求导到哪台机器上。不管到哪台机器上,因为它已经绑定了该IP的,请求都能正常响应。
由于 TCP/IP 数据传输时,数据包里包含了 IP, MAC, 内容等数据。而 MAC 是一致的,所以要实现请求的分组(即 虚拟 IP 动态转移), 需要对 TCP/IP 包的内容进行修改。
Keepalived 即可实现该功能。
对用户来说是和同一个IP打交道,实际上背后是N台机器。
Session 同步
session 是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,服务器会生成一个唯一的 SessionId, 做为一个 key, 它对应的 value 存在服务器上。
SessionId 是存在用户浏览器的 Cookie 中的,每次请求页面,都会将该值传到服务器。服务器去 session 存储空间查找该值对应的值,来进行一些身份验证,数据读取。所以你在浏览器上登录后,若清空 Cookie, 就要重新登录了。因为这时候没有 SessionId 传过去,服务器认为你是新用户在访问。
当我们用集群来解决访问压力时,可能会出现如下情况:
将整体服务划分成小块服务,然后放在二级域名中。(新浪新闻,新浪星座等都是单独的二级域名)部署到多台服务器上。多个频道共享一组服务器。
而在 PHP 中,session 默认是以文件的形式保存在本地服务器的磁盘上的(当然也可以选择存在 DB 中).这样的结果就是,SessionId 在不同机器上不一致,用户可能会访问的时候不停的登录。因为服务器不能去访问其它机器上的 Session.为了解决这种情况方法就产生了:
-
将 Session 的数据加密后存在 Cookie 中. 这样很省事,但由于每次请求都会提交 Cookie 中的内容,所以这样会占用一定的带宽,而且由于 http 请求头长度的限制,Cookie 中存放不了太多的东西。另外还需要进行加密解密,开销也是不小的.
-
基于数据库的 Session 共享 将 Session 存在 DB 中,各服务器就可共享了。通常选用内存表 Heap,以提高 Session 操作的读写效率。缺点是数据库的性能可能会成为站点的瓶颈。同时,Session 的变更频繁,要选用行级锁的引擎。并且要注意删除超时的 Session
-
基于 Memcache 的 Session 共享 Session 通过 SessionId 来关联存储的形式和 Memcache 完全吻合,而且 Memcache 就有数据过期机制,而且这货效率高。
总结: Memcache 和 MySQL 虽然都可以解决,但实际上,它们的效率也会成为整个系统的瓶颈。所以,最后不要出现需要 Session 共享的情况,也就是,和用户通信的,尽量保持在一台机器上。
会话保持
在典型的电子商务系统,或需要进行用户身份认证的在线系统中。一个客户要与服务器连着几次交互才能完成一笔交易或一个请求。对于这样的几个请求,负载均衡的时候就不能把它分散到不同的服务器上了。这种会话保持机制的实现:
Nginx 的实现:
upstream backend{ ip_hash; server 192.168.1.10:80 weight=4 max_fails=2 fail_timeout=30s; server 192.168.1.11:80 weight=2 max_fails=2 fail_timeout=30s; } upstream 模块的 ip_hash 机制能够将某个IP的请求定向到同一台服务器上。 location / { # 如果后端服务器返回 502,504,超时等.将自动把请求转发到 upstream 池中的另一台服务器中实现故障转移 proxy_next_upstream http_502 http_504 error timeout invalid_header proxy_pass http://backend; proxy_set_header Host www.mydomain.jp proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $remote_addr; }如果不加 proxy_set_header, 直接服务器上接收到请求的日志中会发现IP全是代理机器的IP。加上后会是用户实际的IP.
可参照: http://blog.sina.com.cn/s/blog_5f54f0be0100zvf5.html
VRRP(虚拟路由冗余协议)
对多台机器的默认网关进行冗余备份,当其中一台路由设备挂了时,备份路由接管转发工作。
原理: TPC/IP 协议中,设备之间不直接通信,它们通过自己所在网络的路由器,将数据包不停的转向下一个路由器,直到找到目的设备所在网络的路由器。而下一个路由是谁,有两种方法来知道:
- 动态学习;但需要每个路由器都支持这种形式,不现实。
- 静态配置;每个路由器上都存一份静态路由表,数据传输时,会从表中查出该IP对应的路由器地址,然后把包传过去。如果没有对应的,就会传到默认网关(默认的下一个路由器地址).
用静态方式的问题:如果有一个路由器坏了,那么所有将该路由器作为下一站或者作为默认网关的通信就中断了。即使自己配置了多个默认网关,如果不重启路由器也是无法生效的。
虚拟路由冗余协议就是用来避免静态指定网关的缺陷的。
VRRP 中有两组重要概念: VRRP 路由器(实体)和虚拟路由器; 主路由器和备份路由器。
一组VRRP路由器实体协同工作,就形成了虚拟路由器。该虚拟路由器对外来看是一个固定IP,一个固定MAC。
VRRP 组中有一个主路由器和一个或多个备份路由器。VRRP 会选择一台作为主的,负责响应和转发IP数据包。其它备份路由器处在等待状态。
如果主路由器发生故障,备份路由器会接管主路由器功能,不用改变IP和MAC。
一个VRRP路由器有唯一的标识,VRID(虚拟路由ID),范围是 0-255(不含 255), 所以,该组中最多 255 台主备。
该路由器对外表现的是唯一的虚拟MAC地址,格式是: 00-00-5E-00-01-{VRID} 不管谁当主路由器,该MAC都不再变。
VRRP 组之间通过 VRRP 控制报文进行通信。采用 IP 多播数据包,且只有主路由才能周期性的发送 VRRP 通告报文。
备份路由器连续三个通告周期收不到 VRRP 通告或收到的通告是优先级为 0 ,就会在所有的备份路由器中选一个优先级最高的作为主的。
优先级为 0 的情况是该路由器被设置成在VRRP组之外。所以实际上 VRID 是 1 - 254.
虚拟服务器: VS / NAT
实体 IP: 在网络的世界里,为了要辨识每一部计算机的位置,因此有了计算机IP 位址的定义。一个IP 就好似一个门牌!
例如,你要去微软的网站的话,就要去『207.46.197.101 』这个IP 位置!这些可以直接在网际网络上沟通的IP 就被称为『实体IP 』了。
虚拟 IP
不过,众所皆知的,IP位址仅为 xxx.xxx.xxx.xxx 的资料型态,其中, xxx为 1-255间的整数,
由于近来计算机的成长速度太快,实体的IP 已经有点不足了,好在早在规划IP 时就已经预留了三个网段的IP 做为内部网域的虚拟IP 之用。这三个预留的IP 分别为:
A级: 10.0.0.0 - 10.255.255.255 B级: 172.16.0.0 - 172.31.255.255 C级: 192.168.0.0 - 192.168.255.255
上述中最常用的是192.168.0.0这一组。
不过,由于是虚拟 IP,所以当您使用这些地址的时候,当然是有所限制的,限制如下:
- 私有位址的路由信息不能对外散播
- 使用私有位址作为来源或目的地址的封包,不能透过Internet来转送
当内部网络要访问外部的时候,就需要将内部地址转换成外网可用的地址,即:网络地址转换 Network Address Translation, NAT.
每次请求的报文头(目标地址,源地址,端口)都被正确改写。外部用户访问该网络时, 请求会被转到内部的某个 IP 上,然后报文的数据被改写。
目标机器处理完后把报文传给进行网络地址转换的设备(通常是路由器),这时候请求目标地址是该设备,然后返回的报文的报文头被改写成当前发起请求的地址.
这次交互完成.所以,每次请求都要在地址转换设备上中转一次。它的性能就会成为瓶颈。 我们的路由器就是用来做这个的。
我们的路由器的 IP 就是我们这个内部网络所有机器的外部 IP。
我们可以做如下设置: 将该路由器上所有的 80 端口的请求都转到内网的 192.168.2.222 (虚拟 IP)上。也可以转到其他任何一台连接到路由器上的机器上.
我们可以进行如下设置:
- 路由器将请求轮流解析到内部机器 A, B的内部 IP 上。[四层轮询的 LVS]
- 路由器将请求解析到 A 上,A, B 互相监视, 如果 A 挂了, B 将自己的 IP 设置成 A 之前的 IP。 这样可继续服务。[主 / 备]
这种办法的好处是用IP协议的,所以只要是支持TCP/IP的操作系统,只要一个公网IP放在调度机器上就成了,服务器组用私有IP。
不足的是,调度机器会承受很大的压力,因为每次请求和响应都会经过它。
虚拟服务器: VS / TUN
IP 隧道
大多数请求都有这种规律:请求报文较短,而响应很短。如平日我们看网站:提交的数据很少,但服务器返回的数据很多。
这时候想到的就是:将请求和响应分开。负载均衡的设备只负责响应请求,转发。而响应则直接返回给客户,不经过它。
调度器根据各个服务器的负载情况,动态地选择一台服务器,将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的服务器;
服务器收到报文后,先将报文解封获得原来目标地址为VIP的报文,服务器发现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。
在这里,请求报文的目标地址为VIP,响应报文的源地址也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道是哪一台服务器处理的。
这种方式解放了调度器,它只负责选择真实服务器,然后进行IP封装,转发。同样,它的问题就在于,使用它就必须支持 IP 隧道协议。
虚拟服务器: VS / DR
调度器和服务器组都必须在物理上有一个网卡通过不分段的局域网相连,即通过交换机或者高速的HUB相连,中间没有隔有路由器。
VIP地址为调度器和服务器组共享,调度器配置的VIP地址是对外可见的,用于接收虚拟服务的请求报文; 所有的服务器把VIP地址配置在各自的Non-ARP网络设备上,它对外面是不可见的,只是用于处理目标地址为VIP的网络请求。
调度器根据各个服务器的负载情况,动态地选择一台服务器,不修改也不封装IP报文,而是将数据帧的MAC地址改为选出服务器的MAC地址,再将修改后的数据帧在与服务器组的局域网上发送。
因为数据帧的MAC地址是选出的服务器,所以服务器肯定可以收到这个数据帧,从中可以获得该IP报文。 当服务器发现报文的目标地址VIP是在本地的网络设备上,服务器处理这个报文,然后根据路由表将响应报文直接返回给客户。
「Non-ARP 说明」arp (address resolution protocol),主要是确认网卡的物理地址用的,在三层是 ip,到了二层要通过 arp 协议确认哪个ip和哪个物理地址的对应关系,
如果一个网卡没有mac地址那么,这个网卡配置的ip就不会被外界知道,一般这样的ip只用于内部交流用我们称之为 Non-ARP,没有mac地址的网卡一般也只有本地的loopback 口,
在 lvs 的 Non-ARP 就是这个含义—- 没有 MAC 地址的网卡与 IP 只能在本机内做回环地址,不被外界所见。
和上面 VS/TUN 相比它不用 IP 隧道,通用性更强.但是要求真实服务器和调度器都有一块网卡,且连在同一物理网段上。
真实服务器的网卡不做 ARP 响应. 这种方式目前是最流行的。
那么,如果我们没有在同一个机房,连在一起的这么多机器,就可以选择 VS/TUN 或 VS/NAT,如果机器少,几台,或者不超过二十台,带宽足够的情况下,可以用 VS/NAT, 如果机器多,那就得用 VS / TUN 了。
案例
Nginx + Keepalived
两台 Nginx 通过 Keepalived 管理,作为代理。当然,也可以用 LVS + Keepalivd 但 Nginx 对高并发的处理及分发已经很优秀了,而且配置简单。
Nginx 中采用 ip_hash 进行会话保持。省去了存入 MySQL 或 Memcached 的开销。
Nginx_Master: 192.168.1.103 提供负载均衡 Nginx_BackUp: 192.168.1.104 负载均衡备机
Nginx_VIP_TP: 192.168.1.108 网站的 VIP 地址(虚拟 IP)
Real_Server1: 192.168.1.106 提供 WEB 服务 Real_Server2: 192.168.1.107 提供 WEB 服务
安装 Nginx (省略) http://blog.sina.com.cn/s/blog_5f54f0be0100yqm7.html
安装 Keepalived
地址: http://www.keepalived.org/download.html
wget http://www.keepalived.org/software/keepalived-1.2.7.tar.gz tar -zxf keepalived-1.2.7.tar.gz cd keepalived-1.2.7 ./configure --sysconf=/etc --prefix=/usr/local/keepalived --with-kernel-dir=/usr/src/kernels/2.6.32-358.2.1.el6.x86_64/或
./configure --sysconf=/etc --prefix=/usr/local/keepalived --with-kernel-dir=/usr/src/kernels/2.6.32-358.6.2.el6.i686/–sysconf 指定了配置文件的地址.即:/etc/keepalived/keepalived.conf
–prefix 指定了安装目录
–with-kernel-dir 指定使用内核源码中的头文件,即 include 目录.只有使用 LVS 时才需要这个参数,其它的时候不需要。
报错:
configure: error: Popt libraries is required解决:
yum install popt-devel再 configue .成功后提示:
Keepalived configuration ------------------------ Keepalived version : 1.2.7 Compiler : gcc Compiler flags : -g -O2 Extra Lib : -lpopt -lssl -lcrypto Use IPVS Framework : Yes IPVS sync daemon support : Yes IPVS use libnl : No Use VRRP Framework : Yes Use VRRP VMAC : Yes SNMP support : No Use Debug flags : No然后安装:
make make install设置成为服务并开机自动启动:
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/ /etc/rc.d/init.d/keepalived status chkconfig --add keepalived chkconfig keepalived on设置主机上的配置文件内容:
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { notification_email { sunyu@easymobi.cn wuxuegang.123@163.com } notification_email_from pub@easymobi.cn smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 # 此处是主 Nginx 的 IP 地址. mcast_src_ip 192.168.1.103 # 该机的 priority(优先) 为 100 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111222 } virtual_ipaddress { 192.168.1.108 } }前面的结构那里已经规定好了 VIP 和 主备机的 IP, 所以这里按上面的填。
备机的配置文件:
! Configuration File for keepalived global_defs { notification_email { sunyu@easymobi.cn wuxuegang.123@163.com } notification_email_from pub@easymobi.cn smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state SLAVER interface eth0 virtual_router_id 51 # 此处是备 Nginx 的 IP 地址. mcast_src_ip 192.168.1.104 # 该机的 priority(优先) 为 99 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111222 } virtual_ipaddress { 192.168.1.108 } }这时候
ping 192.168.1.108是不通的.然后在两台机器上分别启动 keepalived 服务。这时候再 ping 192.168.1.108 .通了.
实际上这时候 108 是被绑到主机上的。在主机上: 查看系统日志:
tailf /var/log/messages May 29 18:32:16 localhost Keepalived_vrrp[27731]: Opening file '/etc/keepalived/keepalived.conf'. May 29 18:32:16 localhost Keepalived_vrrp[27731]: Configuration is using : 62906 Bytes May 29 18:32:16 localhost Keepalived_vrrp[27731]: Using LinkWatch kernel netlink reflector... May 29 18:32:16 localhost Keepalived_healthcheckers[27729]: Using LinkWatch kernel netlink reflector... May 29 18:32:16 localhost Keepalived_vrrp[27731]: VRRP sockpool: [ifindex(2), proto(112), fd(11,12)] May 29 18:32:17 localhost Keepalived_vrrp[27731]: VRRP_Instance(VI_1) Transition to MASTER STATE May 29 18:32:18 localhost Keepalived_vrrp[27731]: VRRP_Instance(VI_1) Entering MASTER STATE May 29 18:32:18 localhost Keepalived_vrrp[27731]: VRRP_Instance(VI_1) setting protocol VIPs. May 29 18:32:18 localhost Keepalived_vrrp[27731]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.1.108 May 29 18:32:18 localhost Keepalived_healthcheckers[27729]: Netlink reflector reports IP 192.168.1.108 added可以看到.VRRP(虚拟路由冗余协议)已经启动.我们可以通过命令 ip addr 来检查主 Nginx 上的 IP 分配情况.
[root@localhost ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 00:15:c5:ef:53:8c brd ff:ff:ff:ff:ff:ff inet 192.168.1.103/25 brd 192.168.1.255 scope global eth0 inet 192.168.1.108/32 scope global eth0 inet6 fe80::215:c5ff:feef:538c/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:15:c5:ef:53:8e brd ff:ff:ff:ff:ff:ff可以看到 VIP 地址已经绑定到主 Nginx 机器上:
inet 192.168.1.108/32 scope global eth0我们通过 tcpdump 抓包:
[root@localhost ~]# tcpdump vrrp tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes 13:38:27.797982 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:28.794693 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:29.794518 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:30.798581 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:31.795902 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:32.804050 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:33.801191 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20 13:38:34.798793 IP htuidc.bgp.ip > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20发现:优先级高的一方(prio 100) 通过 VRRPv2 获得 VIP 地址。该 VRRPv2 包的发送极有规律,一秒发送一次(可配置)。
这样,一个 Nginx + Keepalived 的架构就完成了。接下来可以完善一下,加上实时监控,如果发现负载均衡的 Nginx 出现问题,就将该机器上的 Keepalived 服务停掉。
nginx_check.sh:
#!/bin/bash while : do nginxpid = 'ps -C nginx --no-header | wc -l' if[ $nginxpid -eq 0 ];then service nginx start sleep 3 nginxpid = 'ps -C nginx --no-header | wc -l' echo $nginxpid if[ $nginxpid -eq 0 ];then service keepalived stop fi fi sleep 3 done然后让该脚本一直在后台运行:
nohup /etc/nginx_check.sh或者将它添加成服务,让它开机自启动: http://blog.sina.com.cn/s/blog_5f54f0be0101b3bs.html
测试:
在两台机器的 web 服务器上分别放一个 index.html, 里面内容分别是自己机器的IP. 通过VIP访问:
http://192.168.1.108/index.html 发现显示的是主机的IP.
此时,关掉主机的 nginx, 这时候由于上面的监控脚本。主机的 keepalived 也会关闭。这时候再访问上面地址,发现显示的是备机的IP。可见,切换成功。
LVS + Keepalived
LVS 是通过 IPVS 模块来实现的。IPVS是LVS集群的核心,主要用于完成用户的请求到达负载调度器后,如果将请求发送到每个真实服务器节点上的,服务器如何返回数据给用户。
要验证是否支持,用如下命令:
[root@localhost keepalived]# modprobe -l | grep ipvs kernel/net/netfilter/ipvs/ip_vs.ko kernel/net/netfilter/ipvs/ip_vs_rr.ko kernel/net/netfilter/ipvs/ip_vs_wrr.ko kernel/net/netfilter/ipvs/ip_vs_lc.ko kernel/net/netfilter/ipvs/ip_vs_wlc.ko kernel/net/netfilter/ipvs/ip_vs_lblc.ko kernel/net/netfilter/ipvs/ip_vs_lblcr.ko kernel/net/netfilter/ipvs/ip_vs_dh.ko kernel/net/netfilter/ipvs/ip_vs_sh.ko kernel/net/netfilter/ipvs/ip_vs_sed.ko kernel/net/netfilter/ipvs/ip_vs_nq.ko kernel/net/netfilter/ipvs/ip_vs_ftp.ko如果类似上面,表示支持。 上面列出的是LVS支持的算法。如:
- rr 表示分发的时候是轮询;Round Robin
- wrr 表示加权轮询;Weight Round Robin
- lc 表示最少连接,least connection
- wlc 加权最少连接,Weighted Least-Connection
- dh 目标地址哈希
- sh 源地址哈希
- sed 最少希望延迟
- nq 永不排队
- lblc 局部性最少连接,Locality-Based Least Connections
CentOS 安装:
yum install ipvsadm源码安装:
下载地址: http://www.linuxvirtualserver.org/software/ipvs.html
不同 kernel 版本要下载的版本不一样。查看kernel 版本:
uname -a我这边版本是 2.6.32 所以就下载 1.26 版的:
wget http://www.linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.26.tar.gz tar -zxf ipvsadm-1.26.tar.gz cd ipvsadm-1.26 make报错:
make[1]: *** [libipvs.o] Error 1 make[1]: Leaving directory `/usr/src/ipvsadm-1.26/libipvs' make: *** [libs] Error 2安装完以下这些软件
[root@host2 ipvsadm-1.26]# rpm -qa | grep popt popt-1.13-7.el6.x86_64 popt-devel-1.13-7.el6.x86_64 [root@host2 ipvsadm-1.26]# rpm -qa | grep libnl libnl-1.1-14.el6.x86_64 libnl-devel-1.1-14.el6.x86_64分别用 yum 安装
yum install libnl-devel-1.1-14.el6.x86_64再 make, 又报:
ipvsadm.o: In function `parse_options': /usr/src/ipvsadm-1.26/ipvsadm.c:432: undefined reference to `poptGetContext' /usr/src/ipvsadm-1.26/ipvsadm.c:435: undefined reference to `poptGetNextOpt' /usr/src/ipvsadm-1.26/ipvsadm.c:660: undefined reference to `poptBadOption' /usr/src/ipvsadm-1.26/ipvsadm.c:502: undefined reference to `poptGetNextOpt' /usr/src/ipvsadm-1.26/ipvsadm.c:667: undefined reference to `poptStrerror' /usr/src/ipvsadm-1.26/ipvsadm.c:667: undefined reference to `poptBadOption' /usr/src/ipvsadm-1.26/ipvsadm.c:670: undefined reference to `poptFreeContext' /usr/src/ipvsadm-1.26/ipvsadm.c:677: undefined reference to `poptGetArg' /usr/src/ipvsadm-1.26/ipvsadm.c:678: undefined reference to `poptGetArg' /usr/src/ipvsadm-1.26/ipvsadm.c:679: undefined reference to `poptGetArg' /usr/src/ipvsadm-1.26/ipvsadm.c:690: undefined reference to `poptGetArg' /usr/src/ipvsadm-1.26/ipvsadm.c:693: undefined reference to `poptFreeContext' collect2: ld returned 1 exit status make: *** [ipvsadm] Error 1解决:
wget http://mirror.centos.org/centos/6/os/x86_64/Packages/popt-static-1.13-7.el6.x86_64.rpm rpm -ivh popt-static-1.13-7.el6.x86_64.rpm然后再:
make make install ipvsadm --help如果有对应的帮助信息表示安装成功了
配置 LVS 集群
配置 LVS 集群可以通过 ipvsadm 命令进行
这里写一个 shell 脚本去配置。在代理服务器主服务器上运行脚本 lvs.sh。绑定 VIP,设定 LVS 工作模式.
要注意,这里绑定 IP 是绑定在 eth0 上的,是要对外公开的.
#!/bin/bash SNS_VIP=192.168.2.118 SNS_RIP1=192.168.2.119 SNS_RIP2=192.168.2.35 /etc/rc.d/init.d/functions logger $0 called with $1 case "$1" in start) /sbin/ipvsadm -set 30 5 60 /sbin/ifconfig eth0:0 $SNS_VIP broadcast $SNS_VIP netmask 255.255.255.0 broadcast $SNS_VIP up /sbin/route add -host $SNS_VIP dev eth0:0 /sbin/ipvsadm -A -t $SNS_VIP:80 -s wlc -p 120 /sbin/ipvsadm -a -t $SNS_VIP:80 -r $SNS_RIP1:80 -g -w 1 /sbin/ipvsadm -a -t $SNS_VIP:80 -r $SNS_RIP2:80 -g -w 1 touch /var/lock/subsys/ipvsadm > /dev/null 2>&1 ;; stop) /sbin/ipvsadm -C /sbin/ipvsadm -Z ifconfig eth0:0 down route del $SNS_VIP rm -rf /var/lock/subsys/ipvsadm > /dev/null 2>&1 echo "ipvsadm stopped!" ;; status) if [ ! -e /var/lock/subsys/ipvsadm ] then echo "ipvsadm stopped!" exit 1 else echo "ipvsadm started!" fi ;; *) echo "Usage: $0 {start | stop | status}" exit 1 esac exit 0该脚本会去绑定 VIP到当前网卡 eth0 上,并把请求转发到其它两个IP上。 绑定后,给该脚本加上执行权限:
chmod +x lvs.sh然后执行:
./lvs.sh start运行完后,ifconfig 查看当前IP:
会发现多了一个 eth0:0
注意:当前脚本中是通过:
/sbin/ifconfig eth0:0 $SNS_VIP broadcast $SNS_VIP netmask 255.255.255.0 broadcast $SNS_VIP up去绑定 eth0:0。但根据网络环境不一样,绑定到的位置可能不同。比如我测试的时候发现 ifconfig 的值里面没有 eth0, 有一个 eth3, 这时就要绑定到 eth3:0 上。
同时,netmask 的值也要根据自己网络里的实际值去设置。
真实服务器上运行的脚本: realserver.sh。绑定 VIP, 配置 Non-ARP
要注意,这里绑定 IP 是绑定在 lo 上的,是不对外公开的,只在内部使用。
#!/bin/bash SNS_VIP=192.168.2.118 /etc/rc.d/init.d/functions case "$1" in start) ifconfig lo:0 $SNS_VIP netmask 255.255.255.0 broadcast $SNS_VIP /sbin/route add -host $SNS_VIP dev lo:0 echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce sysctl -p > /dev/null 2>&1 echo "RealServer started!" ;; stop) ifconfig lo:0 down /sbin/route del $LVS_VIP > /dev/null 2>&1 echo "0" > /proc/sys/net/ipv4/conf/lo/arp_ignore echo "0" > /proc/sys/net/ipv4/conf/lo/arp_announce echo "0" > /proc/sys/net/ipv4/conf/all/arp_ignore echo "0" > /proc/sys/net/ipv4/conf/all/arp_announce echo "RealServer stopped!" ;; *) echo "Usage: $0 {start | stop}" exit 1 esac exit 0上面的脚本的功能就是用 ifconfig 来绑定 VIP,并防止 arp 功能。主代理上还进行请求的转发。
LVS + Keepalived 配置
/etc/keepalived/keepalived.conf 内容:
! Configuration File for keepalived global_defs { notification_email { sunyu@easymobi.cn wuxuegang.123@163.com } notification_email_from pub@easymobi.cn smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 # 此处是主 Nginx 的 IP 地址. mcast_src_ip 192.168.2.127 # 该机的 priority(优先) 为 100 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111222 } virtual_ipaddress { 192.168.2.118 } } virtual_server 192.168.2.118{ delay_loop 6 lb_algo wrr lb_kind DR persistence_timeout 60 protocol TCP real_server 192.168.2.119 80{ weight 3 TCP_CHECK{ connection_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } real_server 192.168.2.35 80{ weight 3 TCP_CHECK{ connection_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 80 } } }备机上的配置文件和这个一样,要把 MASTER 改成其它的,如 SLAVER 或 BACKUP, 然后将 priority 设置成小于 100
将这些文件设置成自启动.添加成服务也可以,或直接加到 /etc/rc.local 里:
ulimit -SHn 65535 /usr/local/sbin/realserver start通过观察得知:当客户机 192.168.1.100 发起第一次请求时。LVS 负载均衡器将其分配到后面的真实物理服务器 192.168.1.103(负载均衡机) 上,
完成三次握手(http://blog.sina.com.cn/s/blog_5f54f0be0101c8r9.html) 后,连接状态是 ESTABLISHED, 然后终止TCP连接,
在终止TCL连接后相当长的时间内,192.168.1.100 再次发起新链接,都会一直连接到 192.168.1.107(真实服务器中的一个) 上。
-
-
MySQL 锁
MySQL锁机制
服务器并发时,会用一套锁机制来控制请求,以防数据出现混乱。
锁有两种:读锁和写锁。
读锁也称共享锁,加上该锁时其他人不受影响,都可以读取数据。
写锁加上后其他锁就再不能加上去了,也就是其他人不能再进行读取和变更,所以它又称:排他锁。
写锁比读锁拥有更高的优先级,即使有读操作用户在排队的队列中,一个被申请的写操作仍可排列在队列的前面。写锁会被安置在读锁之前,读锁不能排在写锁前。
但什么时候加锁,锁哪些数据。要有相应的策略,因为加锁解锁也要系统开锁,策略不当会直接影响服务的性能。通常有两种策略:表锁和行锁。行锁较常用。
表锁
开销最小,因为它不用去找出某一行记录然后去给它加锁,而是直接把整个表加上锁标记。当用户对表进行写(插入,删除,更新)时,用户获得一个写锁,它会禁止其它任何用户的读和写操作。只有无人操作时,用户才能获得读锁。读锁和读锁之前不冲突。
行锁
行锁可以最大程度的支持并发,当然开销也更大。行锁只能在 InnoDB 和 Falcon 引擎中被实现。行锁是由引擎自己实现的,不是 MySQL 自身支持的。
多版本并发控制
大多事务型引擎除了用行级锁外,还用一种叫 “多版本并发控制MVCC”Multiversion Concurrency Control 的技术,和行锁关联使用。它不是MySQL 专用的,Oracle, PostSQL 及其它数据库也使用。
它是一种锁的变形,避免很多情况的加锁操作,大大降低系统开销。每种存储引擎实现MVCC的方式不一样。
InnoDB 实现方式
为每个数据行增加两行隐含值,用来记录行的创建时间及过期时间(删除时间,实际上是版本号)。每一行都存储了事件发生时的版本号,用来代替事件发生时的实际时间。开始一个新事务时,版本号自增。每个事务都会保存它在开始时的 “当前系统版本”的记录,而每个查询都会根据事务的版本号,检查每行数据的版本。
实例:
Select 时:
InnoDB 只找版本早于当前事务版本的行。这确保了事务读取的行都是在事务开始前已经存在的,或者由当前事务创建或修改的行。
且数据行的删除版本必须是未定义或者大于事务版本,这保证了事务读取的行在事务开始时是未被删除。
Insert 时: 为每个新增行记录当前系统版本号。
Delete 时: 将当前系统版本号作为行的删除标识。
Update 时: 为要更新的行建立一个拷贝,并在新的拷贝记录当前系统版本号。同时为更新前的旧行记录系统版本号作为删除标识。
保存额外的记录使其它事务的读取不必申请加锁,这使读操作变得更快,因为只需要按当前版本号去取相应的数据即可。但这种方式的缺点是存储引擎必须为每行都存储额外的数据,做更多检查,以及整理。
索引可以让查询锁定更少的行.InnoDB 只有在访问行的时候才会对其加锁,而索引能够减少访问的行数,从而减少锁的数量.
InnoDB 存储引擎在检索到数据并返回给服务器层后,MySQL 服务器才能应用 where 语句,而InnoDB 的行锁机制是引擎实现的,而不是 MySQL 服务器.
所以,在返回所有数据时,这些行就已经锁定了,当 MySQL 服务器过滤掉不需要的数据后,这些行才会被引擎释放锁.
-
MySQL 索引
索引
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
索引能够轻易将查询性能提升几个数量级。
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效。对于中到大型的表,索引就非常有效。但是对于特大型的表,建立和使用索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
索引分类
B+Tree 索引
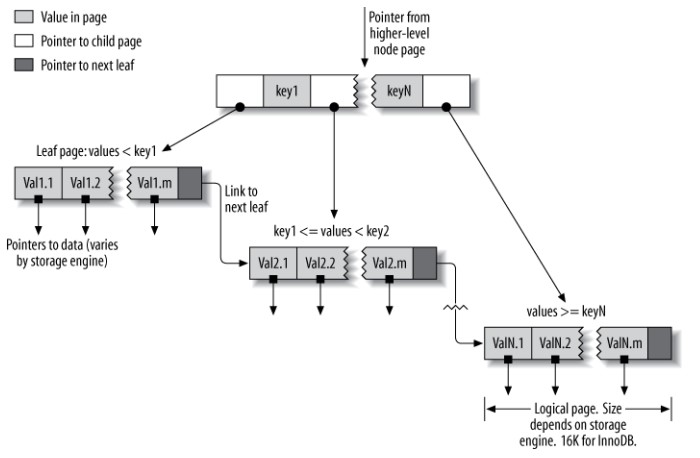
B+Tree 索引是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,因此查找速度快很多。
可以指定多个列作为索引列,多个索引列共同组成键。B+Tree 索引适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。
除了用于查找,还可以用于排序和分组。
如果不是按照索引列的顺序进行查找,则无法使用索引。
为了增加索引的利用率。理想状态是查询条件中每一列都能利用索引。比如前列中是三个列的复合索引。按最左前缀原则,性能最好的查询是:
select last_name, first_name, dob from people where last_name = ‘Cuba’ and first_name = ‘allen’ and dob = ‘1960-01-01’;要注意条件中列的顺序,要和索引中的一致才行。因为索引的存储是按这样的列顺序排好的。如果不按顺序,引擎就会去执行全表查询。
如果查询中有某列是范围查询,则其右边所有列都无法使用索引优化查找了。如:
where last_name = ‘smith’ and first_name likt ‘J%’ and dob=’1960-01-01’;该查询中只会在前两个条件上使用索引。因为 like 是范围查询,按规则,后面的 dob 无法使用索引。
哈希索引
Hash 索引比较的是进行 Hash 运算之后的 Hash 值,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点。
所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
在 MySQL 中只有 Memory 引擎显式支持哈希索引。
InnoDB 引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
限制:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响并不明显;
- 无法用于排序与分组;
- 只支持精确查找,无法用于部分查找和范围查找;
- 如果哈希冲突很多,查找速度会变得很慢。
空间数据索引(R-Tree)
MyISAM 存储引擎支持空间数据索引,可以用于地理数据存储。
空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较索引中的值。
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
索引的优点
-
大大减少了服务器需要扫描的数据量;
-
帮助服务器避免进行排序和创建临时表(B+Tree 索引是有序的,可以用来做 ORDER BY 和 GROUP BY 操作);
-
将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,也就将相邻的数据都存储在一起)。
索引优化
独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;前缀索引
如果有很长的字符,如 blog, text, 如果索引这个列,索引会很大,而且 MySQL 也不支持对这种列进行索引.所以需要前缀索引,对这些索引的前面几个字符进行索引
为了让这种索引效率最高,也就是查询出来的结果最真实,先要确定需要索引前面几个字符.示例:
select count(*) as cnt, city from my_table group by city order by cnt desc limit 10;该语句查询访问量排前十的城市及它的访问量.假定 city 字段是很长的字符串.
然后再用语句:
select count(*) as cnt, left(city, 3) as pref from my_table group by city order by cnt desc limit 10;group by 的内容变成了 left(city, 3) 当然,该语句查询了的结果可能和前面不一样. left 的第二个参数越长,肯定越准确.多试几次,索引选择性最高的数值.
索引选择性
索引的选择性是指不重复的索引列数和数据表的记录总数的比值
索引的选择性越高则查询效率越高.因为它可以让 MySQL 在查找时过滤掉更多的行,唯一索引的选择性是 1, 这是最好的索引选择性,性能也是最好的.
计算方式可能是:
select count(distinct city) / count(*) from my_table;面找出最高选择性的办法:
select count(distinct left(city, 3)) / count(*) as sel3, count(distinct left(city, 4)) / count(*) as sel4 , count(distinct left(city, 5)) / count(*) as sel5 , count(distinct left(city, 6)) / count(*) as sel6 , count(distinct left(city, 7)) / count(*) as sel7 , from my_table结果:
sel3 sel4 sel5 sel6 sel7 0.0239 0.0293 0.0305 0.0309 0.0310看出,从 sel7 开始,上升的幅度已经很少了,如果再往后增成 8, 9 一样.所以,选择 7 即可.有些时候为了效率考虑,可以选择更低的 5, 6
我们就可以创建前缀索引:
alter table my_table add key(left(city,7));前缀索引的缺点是, MySQL 无法使用前缀索引做 order by, group by
多列索引
前面知道,hash 索引是通过列的 hash 值来存的,所以无顺序之言.而 b-tree 是按顺序来存储的.所以最左前缀原则只适用于b-tree 索引
对多列创建复合索引.为了利用索引,SQL语句的写法要注意.
数据存储的方式是按索引列最左进行排,然后再第二..三..在 order by, group by, distinct 等语句都能使用到索引.
将选择性最高的列放在索引最前列.
有时候索引顺序还是得根据实际业务需求来,需要根据查询的频率进行调整.如:
select * from payment where starff_id = 2 and user_id = 584;按最左原则,要创建一个 (starff_id, user_id) 的索引.我们可以先跑一些查询来确定这个表中值的分布情况并确定哪个列的选择性更高:
select sum(starff_id=2), sum(user_id=584) from payment\G结果:
sum(starff_id=2): 7992 sum(user_id=2): 30可见,对于 user_id 这个条件,符合的值更少,所以要将 user_id 放在前面.因为这样能更快的过虑掉更多的结果,更快的找到需要的结果.
可以再计算一下两者的索引选择性, 这样更客观:
select count(distince starff_id)/count(*) as st_sel, count(distince user_id)/count(*) as us_sel, count(*) from payment\G结果:
st_sel: 0.0001 us_sel: 0.0373 count(*): 16049看到这个结果,我们可以坚定的将 user_id 放在最前面了
聚簇索引
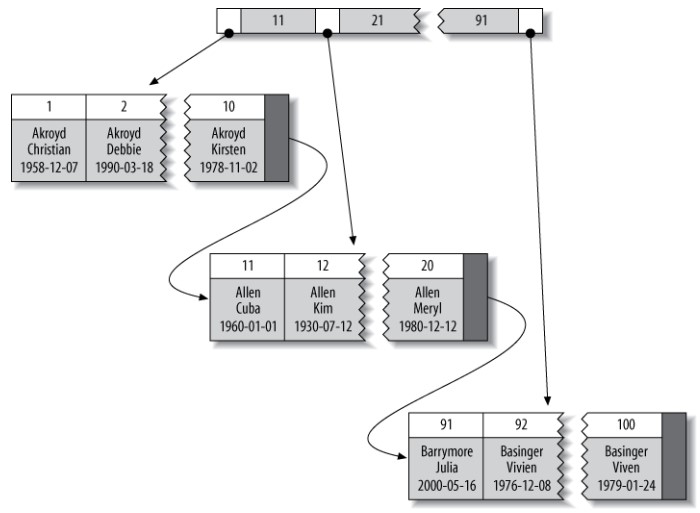
聚簇索引并不是一种索引类型,而是一种数据存储方式。
术语“聚簇”表示数据行和相邻的键值紧密地存储在一起,InnoDB 的聚簇索引在同一个结构中保存了 B+Tree 索引和数据行。
因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
图中,索引列是一个整数列。到目前为止,没有哪个存储引擎完全实现了聚簇索引,只有 InnoDB 实现了通过主键进行聚集,也就是说上图中被索引的列是主键。
如果一个表没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的列,InnoDB 会隐式定义一个主键来作为聚簇索引。
优点
- 可以把相关数据保存在一起,减少 I/O 操作。例如电子邮件表可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据也就能获取某个用户的全部邮件,如果没有使用聚聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
- 数据访问更快。索引和数据都在同一个B-Tree 中。不用再通过指针去查找一次。
缺点
- 聚簇索引最大限度提高了 I/O 密集型应用的性能,但是如果数据全部放在内存,就没必要用聚簇索引。
- 插入速度严重依赖于插入顺序,按主键的顺序插入是最快的。
- 更新操作代价很高,因为每个被更新的行都会移动到新的位置。
- 当插入到某个已满的页中,存储引擎会将该页分裂成两个页面来容纳该行,页分裂会导致表占用更多的磁盘空间。
- 如果行比较稀疏,或者由于页分裂导致数据存储不连续时,聚簇索引可能导致全表扫描速度变慢。
覆盖索引
索引包含所有需要查询的字段的值。
优点
- 因为索引条目通常远小于数据行的大小,所以若只读取索引,能大大减少数据访问量。
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
- 对于 InnoDB 引擎,若二级索引能够覆盖查询,则无需访问聚簇索引。
B-Tree 和 B+Tree 原理
B-Tree
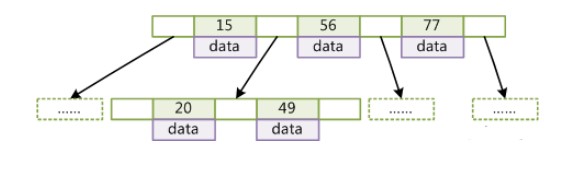
定义一条数据记录为一个二元组 [key, data],B-Tree 是满足下列条件的数据结构:
- 所有叶节点具有相同的深度,也就是说 B-Tree 是平衡的;
- 一个节点中的 key 从左到右非递减排列;
- 如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
在 B-Tree 中按 key 检索数据的算法非常直观:首先在根节点进行二分查找,如果找到则返回对应节点的 data,否则在相应区间的指针指向的节点递归进行查找。
由于插入删除新的数据记录会破坏 B-Tree 的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持 B-Tree 性质。
B+Tree
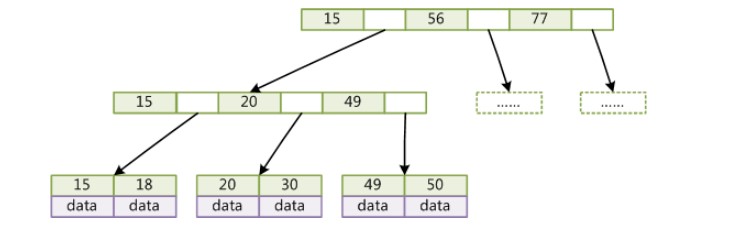
与 B-Tree 相比,B+Tree 有以下不同点:
- 每个节点的指针上限为 2d 而不是 2d+1;
- 内节点不存储 data,只存储 key,叶子节点不存储指针。
带有顺序访问指针的 B+Tree
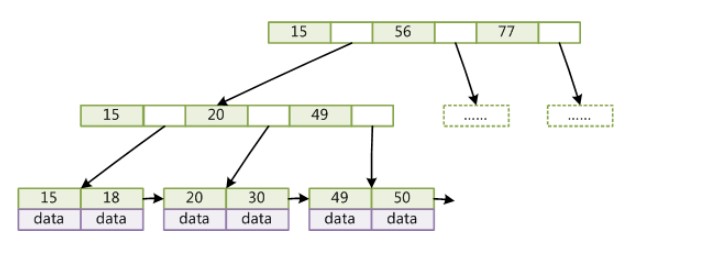
一般在数据库系统或文件系统中使用的 B+Tree 结构都在经典 B+Tree 基础上进行了优化,在叶子节点增加了顺序访问指针,做这个优化的目的是为了提高区间访问的性能。
为什么使用 B+Tree 和 B-Tree
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+Tree B-Tree 作为索引结构,主要有以下两个原因:
(一)更少的检索次数
红黑树和 B+Tree B-Tree 检索数据的时间复杂度等于树高 h,而树高大致为 O(h)=O(logdN),其中 d 为每个节点的出度。
红黑树的出度为 2,而 B+Tree 与 B-Tree 的出度一般都非常大。红黑树的树高 h 很明显比 B+Tree B-Tree 大非常多,因此检索的次数也就更多。
B+Tree 相比于 B-Tree 更适合外存索引,因为 B+Tree 内节点去掉了 data 域,因此可以拥有更大的出度,检索效率会更高。
(二)利用计算机预读特性
为了减少磁盘 I/O,磁盘往往不是严格按需读取,而是每次都会预读。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的旋转时间,因此速度会非常快。
操作系统一般将内存和磁盘分割成固态大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点,并且可以利用预读特性,临近的节点也能够被预先载入。
-
MySQL 存储引擎
MyISAM
系统默认的引擎。在性能和牲间的平衡较好。不支持行级锁和事务。
MyISAM 将表存储为两个文件:数据文件(后缀是 .MYD)和索引文件(后缀是 .MYI),同时还有一个 .frm 文件保存表的定义。它的存储格式是平台通用的,也就是说可以在不同架构的服务器上直接拷贝文件进行数据库的复制。如可以将 Windows 上的文件直接复制到 Linux 上进行数据库备份,还原。
MyISAM 表可以包括动态行(一行数据的长度不固定,如使用 text, blob 类型等)和静态行(每一行的长度固定)。可以在建表时定义。如:
create table mytable (a integer not null primary key, b char(18) not null) max_rows = 1000000000 avg_row_length = 32;在上面的例子中,表的最大行是 1000000000, 平均一行长 32. 也就是说为这个表分配了 1000000000 * 32 = 32G 的容量。MySQL 实际给它分配了多少呢:
show table status like 'mytable' \G *************************** 1. row *************************** Name: mytable Engine: MyISAM Version: 10 Row_format: Fixed Rows: 0 Avg_row_length: 0 Data_length: 0 Max_data_length: 98784247807 Index_length: 1024 Data_free: 0 Auto_increment: NULL Create_time: 2013-06-23 08:00:04 Update_time: 2013-06-23 08:00:04 Check_time: NULL Collation: utf8_general_ci Checksum: NULL Create_options: max_rows = 1000000000 avg_row_length = 32 Comment:可以看出,实际上该表可以使用的空间是 91G。当然,建表后可以通过 Alter table 来改变这些参数,但这将引发整个表和所有相关索引的重写,会非常耗时。
MyISAM 是对整个表进行加锁,读取时,可以获得所有表上的共享锁(读锁),而写入程序获得排它锁(写锁)。
MyISAM 可以支持对表的自动检查和修复。同时还可以手动,使用
check table mytable, 和repair table mytable; 检查表中错误并修复。在离线状态下还可以使用 myisamchk 进行检查和修复(http://blog.sina.com.cn/s/blog_5f54f0be01017ojv.html)MyISAM 可以使用 myisampack 对表数据进行压缩打包。打包后,表里数据只能用来读取,不能修改。除非解压,修改后再重新打包。压缩后的表占用磁盘空间小,查询时磁盘寻道时间大大缩短,查询效率会更高。
InnoDB 引擎
专为事务处理设计的一个引擎。特别用来处理大量简单的,一般不需要回滚的事务。它的性能及崩溃后自动恢复的特性让它很受欢迎。
InnoDB 将所有数据存储在一个或几个数据文件中,不象 MyISAM 一样每个表存储为两个文件。现在的 MySQL 也支持这种形式了。
InnoDB 不能根据排序创建索引,而 MyISAM 支持,因为,InnoDB 在查询和创建索引时要比 MyISAM 慢许多。而且,任何改变 InnoDB 表结构的操作都会导致整个表的重建,以及索引的重建。
InnoDB 使用MVCC机制获取高并发性能。它默认的隔离级别是 repeatable read, 同时它使用 “间隙锁” 策略防止幻读: 不仅对查询中读取的行加锁,还对索引结构中的间隙加锁。
如:
select * from emp where empid > 100 ;这里会对 empid 大于 100 的所有记录加锁,如果记录有 10 条,则会对该 10 条记录加锁。同时,对索引结构加锁,意思就是,如果要往里面插入 empid 大于 100 的值,或者将其它记录的 empid 改成大于 100 也是不允许的。InnoDB 使用聚集索引(B+Tree)。它提供一种非常快速的主键查找性能。不过,它的非主键索引也会包含主键列,所以要把主键定义的小一些。
Blackhole 引擎
该引擎没有任何存储机制,它会丢弃所有的 insert 操作不存储任何数据。不过如果开启了 binlog, 它会记录这些操作。所以,该引擎可以用在集群中的主从复制。
Memory 引擎
如果想获得更高的访问性能,且数据是永不改变的,而且重启后不需要保留。则可以使用内存表。它要比 MyISAM 快一个数量级。但重启后,表结构保留,但数据丢失。通常用来:一些常量表,用来查找或映射。如邮编等。缓存数据分析中的中间结果
Archive引擎
只支持 select 和 insert 操作。它会利用 zlib 对行进行压缩,所以比 MyISAM 有的磁盘 I/O 更少。但每次 select 查询都要进行全表扫描,所以 Archive 表适合日志和数据采集类应用,这类应用做数据分析时往往需要全表扫描。
引擎选择
如果要用到事务, 选 InnoDB 可行。如果只是 select 和 insert ,MyISAM 即可。如果两进行混合,则要选择有行级锁的引擎。
另外,尽量不要在一个库中用多种引擎。这会让备份和性能调整变得复杂。
MyISAM 比 InnoDB 更容易崩溃,而且崩溃后恢复需要的时候更长。所以,有些时候不需要事务,也选择 InnoDB。
MyISAM 支持全文索引。不过也是可以用 InnoDB + Sphinx 实现。
所以,还是直接使用 InnoDB 吧。
日志型应用
如果需要将一个应用的日志,保存到DB中。如 Nginx, Apache 的日志入库。这需要较快的插入速度,这时候可以使用 MyISAM 或 Archive。
如果需要对日志进行分析,而怕对插入造成影响,可以实现主从结构,在主机上插入,在备机上进行查询。或者在库中按年/月进行分表,查询分析的时候可降低对当前要进行插入操作的表进行的查询量。
表引擎转换
Alter table
alter table mytable type = InnoDB;这种方式可以适用任何引擎,但弊端就是执行时间长,MySQL 会按行将数据从原表复制到一张新表中,复制期间可能会消耗系统所有的I/O能力,同时会在原表上加上读锁。
转换表后,将会失去原引擎的一些特性。比如,将 InnoDB 转换成 MyISAM 然后再转换回 InnoDB, 原表上的外键将丢失。
导出和导入
为了更好控制转换过程,可以使用 mysqldump 将数据导出到文件中,然后修改文件中 create table 的存储引擎。
创建与查询
如果数据量不大,可以用如下办法:
create table innotable like myisam_table; alter table innotable engin=InnoDB; insert into innotable select * from myisam_table;如果数据量大,可以分批。一次 insert 一部分。
-
MySQL 基础架构
逻辑架构
MySQL 的整体架构如下:
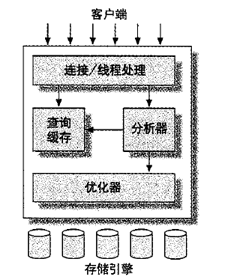
每个客户端连接在服务器进程中都有自己的线程,每个连接所属的查询都会在指定的单独线程中完成。服务器会控制缓存线程,因此不需要每个连接都重建或撤销。
连接时服务器会进行用户名等认证。连接后服务器会先查看查询缓存中是否有现成的结果,如果没有,则会再次进行分析,优化,执行。注意这个顺序,不是先分析语句再查缓存,而是先查缓存,如果没有结果,再去分析语句。
所以,
select * from a where id = 1 and status = 1; 这条语句和select * from a where status = 1 and id = 1两条语句的缓存是不一样的,因为缓存是在语义分析之前执行的。分析器会解析SQL语句,而优化器进行各种优化,如:查询的重写,决定查询的读表顺序,选择相应的索引等。这个过程是自动的,但用户可以通过特殊的关键字给优化器传递各种提示来影响它的决策。
优化器优化时并不知道表是什么引擎,所以它不关心这些。而存储引擎自身也会对查询进行优化。
存储引擎有多种,它们处理数据的方式各不相同。同时,提供给上层使用的功能也不大一样。比如 InnoDB 引擎支持事务,MyISAM 则不支持。
各存储引擎有不同的API用来和上层交互。比如:开始事务,获取某条数据。它不负责SQL语句解析,只是响应请求返回结果。
数据类型
MySQL 支持不同的数据类型。选择正确的类型对性能影响非常大。
在能存储够数据时,用越小的类型性能越好。
尽量用简单的数据类型。如时间存储就用内建的类型,不要用字符串;另外,IP用整数来保存,不要用字符串。
尽量避免 NULL。都定义成 NOT NULL。MySQL 很难优化引用了可空列的查询,它会使索引更复杂。而且可空列需要更多的空间及更特殊的处理。如果必须用,最好用 0 或特殊字符串来代替。
整数
如果存储整数,可用下面几种整数类型:TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT, 它们分别需要 8, 16, 24, 32, 64 位存储空间。它们能存储的数值范围是 -2^(N-1) 到 2^(N-1), N是空间位数。
另外,整数类型还有个可选的 UNSIGNED 属性,它表示不可为负,并大致把正数的上限提高一倍。如 TINYINT UNSIGNED 的范围变成 0-255, 而不是 -127-128 MySQL 可以对整型定义宽度,如:INT(11), 但它的存储和计算,占的空间和 INT(1), INT(20) 是一样的。只不过它规定了MySQL 的客户端工具用来显示字符的个数。
实数
实数有分数部分。可以使用 DECIMAL 保存比 BIGINT 还大的整数。同时支持精确与非精确的类型。
Float 和 Double 支持近似计算,是不精确的。
DECIMAL 类型用于保存精确的小数。服务器自身对 DECIMAL 进行运算,因为CPU不支持对它进行直接运算。而浮点数则可以在CPU中运算所以会更快一些。通常只有需要对小数进行精确计算的时候才使用 DECIMAL, 如金融数据。
varchar
可变长度,使用最为广泛。它比固定长度类型占用更少的存储空间。比如声明为 varchar(20),了但如果字段长度只有 2, 它也就只占 2 个位置。不会占到 20。
char
不管内容有多长。总是占用固定长度的空间。容易造成浪费。存储长度相似的字条串时好用。如MD5加密后的用户密码。另外,由于长度固定了,当字段频繁被更新时,也不会产生碎片。而且 char 效率要好于 varchar。
BLOB 和 TEXT
用二进制和字符形式来保存大量数据。它们的区别是一个是二进制形式,没有字符集和排序规则,TEXT有字符集和排序规则。
MySQL 对 TEXT 的排序和其它方式不同,它不会按照字符串完整长度进行排序,而只是按照
max_sort_length规定的前若干个字节进行排序。若想只按前几个字节排序,可以减少该参数的值,或者使用:order by substring(column, length)ENUM
ENUM 列可以存储 65535 个不同的字符串。而且 MySQL 以非常紧凑的方式保存它们,根据表中值的数量,MySQL 甚至会把它们压缩到 1-2 个字节中。
MySQL 在内部把它们保存为整数,表示值在列表中的位置,并且保存一份查找表来表示整数和字符的映射关系。另外,ENUM 列排序是按数字顺序排的,不是按字符串。
同上,在使用时,服务器会额外进行一次数值和字符的关联才能找到,所以会有额外的开销。特别是在某些连接查询中,具体取舍就要看性能和占用空间两个的具体值了。
日期和时间
MySQL 有多种类型来保存日期和时间。如:YEAR, DATE。
MySQL 能存储的最小粒度是秒。MySQL 还有两种数据类型:DATETIME, TIMESTAMP。
DATETIME
该类型能保存大范围的值:1001 到 9999 年。精度为妙。它把日期和时间保存到格式为YYYYMMDDHHMMSS的整数中。与时区无关,它使用8 个字节来保存。
TIMESTAMP
它存储的是自 1970.1.1 午夜以来的秒数。它只使用 4 字节来保存。因此范围要小,只能保存 1970 到 2038 年。MySQL 提供 FROM_UNIXTIME() 把 Unix 时间戳转换为日期,也能通过 UNIX_TIMESTAMP() 将日期转换成时间戳。
TIMESTAMP 的值的显示依赖于时区。而该值为 0 时的值实际显示为美国东部时间 1969-12-31 19:00:00 与格林尼治标准时间GMT相差5小时。
由于 MySQL 的时期和时间都只能精确到秒。如果需要更精确,可以使用 BIGINT或者使用DOUBLE的小数来保存秒的分数部分。
特殊类型
IP 地址,通常保存是用 varchar(15) 来保存,但实际上,IP地址是一个 32 位的整数。而不是字符串。MySQL 提供
INET_ATON()和INET_NTOA()在 IP 和 整数之间互换。
-
MySQL 事务
事务隔离级别
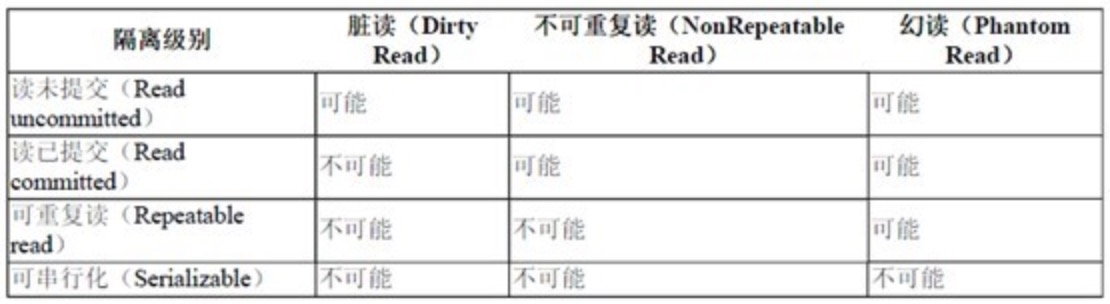
SQL的标准定义里面,一共有四种级别:
- read uncommited 读取未提交的数据。就是其他事务已经修改但还未commit的。这种情况叫:脏读。
- read commited 读取已提交的数据。query2会跟query1读取的数据不一样。这种情况叫 “不可重复读”
- repeatable read 可重复读取。它确保同一事务中多次读取某条数据时读取的数据一样。也就是说读取的都是已经提交的数据。但会出现幻读:当用户读取某一范围内的行时,另一事务在该范围内插入或删除了新行。用户再次读取该范围行时结果和之前的结果一样,但真实的数据已经被别人修改,他读取到的结果其实已经不存在或已变更。即幻影行。 这是 MySQL 默认的隔离级别。
- serializable 序列化。强制对各事务进行排序,使之不能互相冲突,从而解决幻读。但会出现排队,超时,实际中很少用。
SQL 标准用三个必须在并行的事务之间避免的现象定义了四个级别的事务隔离。
这些不希望发生的现象是:
-
脏读(dirty reads):一个事务读取了被另一个事务改写但还没提交的数据.
-
不可重复读(non-repeatable reads):一个事务重新读取前面读取过的数据, 发现该数据已经被另一个已提交的事务修改过(一个事务执行相同的查询两次或两次以上,但每次查询结果都不同时。这由于另一个并发事务在两次查询之间更新(update)了数据).
-
幻读(phantom read):在两次查询同一时间点数据时,发现数据数量发生改变。(当一个事务读取几行记录后,另一个并发事务插入(insert,delete)一些记录)
不同隔离级别出现上面几种现象的可能性是:
死锁
两个或多个事务在同一资源上互相占用,并请求加锁时,导致恶性循环,如: 事务一:
start transaction; update table set column1 = 1 where id = 4; update table set column1 = 2 where id = 3; commit;事务二:
start transaction; update table set column1 = 3 where id = 3; update table set column1 = 4 where id = 4; commit;两个事务执行第一条语句时都没问题,而且分别取得了两行的写锁。但是执行第二条语句时都不会成功,因为锁都被对方占用了。事务就会不停的等待对方释放资源。进而进入死循环。
为了解决这种问题,数据库系统实现了各种死锁检测及死锁超时机制。InnoDB 引擎则可以预知这种循环的相关性,并立刻返回错误,并回滚拥有最少排他锁的一个事务(因为这个事务最容易回滚)。
事务日志
通常,我们更新数据的过程是:执行SQL语句,数据库更新磁盘中表的数据。而事务则不这样处理,存储引擎可以先更新数据在内存中的拷贝,这非常快。然后存储引擎将数据改变写入事务日志中,日志在磁盘上。这样就让数据有了持久性,这个过程也相对较快(相对于更新表数据)。最后,存储引擎才会在某个时间更新到磁盘表中。
如果数据更新已经写入日志,但还没来得及写入表中,但这时候系统崩溃,存储引擎会在重启后自动去恢复事务日志中的数据。当然,这个功能也是引擎自己的功能,不是 MySQL 自身的功能。
混合引擎的事务
由于事务的功能不是 MySQL 自身提供的,而是引擎提供的。
所以,如果事务中的多个表,有的是 MyISAM, 有的是 InnoDB,那就要格外小心了。因为 InnoDB 可以通过 rollback 回滚,但 MyISAM 是 autocommit 的,数据自动提交且无法回滚。
如果事务处理一切顺利,那没问题。如果有问题,错误就无法挽回了,所以如果要用事务,就尽量全部涉及的表都用事务型引擎吧。
-
MySQL 主从复制
主/从复制。一台主库同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。该功能是通过 binlogs 实现的。复制有两种方式:基于语句的复制和基于行的复制。
Binlogs
二进制日志. 来记载让数据变更的日志。只有让数据有变化的语句日志才会被记录下来。
在MySQL 各库的目录下会有许多类似 mysql-bin.000001 这种文件.当然,这个是可以在 MySQL 配置文件 my.cnf 中配置的 (log-bin 和 log-bin-index).
另外,还有一个 binlog 索引文件。默认是 mysql-bin.index 用来追踪已有的 binlog 文件。以便服务器能在必要的时候创建正确的新的 binlog 文件。文件文件每一行都包括一个 binlog 文件的完整名称。
正常情况下,当数据库启动时会建一个新的 binlog 文件,也可以在命令中强行让数据库使用新的 binlog. 命令是:
mysql> flush logs;binlog 每个文件有大小限制,当达到后就会新建一个新的使用。
由于 binlog 是所有库公用的,所以会出现多个库要写入内容的情况。为避免冲突,服务器会给它建一个互斥锁。这个锁可能会阻塞某些线程。
binlog 中记录的日志顺序可能和实际语句的执行顺序不一样。这样带来的问题就是,由于 binlog 中记录的是SQL语句,而日志顺序和实际执行顺序不一样,就会导致 master 和 slave 上面数据不一致。因为顺序不一样,更新的行可能也不一样。
MySQL 除了有上面说的这种基于让数据变更的SQL语句的复制。还提供基于行的复制,它就是将变更的行保存起来。两种方式各有补充。如果一条语句改动大量的行,肯定是直接记录语句更实用。如果有多个表连接的复杂更新,直接记行更简单。
show binlog events;可以看到日志中有哪些事件。默认它会看第一个日志文件中的事件。如果要查看指定文件的内容,如下:
mysql> show binlog events in 'mysql-bin.000005'\G *************************** 956. row *************************** Log_name: master-bin.000001 Pos: 147470 Event_type: Xid Server_id: 1 End_log_pos: 147497 Info: COMMIT /* xid=4568 */ *************************** 957. row *************************** Log_name: master-bin.000001 Pos: 147497 Event_type: Rotate Server_id: 1 End_log_pos: 147541 Info: master-bin.000002;pos=4所以,可以看当前正在使用的是哪个日志文件,然后看该文件中的内容
mysql> show master status; +-------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +-------------------+----------+--------------+------------------+ | master-bin.000005 | 40862252 | payment | test,mysql | +-------------------+----------+--------------+------------------+查看当前主服务器的状态,该状态中 File 就是当前正在使用的文件。
关键点
binlog 到达 slave 后,将日志中的语句再执行一遍。这个时候 slave 有几个是一定要明确的:
-
当前数据库 如果语句中引用了表,函数,或存储过程,但没有指定是哪个数据库,则默认是使用当前数据库的。为解决该问题,记录日志时会多记一个字段,表示是哪个库。
-
rand 函数的种子 random 是基于伪随机数的函数,生成一系列可再生的数字。看上去是随机的,但实际上是均匀分布的。如果种子相同,rand 函数生成的值是一样的。 如果用到了该函数,binlog 会把种子记下。
-
当前时间.now() 如果master 和 slave 上执行有延迟,该函数的结果就不一样了。 now() 是返回语句开始执行时的时间。为了保证主从返回的时间一样,binlog 会记下每个事件的时间戳表明事件是何时开始执行的。
- auto_increment 的值 这个值是和上一条语句有关。 如果有用到这个的,binlog 会记下这个值。
- last_insert_id 的值 同样,这个值也取决于上条记录。 如果用到这个,binlog 会记下这个值。
- 线程 ID 如果SQL中使用了临时表或者调用了 CURRENT_ID 函数。该值可能不一样。
影响数据的SQL语句(DML):
delete, insert, update肯定会被记入 binlog 中。为了保证安全的记录日志,MySQL 在获取事务级锁时写 binlog.然后在日志写操作完成后释放锁。表未释放锁之前,在语句提交的同时将语句写入binlog。这样保证 binlog 始终与语句的更新一致。过程如下:解析到DML –> 获得锁 –> 提交语句到引擎 & 写入 binlog –> 释放锁
影响数据库结构的SQL语句(DDL): create table, alter table 会改变数据库的结构。而我们的数据库结构是定义在库所在目录下的后缀名为 .frm 的文件中。
为了保护这些内部数据结构的更新,在修改表结构的语句执行前,要先获得锁。 而这些行为都会影响性能的。
基于语句复制
Binlogs 中记录了改变数据的SQL语句。从库将该语句重新执行一遍。而且实现起来比较简单。 缺点:一些元数据,如:rand(), now(), 等要经过特殊处理。
基于行复制
把数据更改记在 log中。明显的缺点就是日志会非常大。
MySQL 5.1 后会自动使用上面的两种方式,智能切换。默认使用基于命令复制,当检测到事件不能简单的用命令复制解决时,就采用基于行复制。也可以人为的在 my.cnf 中通过 binlog_format 变量来控制。
配置方法
配置的过程如下,找了两台局域网机器, 192.168.3.119(master) 和 192.168.3.24(slave)
master:
vi /etc/my.cnf添加:
log-bin = master.bin log-bin-index = master-bin.index server-id = 1 #希望同步的数据库.有多个就写多行 binlog-do-db=payment binlog-do-db=datacenter #不希望同步的数据库.有多个就写多行 binlog-ignore-db=test binlog-ignore-db=mysql重启后再创建一个用来同步的单独用户
mysql> create user repl_user; Query OK, 0 rows affected (0.00 sec) mysql> grant replication slave on *.* to repl_user identified by 'root'; Query OK, 0 rows affected (0.00 sec)slaver:
vi /etc/my.cnf添加:
server-id = 2 relay-log-index = slave-relay-bin.index relay-log = slave-relay-bin #不希望同步的数据库 replicate-ignore-db=mysql #希望同步的数据库 replicate-do-db=payment附:可以通过该参数进行分片,即:将不同的功能放到不同的 slave 组中.
重启并在 slave 上配置:
mysql> change master to master_host = '192.168.3.119',master_port = 3306,master_user = 'repl_user',master_password='root'; Query OK, 0 rows affected (0.01 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)在主库上建库,表,插入数据。看从库变化。 如果没有,在从库上用:
show slave status;查看从库状态,里面可能有报错信息。要注意的是,MySQL 安装后,可能自身的 my.cnf 就有 binlog 相关的配置,如 server-id 在进行上面的配置时要注意看一下,自己的配置会不会被默认配置给覆盖,也就是我们的配置写在上面,但后面有系统自己的配置。
在
slave status的状态中,有两项:Slave_IO_Running和Slave_SQL_Running, 必须都为 Yes 才说明正常运行了。如果是slave_io_running no了,那么就我个人看有三种情况,一个是网络有问题,连接不上,第二个是有可能my.cnf有问题。
一旦io为no了先看err日志,看看有什么错,很可能是网络,也有可能是包太大收不了,这个时候从机上改max_allowed_packet这个参数。
Slave_SQL_Running 为 No 时:
解决办法一
- 程序可能在slave上进行了写操作
- 也可能是slave机器重起后,事务回滚造成的.
一般是事务回滚造成的。解决办法:
mysql> slave stop; mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1; mysql> slave start;解决办法二
首先停掉Slave服务:
slave stop到主服务器上查看主机状态,记录File和Position对应的值mysql> show master status; +----------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +----------------------+----------+--------------+------------------+ | master-bin.000005 | 194244 | payment | test,mysql | +----------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)然后到slave服务器上执行手动同步:
change master to master_host = '192.168.3.119',master_port = 3306,master_user = 'repl_user',master_password='root',master_log_file='master-bin.000005',master_log_pos=194244;工作原理
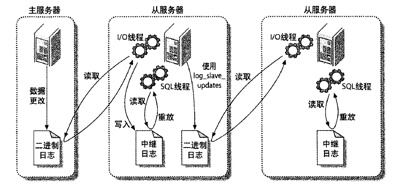
主-分发-从库
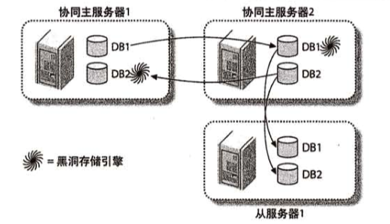
一台主库,然后一台从库,该从库使用 blackwhole 引擎,只用来记录 binlogs, 不保存数据。这时候它叫分发库,然后其它从库把分发库当主库实现同步。
多主库复制
MySQL 不支持一个从库有多个主库。而且,如果有两个主库,都对外提供写功能,两个的数据同步会有问题。这时候想到的办法是:两个都为主库,但每个库对外提供写的功能不一样。这样就不冲突了。
两个主库都有自己的独有数据,然后通过 blackwhole 引擎去同步对方的独有数据。
并行复制
在数据量较大并发量较大的场景下,主从可能会有延时。因为从库使用 单线程 重放relaylog。为了优化这种情况,MySQl 进行了优化。提供了基于多线程的并行复制。
mysql5.6 提供了 按照库并行复制, 而 mysql5.7 提供 按照GTID并行复制。
按库并行复制
主库的操作都记录在 binlogs 里。从库读取里面的内容然后在自身实例上重放。如果要多线程,肯定要把各个 log 分配到不同的线程去执行。那么,按照什么参数进行分配呢?
随机分配肯定不行。比如有这样三条记录:
update user set money=100 where uid=1; update user set money=150 where uid=1; update user set money=200 where uid=1;如果随机分配,用户的余额值可能就乱了。最后的值与主库不一致。于是就有这样的思路:按库进行分配。不同的库分配到不同的线程。这就要求我们把数据切分到不同的库里,如果还是常规的单库多表,就无法利用这种策略。
当然,对于事务,mysql 会自动把事务里各个操作分为一组,进行编号。保证在从库上也是串行执行。
另外,使用多库多表后,业务分离,结构清晰。扩展方便。
按GTID的并行复制
新版的mysql,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=1 20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=2 20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=3 20160607 23:22 server_id 1 XXX GTID last_committed=0 sequence_numer=4和原来的日志相比,多了
last_committed和sequence_number。last_committed 表示事务提交时,上次事务提交的编号,如果具备相同的 last_committed,说明它们在一个组内,可以并发回放执行。
所以 ,升级mysql吧, 并且使用“多库”架构吧!
多库多事务
我们经常使用事务来保证数据库层面数据的ACID特性。如: 对余额表,订单表,流水表的SQL操作全部成功,则全部提交,如果任何一个出现问题,则全部回滚,以保证数据的一致性。如果进行了拆库,余额、订单、流水可能分布在不同的数据库上,甚至不同的数据库实例上,此时就不能用事务来保证数据的一致性了。
主从一致性
在主从结构中,主库的 binlog 在从库上重放。但 binlog在传输上是需要时间的。特别是在一主从多的时候,容易产生延迟。如果在延迟期间产生新请求,就会出现读取到的不是新数据。
为解决这种情况,会有几种方案:
半同步复制
原理是:等主从同步完成之后,主库上的写请求再返回。实际上,数据库本身就支持这种机制。在配置主从复制的时候可以选择用哪种模式:异步、同步、半同步。
半同步带来的缺点是:主库的写请求时延会增长,吞吐量会降低。
强制读主库
可以将读和写都落到主库上。显然不符合要求。需要我们对读性能进行额外的优化。
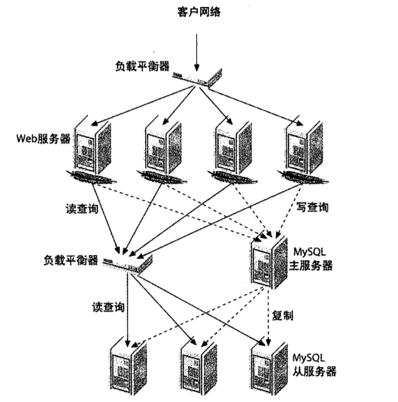
数据库中间件
所有的读写都走数据库中间件。通常情况下,写请求路由到主库,读请求路由到从库。相当于在数据库上加了一层代理或者连接池,我们自己控制转发的逻辑。
在中间件中,记录所有路由到写库的 key,在主从同步时间窗口内(假设是500ms),如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个key上的读请求路由到主库。主从同步时间过完后,对应key的读请求继续路由到从库。
但这种方式需要自己处理中间件逻辑。要复杂一些。
缓存记录写key法
由于中间件逻辑相对复杂。于是想到用缓存:
- 将某个库上的某个key要发生写操作,记录在cache里,并设置 “主从同步时间” 的cache超时时间,例如500ms。
- 修改数据库
请求发生时的过程:
- 先到cache里查看,对应库的对应key有没有相关数据
- 如果cache hit,有相关数据,说明这个key上刚发生过写操作,此时需要将请求路由到主库读最新的数据
- 如果cache miss,说明这个key上近期没有发生过写操作,此时将请求路由到从库,继续读写分离
扩展
向上扩展 — 也称垂直扩展,意味着购买更多性能好的硬件。见效快,但终究会有顶,而且成本也是要计算的一方面。
向外扩展
也称水平扩展。最简单的是通过复制,将数据放在多台服务器上,读写分离。复制点的就要利用到集群。
常见的如用户数据、用户发帖的切分。通常它们都会有一个自增的主键。可以根据这个主键去进行分配。觉的有:范围法 和 哈希法。
范围切分
以主键范围为基准进行切分。如:
- user-db1:存储0到1千万的uid数据
- user-db2:存储1到2千万的uid数据
范围切分的优点是:
- 切分策略简单,根据uid,按照范围,user- center很快能够定位到数据在哪个库上
- 扩容简单,如果容量不够,只要增加user-db3即可
范围法的不足是:
- uid必须要满足递增的特性
- 数据量不均,新增的user-db3,在初期的数据会比较少
- 请求量不均,一般来说,新注册的用户活跃度会比较高,故user-db2往往会比user-db1负载要高,导致服务器利用率不平衡
哈希切分
由于范围切分有诸多问题。于是就提出了哈希这种分布要平均一些的办法。将 uid 取哈希,然后再根据得到的值和数据库实例个数取模,得到的值存储到对应的实例上。
哈希法的优点是:
- 切分策略简单,根据uid,按照hash,user-center很快能够定位到数据在哪个库上
- 数据量均衡,只要uid是均匀的,数据在各个库上的分布一定是均衡的
- 请求量均衡,只要uid是均匀的,负载在各个库上的分布一定是均衡的
哈希法的不足是:
- 扩容麻烦,如果容量不够,要增加一个库,重新hash可能会导致数据迁移,如何平滑的进行数据迁移,是一个需要解决的问题
使用uid来进行哈希切分之后,对于uid属性上的查询可以直接路由到库,假设访问uid=124的数据,取模后能够直接定位db-user1:124%3 = 1。
对于非uid属性的查询,例如login_name的查询,就没办法了。解决思路是创建一个 login_name 和 uid 的索引表。先通过 login_name 查询到 uid,然后再通过 uid 去查。或者再进一步,把这个对应关系方向到 redis, memcached 等中。
哈希切分的扩容问题解决起来比较复杂。大致是分三步:冗余、扩容、收缩。
冗余是指:将现有的实例进行冗余部署。比如当前有 2 个实例db0, db1 提供服务,那么就再添加两个 db2, db3。分别为当前实例的从机。数据和主机上完全一致。db2–>db0, db3–>db1。
扩容是指:将请求从原来的 2 个实例变成现在的 4 个实例。比如之前到 db1 的,现在通过哈希算法转到了 1, 3;之前到 db0 的现在转到了 0, 2。这样就实现了扩容。而且新的数据也会被存到正确的实例上。
收缩是指:由于新增加的实例是通过冗余的方式部署的,所以db0, db1 上实际上有些数据不会被访问到,它是在 db2, db3 上的。同理,db2, db3 上也有一些数据是不需要的。这时就需要脚本去处理,清理掉。
按功能拆分
将那些将来会增长得非常庞大的数据分开来存,如用户的文章,评论,分开来存。这里看来和功能拆分相似,但它比按功能更细。但它要求的是一开始规划的时候就分好,要不然后期再来分片,就复杂了。
向内扩展
对不再需要的数据进行归档和清理。将活跃数据和非活跃数据分开处理。
数据分片
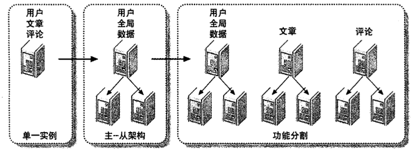
将数据按功能切分到不同的库后。同一张表也可以再进行切分。比如用户表,可以将基础数据放在一个表,将扩展信息放到另外的表。通常原则是:
- 将长度较短,访问频率较高的属性尽量放在一个表里,这个表暂且称为主表
- 将字段较长,访问频率较低的属性尽量放在一个表里,这个表暂且称为扩展表
- 经常一起访问的属性,也可以放在一个表里
数据量并发量比较大时,大表之间的查询通常不建议用 join, 而是通过多次查询。因为 join 更慢,而且 join 就意味着基础数据和扩展数据必须部署在一起,不利于扩展和拆分。
这样拆分还有一个好处是,可以充分利用数据库缓存。
因为数据库缓存是以行为单位存储的。在有限内存的情况下,一行内容越少,缓存的内容越多。这样越容易命中,以降低数据库查询。
假设数据库缓存为1G,未拆分的user表1行数据大小为1k,那么只能缓存100w行数据。
如果垂直拆分成user_base和user_ext,其中:
- user_base访问频率高(例如uid, name, passwd, 以及一些flag等),一行大小为0.1k
- user_ext访问频率低(例如签名, 个人介绍等),一行大小为0.9k
那边内存buffer就就能缓存近乎1000w 行user_base的记录,访问磁盘的概率会大大降低,数据库访问的时延会大大降低,吞吐量会大大增加。
负载均衡
-
-
TCP三次握手/四次挥手
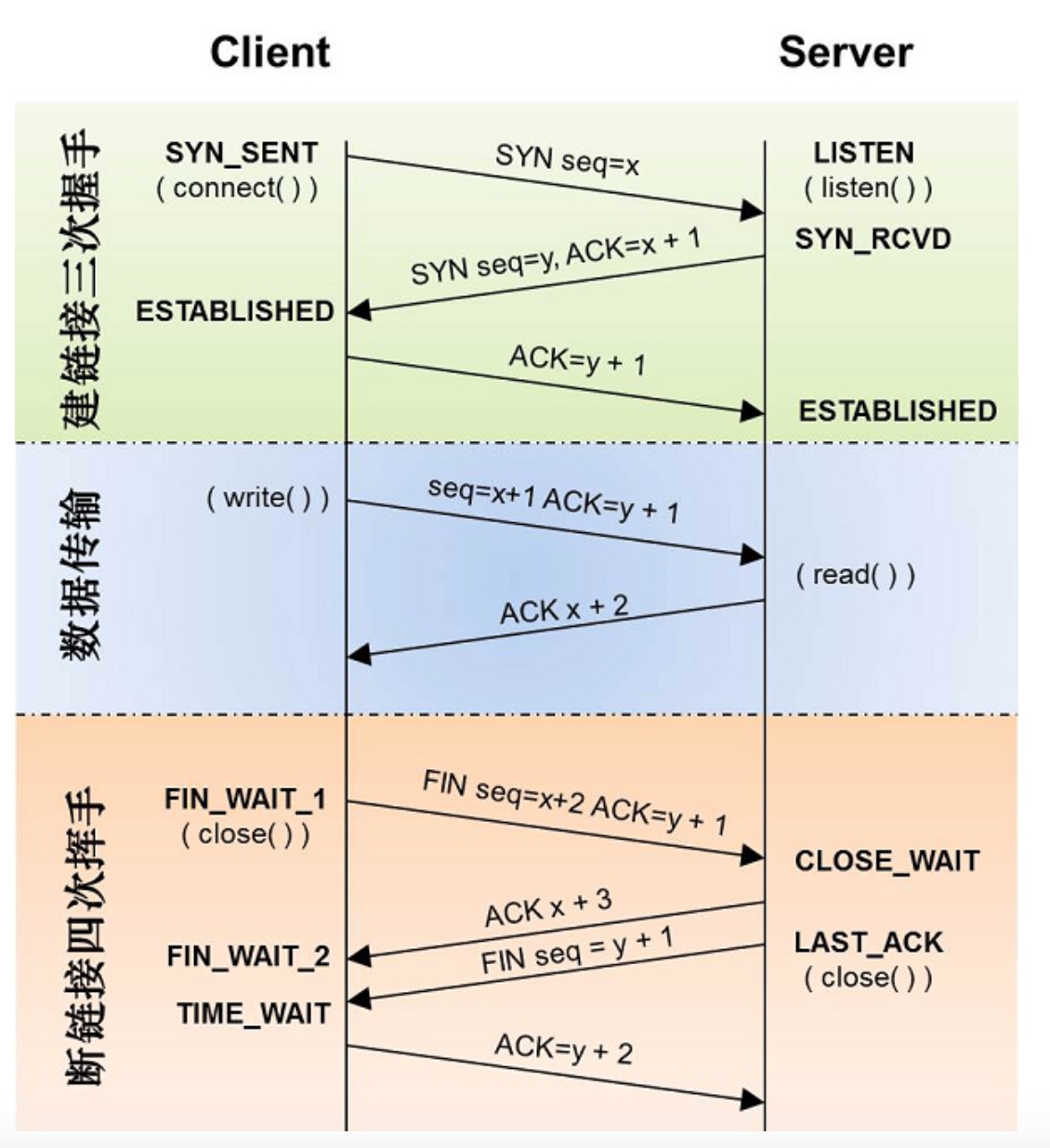
三次握手
所谓三次握手,是指建立一个TCP连接时需要客户端和服务器总共发送三个包
三次握手的目的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号并交换TCP窗口大小信息。步骤如下:
- 报文一:客户端发送一个SYN标志位置1的报文到服务器。指明客户打算连接的服务器的端口,以及初始化序号,保存在包头的序列号字段里。
- 报文二:客户端回应客户端,返回一个SYN标志位和ACK标志均为1的报文,表示对刚才这个 SYN 报文的回应,同时将 SYN 给客户端,询问客户端是否准备好进行通信。
- 报文三:客户端再次回应服务端一个 ACK 报文。SYN标识为0,ACK标识为1。
报文: 网络中交换与传输的数据单元。它包含要发送的完整数据信息,传输过程中会不断地封装成分组,包,帧来传输。封装的方式就是添加一些信息段,报头。
一段消息从 A 传到 B,要经过很多个路由器。任意两个路由器之间的传递,它们的报头都是不一样的,都需要对内容进行重新封装。
四次挥手
TCP的连接的断开需要发送四个包,因此称为四次挥手。客户端或服务器均可主动发起挥手动作。
由于 TCP 连接是全双工的,因为每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务时,就发送一个 FIN 来终止这个方向的连接。收到一个 FIN 只意味着这一方向上没有数据流动了,一个 TCP 连接在收到一个 FIN 后仍能发送数据。首先关闭的一方将执行主动关闭,而另一方执行被动关闭。
过程如下:
- 报文四:客户端发送一个 FIN, 用来关闭客户到服务器的数据发送。
- 报文五:服务器收到 FIN, 回发一个 ACK, 确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
- 报文六:服务器关闭客户端的连接,发送一个FIN给客户端。
- 报文七:客户端回ACK报文确认,并将确认序号设置为收到序号加1。
为什么是三次握手四次挥手
这是因为服务端的LISTEN状态下的socket当收到SKY报文的简历连接的请求后,它可以把ACK和SYN放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,他仅仅表示对方没有数据发送给你了,但未必你的所有数据都全部发送给对方了,所以你可能不是马上会关闭socket,即你可能还会发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以这里的ACK和FIN报文多情况下都是分开发送的。
2MSL
MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
IP 头中有一个TTL域,TTL是time to live的缩写,中文可以译为“生存时间”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个IP数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减1,当此值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。
当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,并停留 2MSL(Max Segment LifeTime)。
这样的目的是:
双方都同意关闭连接,而且挥手的 4 个报文也都协调和发送完毕,按理可以到 CLOSED 状态。但网络不一定可靠。无法保证最后一次发送的 ACK 真实的被对方收到,而是单纯的发出了。比如对方处于 LAST_ACK 状态下的 SOCKET 可能会因为超时未收到 ACK 报文而重发 FIN。TIME_WAIT 就是用来等这个超时重发的。
如果服务器中 TIME_WAIT 过多,服务器会被拖死。我们可以通过修改内核参数减少该参数的数量:
[root@localhost ~]# vi /etc/sysctl.conf在最后加上:
net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_recycle=1 net.ipv4.ip_local_port_range=1024 65000让变更生效:
[root@localhost ~]# /sbin/sysctl -p各种连接状态
服务器中查看连接状态命令:
[root@ttt ~]# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' LAST_ACK 9 SYN_RECV 11 ESTABLISHED 74 FIN_WAIT1 14 FIN_WAIT2 11 TIME_WAIT 315各状态的含义:
CLOSED: 还未建立连接或已经断开
LISTEN: 服务器正在监听,可以接受连接
SYN_RECV: 一个连接请求已经到达,等待确认.接收到 SYN 报文,要返回 SYN 和 ACK ,然后会进入 ESTABLISHED 状态。
SYN_SEND: 客户端 SOCKET 执行连接时,发送SYN,然后进入 SYN_SEND.表示客户端已经发送了 SYN.这个状态会很短,因为服务端接收到 SYN 后马上会返回 SYN 和 ACK,然后就进入ESTABLISHED 了。
ESTABLISHED: 正常数据传输
FIN_WAIT1: 当连接处在 ESTABLISHED 时,客户想主动关闭连接,就会向对方发送 FIN.然后进入 FIN_WAIT1.对方收到 FIN 后会回应 ACK,然后进入 FIN_WAIT2。所以FIN_WAIT1很难碰到,就象上面的 SYN_RECV 和 SYN_SEND 一样。
FIN_WAIT2: 另一边已同意释放连接
CLOSING: 两边同时尝试关闭连接。该情况很特殊,正常情况是:你发送 FIN, 然后收到对方的 ACK, 然后再收到对方的 FIN. 但对方的 FIN 却在 ACK 前到了。
TIME_WAIT: 收到对方的 FIN 报文,且已经发送 ACK.就等 2MSL 后即可回到 CLOSED 可用状态。
LAST_ACK: 被动关闭的一方在发送 FIN 后,等待对方的 ACK.什么时候接收到 ACK, 什么时候进入 CLOSED 状态。
-
Memcached
Memcached
Memcached 是一款被广泛利用的缓存服务。它不提供持久化,只是将数据存于内存中。用来减少数据层的访问,提升效率。
启动参数
memcached 的安装不再叙述。安装完后,它的启动可以有一些自定义的参数:
参数 说明 -p 使用的TCP端口。默认为 11211 -m 为整个服务分配的内存大小。默认是 64M -vv 用 very vrebose 模式启动,调试信息和错误输出到控制台 -d 作为 daemon 在后台运行 -M 禁用 LRU -f 设置 slab 的步长。默认是1.25 存储原理
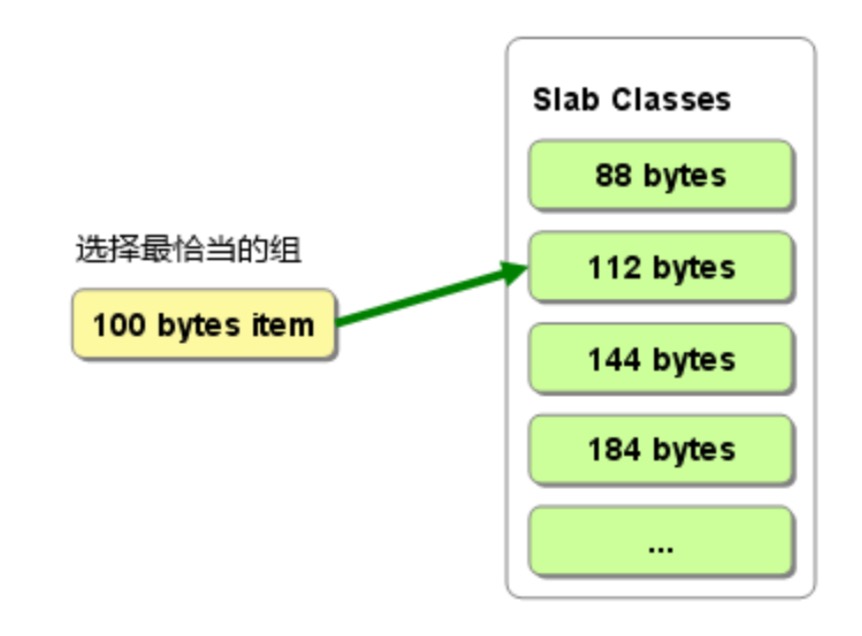
memcached 采用 Slab Allocator 机制分配、管理内存: 按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把相同尺寸的 chunk 分成组。

默认情况下,一个 Slab 分配 1M 的空间。然后这 1M 会被切割成不同大小的 chunk。所以说,memcached 里一个 key 最多能存储的内容就是 1M。注意,memcached存储时会有压缩机制,而且压缩比例非常高,但对于小内容,压缩反而影响性能,需要设置memcached按内容大小自动压缩,比如小于 2k 的不压缩.如:
$mem->setCompressThreshold(2000,0.2); // 当数据大于2k时,以0.2的压缩比进行zlibchunk 的划分是有规律的。我们通过启动参数的 -f 可以控制切割的步长。默认值是 1.25,也就是说最大的 chunk 是 1M,第二大的是 1M/1.25,依此类推。
由于预告将内在分割成了不同大小的组。当有数据存储时,它会选择和存储大小最接近的 chunk 组,并在其中的空闲 chunk 里存放。
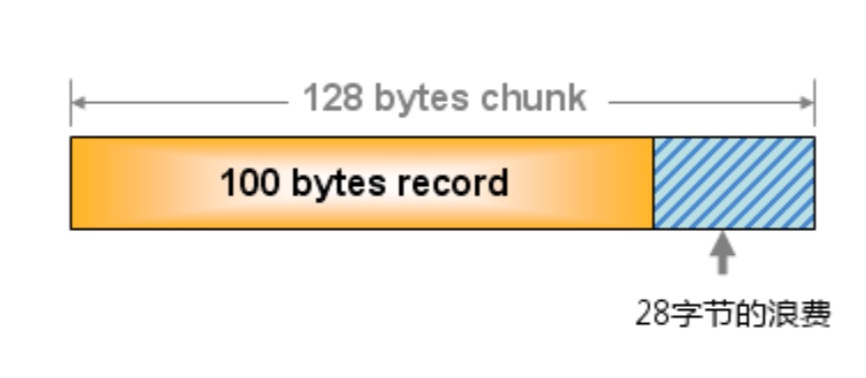
但这样就会造成一定的浪费。比如有需要存储 100byte 的内容,这时候它会选择和它最接近的 chunk ,比如选择了 128byte 大小的,那么就有 28byte 浪费了。
删除机制
memcached 不会释放已经分配的内存。记录超时后,它的空间被重复利用。而它的内部不会监视记录是否过期,而是在记录被 get 时查看是否已经过期,这种方式叫惰性过期。这样可以节省CPU资源。
当空间不足时,memcached 会通过 LRU(least recenty use)机制来分配空间,意思是:最近最少使用的被优先分配出去。
分布式–一致性哈希
memcached 虽然支持分布式的访问,但它本身并不支持,需要我们自己实现相关的分发。常用的算法是取余法。如总共有 10 台服务器,请求过来后,将 key 通过哈希算法进行运算得到整数,并将值和 10 取余,将请求分发给第余数台服务器。
这样带来的问题是,当需要添加或移出一台服务器时,受影响的 key 非常多。每台服务器上都有 key 受影响。
一致性哈希的做法是为了减少受影响的 key。它的方案是:设想有一个圆,上面有 232 个点,我们把这些点均匀的分配给所有的服务器,分配方式就是计算各服务器编号的哈希值,然后进行对应。当有请求过来时,先计算 key 的哈希值并对应到圆上的点,将这个请求分配给离该点最近的服务器。
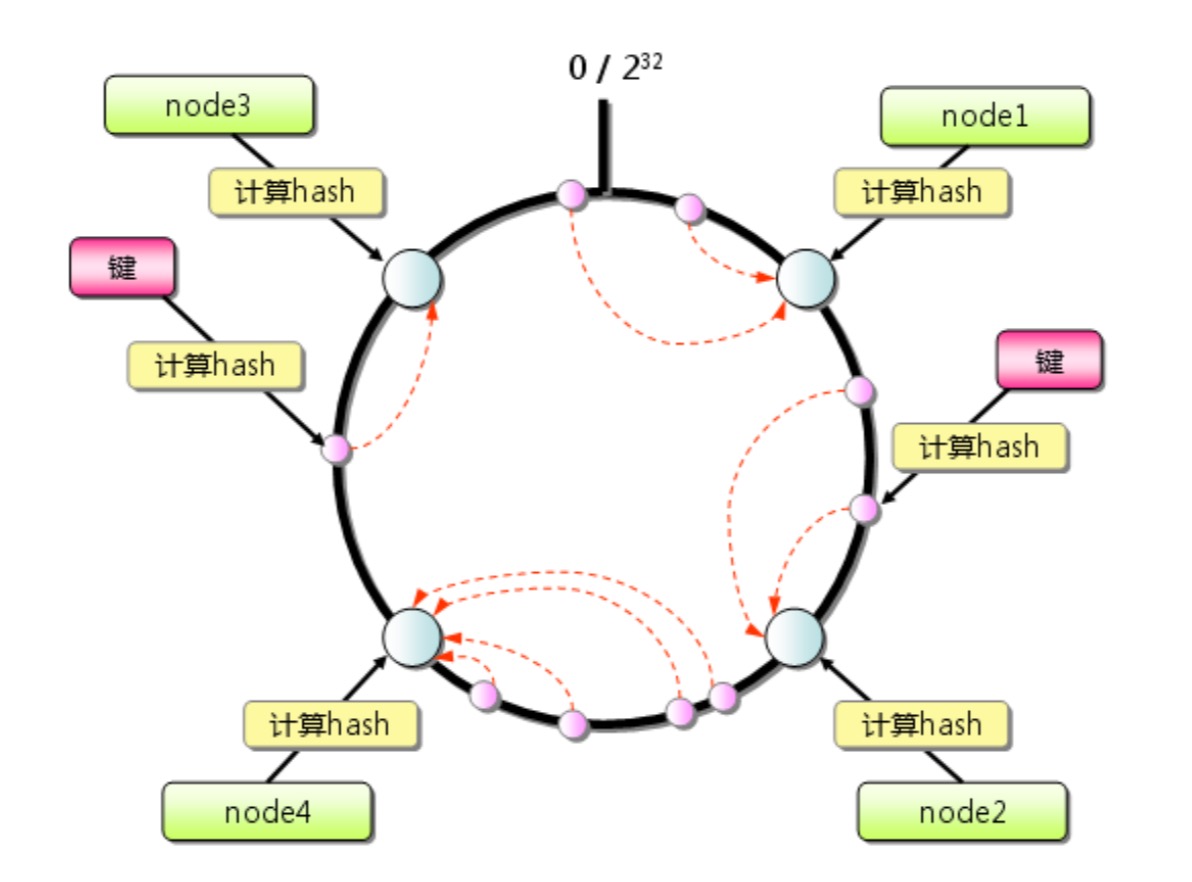
这样,如果要添加或删除节点,受影响的只有在该圆上和该节点最近的那个节点上的 key。

-
贪婪算法/动态规划
贪婪算法/动态规划
有时候,一个问题找不到一种很精确的算法(NP完全问题)。这时候我们想到的是通过局部的最优解,然后把它近似认为是全局最优。这就是贪婪算法。
NP完全问题,通常有一些特性:
- 元素少时,算法运算速度快,但随着元素增多,速度会非常慢。
- 涉及“所有组合”的问题,通常是。如:要找经过几个点的最短路径。
- 不能将问题分成小问题,因为可能的情况太多。
- 如果涉及到序列或集合的问题。或者可以转换成这种形式的问题。
如:快递员要给 20 户人送快递,如何找出经过这 20 户人的最短路径。
和广度优先的方式不同的是,广度优先是肯定了起点和终点,而且不限制必须经过哪些点。而这里不固定起点和终点,但规定必须经过 20 个点。这时候的路线组合方式就太多了。最笨的办法就是尝试各种路线,但速度会非常慢。所以这里可以尝试用贪婪算法。
又如:在你的朋友圈中找出最大的圈子(其中任何两个人都是好友)。这是集合覆盖的问题。
又如:要画一个中国地图,需要用不同的颜色表示出相邻的两个省。需要用多少种颜色才能做到? 这也可以转换为集合覆盖问题。
贪婪算法
教室调度问题
假如有一间教室,有一个课程表安排如下:
课程 开始时间 结束时间 美术 9 am 10 am 英语 9:30 am 10:30 am 数学 10 am 11 am 计算机 10:30 am 11:30 am 音乐 11 am 12 pm 现在希望这间教室能最大化利用。也就是要安排最多的课程。首先,肯定是不能全部安排上的,因为这些课程之间有时间的重叠。所以需要放弃某些课程。
如果用贪婪算法,它的逻辑是这样的:
- 选出最早结束的课程,它作为这间教室的第一堂课
- 选择上一堂课结束后才开始,并结束时间最早的课。
- 重复上面一步选择。
这样,我们找出了这样的组合:美术–>数学–>音乐。我们每一次选择的都是结束时间最早的课程。并不断重复这一过程,相当于将整个问题分解为若干个小问题,然后为每个小问题求最优解。
贪婪算法,每一步都采取最优算法,并假设这样的组合是全局问题的最优解。
集合覆盖问题
现在有一个电视节目。要让全国各省都能接收到。因此,需要决定在哪些电视台播。不同的电视台可以在不同的省份播放(一个台可以覆盖多个省),不同的台收费不一样。现在要求在尽可能收支出的情况下覆盖全国的省。
电台和省的关系可能如下: 北京台:北京、天津、河北、山东。 天津:天津、河北、山西。 山东:山东、山西、河南。 等等(本数据纯属虚构)。
比较笨的办法是:尝试各种不同的电视台组合。然后找出覆盖了全国的,且电视台最少的集合。
但是,如果电视台有 2 个(A 和 B),组合形式有:A, B, AB。如果有 3 个(A,B,C),组合形式有:A, B, C, AB, AC, BC, ABC。相当于有 2n-1 种组合,n 是集合里元素的个数。在这时,有 32 个省。那就有 232-1 种组合,那就是 4 亿多种。显然这种办法不可行。
这种时候我们就可以用贪婪算法,找到近似的解就行了:
- 选一个电台,它覆盖了最多的未覆盖的省。
- 重复上一步骤,直到覆盖所有的省。
代码如下:
// 需要覆盖省的集合 $provinceNeed = array('bj', 'tj', 'hb', 'sd', 'sx', 'hn', 'hub', 'hlj', 'jn', 'ln', 'ah', 'zj', 'gd', 'gx', 'js', 'fj', 'yn', 'nmg', 'shx', 'xz', 'xj', 'gs', 'sc', 'cq', 'qh', 'sh', 'jx'); // asort($provinceNeed); // print_r($provinceNeed); // 电视台及其覆盖的省的集合.为方便测试,假设电视台只覆盖相邻的几个省.只简单写了几个数据 $stations = array(); $stations['bj'] = array('bj', 'tj', 'hb', 'sd', 'nmg'); $stations['hlj'] = array('bj', 'tj', 'hlj', 'jn', 'ln'); $stations['ln'] = array('bj', 'tj', 'hlj', 'jn', 'ln', 'sd'); $stations['tj'] = array('tj', 'hb', 'sx', 'hn'); $stations['sd'] = array('sd', 'sx', 'hn', 'ln', 'js', 'ah', 'zj'); $stations['hb'] = array('hb', 'sd', 'sx', 'hn', 'shx', 'nmg', 'sx', 'ah'); $stations['sx'] = array('sd', 'sx', 'sc', 'nmg', 'xj'); $stations['cq'] = array('sc', 'cq', 'hb', 'gx', 'gd', 'xj'); $stations['xj'] = array('xj', 'xz', 'qh', 'nmg', 'gs'); $stations['hub'] = array('sc', 'hn', 'sh', 'gd', 'yn', 'hub'); $stations['sh'] = array('sh', 'fj', 'sd', 'gd', 'gx', 'js', 'jx', 'zj'); // 最终的电台列表 $finalStation = array(); while (count($provinceNeed) > 0){ // 当前最佳的选择:包含未覆盖省最多的电台 $bestStation = NULL; // 已经覆盖的省的列表 $provonceCovered = array(); // 遍历所有电台.选一个电台,它覆盖了最多的未覆盖的省 foreach ($stations as $province => $provinceStationList) { $covered = array_unique(array_intersect($provinceNeed, $provinceStationList)); if(count($covered) > count($provonceCovered)){ $bestStation = $province; $provonceCovered = $covered; } } $provinceNeed = array_diff($provinceNeed, $provonceCovered); array_push($finalStation, $bestStation); } print_r($finalStation);运行后输出:
Array ( [0] => sh [1] => hb [2] => hlj [3] => xj [4] => hub [5] => cq )可以把答案中的一些电台对应的省改一下,再运行发现结果变了。而且运行速度是很快的。
旅行商问题
一个旅行团的一条路线,需要去 5 个城市。为了节约成本,需要找到通过这 5 个城市的最短路径。起点和终点不固定。
如果只有两个城市 A,B,线路可能有两条:A–>B, B–>A。有时候这两条路线不一样,因为可能存在单行线。如果有三个城市 A,B,C,路线有:A–>B–>C, A–>C–>B, B–>A–>C, B–>C–>A, C–>A–>B, C–>B–>A,共 6 条路线。如果 4 个城市,会有 24 条路线;5 个城市共有 120 条;6 个城市有 720 条;7 个城市 5040 条;8 个城市 40320 条。规律是:L = n!,路线条数是城市数的阶乘。
如果来个欧洲十国游,那…L = 10! = 10 * 9 * 8 * …1 = 3,628,800 条。这时候想每条路线分别计算距离再比较,效率就非常非常低了。
如果用贪婪算法的思想,可行的算法是:
- 随便选择一个城市作为起点。
- 选择一个还没去的城市,离当前城市最近的城市作为下一个点。
- 重复上一步。
动态规划
有一个案例:小偷去偷东西,他只有一个包。要往包里装尽量贵重的物品。要让他偷的物品价值最大化。
最简单的办法就是穷兴趣所有能够偷的物品,找出价值最大的组合。这也是一个集合覆盖的问题。当商品只有 3 件的时候,有 8 种组合。4 件的时候有 16 种组合。组合数和商品数的关系是 C = n2 。如果有 32 件商品,就有 4 亿多种组合了。显然穷举法就不合适了。
如果用贪婪算法。我们的做法是:
- 找到能装入背包的最贵的物品。
- 再装入还可以装入的最贵的物品。
- 重复上一步。
这样可以得到近似解,但不一定是最优解。比如:
背包可以装下 35 斤重的物品。现在有三种商品:音响 30 斤,价值 3000 元;电视 20斤,价值 2000 元;收音机 15 斤,价值 1500 元。
按照贪婪算法的逻辑,先装音响;但这时候装不下其它物品了,这时候价值是 3000 元。但如果装电视和收音机这种组合,则可以让价值达到 3500 元。这是因为装音响的时候浪费了 5 斤的额度。
在这种场景下,我们可以使用动态规划。它的原理是:先解决子问题,然后上升到大问题。
在此例中,包容量是 35 斤。那么,我们先考虑 5 斤的包能装多少价值,然后 10 斤,15 斤,20 斤,25, 30, 35 斤。由于现在商品最轻的就是15斤的,我们直接从 15 斤的开始考虑。列出下面的表格:
商品 15斤 20斤 25斤 30斤 35斤 收音机(R) 电视(T) 音响(H) 该不及格描述的是背包在对应容量下,装对应商品的价值。
对于第一行收音机来说,我们只能选收音机,不管包是 15 斤的还是 35 斤的,最大价值都是 1500 元。这时候表格如下:
商品 15斤 20斤 25斤 30斤 35斤 收音机(R) 1500
R1500
R1500
R1500
R1500
R电视(T) 音响(H) 这个表格表示,如果只偷收音机,35 斤容量的包最多能偷价值 1500 元的东西。 现在开始计算表格的第二行,这时候可以用两种商品的组合:电视+收音机。当容量是 15 斤的时候还是只能选收音机,当容量是 20 斤的时候,开始选电视;25, 30 的时候都是选电视,但 35 的时候,选完电视后,还有 15 斤的容量剩余,这时候查看表前面,15 斤对应的最大价值是 R,所以在 35 的时候可以用 R + T 的组合。这时候是当前情况下的最大价值:
商品 15斤 20斤 25斤 30斤 35斤 收音机(R) 1500
R1500
R1500
R1500
R1500
R电视(T) 1500
R2000
T2000
T2000
T3500
T + R音响(H) 上表说明在两种商品的情况下,35 斤的包最大价值是 3500 元,是收音机+电视的组合。这时候再看三种商品组合的情况:
商品 15斤 20斤 25斤 30斤 35斤 收音机(R) 1500
R1500
R1500
R1500
R1500
R电视(T) 1500
R2000
T2000
T2000
T3500
T + R音响(H) 1500
R2000
T2000
T3000
H3000
H从上表可以看到,当包的容量是 30 斤的时候,音响的价值最大;35 斤的时候,电视+收音机的价值最大。
比如现在再增加一个商品,笔记本,5 斤 价值 5000 元。这时候表信息如下:
商品 5斤 10斤 15斤 20斤 25斤 30斤 35斤 收音机(R) 0 0 1500
R1500
R1500
R1500
R1500
R电视(T) 0 0 1500
R2000
T2000
T2000
T3500
T + R音响(H) 0 0 1500
R2000
T2000
T3000
H3000
H笔记本(B) 5000
B5000
B5000
B6500
B + R7000
B + T7000
B + T8000
B + H在 20 斤的时候,先选了 B,剩下 15 斤容量,这时候再选 15 斤对应的最大值 R,这时候的组合就是 B + R,6500 元。
25 斤的时候,选完 B剩下 20,这时候再选 20 斤对应的最大值,是 T,同理 30 的时候也是。
通过这样从小到大的依次求解,然后把小问题的最优解带到后面的大问题里这样算出大问题的最优解。
测试代码如下:
<?php $bagMax = 35; // 待解析的商品.顺序可以打乱 $goods = array('R', 'T', 'H', 'B'); $weight['R'] = 15; $weight['T'] = 20; $weight['H'] = 30; $weight['B'] = 5; $value['R'] = 1500; $value['T'] = 2000; $value['H'] = 3000; $value['B'] = 5000; $bagList = array(); // 划分背包为各个小包,即表格的列.比如以 5 为区间递减 for ($i = 35; $i > 0; $i -= 5) { array_push($bagList, $i); } asort($bagList); // print_r($bagList); // 双重循环填充表格 $info = array(); // 用来存放不同容量包裹的最大价值及物品及各列的信息.为了方便查询 $maxInfo = array(); foreach ($goods as $loopGoods) { foreach ($bagList as $loopBag) { // 1. 如果刚好能放下当前物品.直接设置当前信息为当前商品 // 2. 如果当前容量放不下当前物品.找当前容量下最大价值的商品.把它作为当前位置的商品信息 // 3. 如果当前容量大于当前商品占位.先把当前商品加上,然后在找剩余重量对应的最大价值商品并加上 // 4. 把当前位置的信息添加到列信息和表格信息中 // 需要查找的额外的商品的信息 $addValue = 0; $addGood = array(); // 基础商品信息 $baseValue = 0; $baseGood = array(); // 要去查找的商品的重量 $toFindWeight = 0; if ($loopBag >= $weight[$loopGoods]) { $toFindWeight = $loopBag - $weight[$loopGoods]; $baseValue = $value[$loopGoods]; array_push($baseGood, $loopGoods); } else { $toFindWeight = $loopBag; } // 去找附加商品的信息 if ($toFindWeight > 0 && array_key_exists($toFindWeight, $maxInfo)) { foreach ($maxInfo[$toFindWeight] as $maxgood => $maxgoodinfo) { $loopValue = $maxgoodinfo['value']; $loopGood = $maxgoodinfo['goods']; // 和当前商品相同的不添加.意思是一个格子里不能添加两个相同的商品 if ($maxgood == $loopGoods) { continue; } // 找到价值最大的商品 if ($loopValue > $addValue) { $addValue = $loopValue; $addGood = $loopGood; } } } // 设置表格信息和列信息 $info[$loopGoods][$loopBag]['value'] = $baseValue + $addValue; $info[$loopGoods][$loopBag]['goods'] = array_merge($baseGood, $addGood); $maxInfo[$loopBag][$loopGoods]['value'] = $info[$loopGoods][$loopBag]['value']; $maxInfo[$loopBag][$loopGoods]['goods'] = $info[$loopGoods][$loopBag]['goods']; } } foreach ($info as $good => $bagList) { print_r($good . ' '); foreach ($bagList as $weight => $bag) { print_r($bag['value'] . ' : ' . implode(' + ', $bag['goods']) . ' '); } print_r(PHP_EOL); } ?>运行后输出:
R 0 : 0 : 1500 : R 1500 : R 1500 : R 1500 : R 1500 : R T 0 : 0 : 1500 : R 2000 : T 2000 : T 2000 : T 3500 : T + R H 0 : 0 : 1500 : R 2000 : T 2000 : T 3000 : H 3000 : H B 5000 : B 5000 : B 5000 : B 6500 : B + R 7000 : B + T 7000 : B + T 8000 : B + H最长公共子串
动态规划的原则是将大问题分解为若干个小问题,求出各小问题的最优解。
一个字典应用,如果用户输入了 hish,他有可能输错了。那么,他是想输入 fish 还是 vista 呢?
我们可以根据 hish 和 fish 以及 hish 和 vista 的相似度来推测是谁。相似度的衡量又可以通过最长公共子串来比较。我们可以通过图示来表示:
h i s h f 0 0 0 0 i 0 1 0 0 s 0 0 2 0 h 1 0 0 3 它的比较方式是:行和列的各个字母相比较。如果不同,把当前位置设为 0;如果相同,值为当前位置左上角的值+1。
最后表格中的最大值就是最大公共子串。在这里是 3。同样,我们可以比较 hish 和 vista ,得到的值是 2。它的值没有 fish 的值大,所以我们认为他输入的值应该是 fish。
最长公共子序列
如果用户输入了 fosh,他有可能输入的是 fish 或 fort。通过最长公共子串的计算方式,得到这两个单词和 fish 相比较公共子串的长度都是 2。但实际上,fosh 和 fish 有三个字母一样,和 fort 只有两个,所以 fish 的相似度要更高一些。这里长度 3 指的就是两者的最长公共子序列。
它的计算方式也是用表格的方式,但计算逻辑不一样:行和列的字母分别比较。如果两者不同,就选择上方和左侧邻居中较大的那个作为当前值。如果相同,当前的值是左上方单元格的值+1。
如:
f o s h f 1 1 1 1 i 1 1 1 1 s 1 1 2 2 h 1 1 2 3 最长公共子序列的最大值是表格最右下方表格的值。